Ant、Maven這兩個好用工具的廣受歡迎,有人點出是它們能夠利用檔案設定方式將專案進行中的瑣碎行為定義標準,在需要進行那件事的時候任何人只要執行它就可以得到完全一樣的結果。這種方式與將每個時間點要作的事記錄成SOP要求遵照進行比較,除了必須先行瞭解新的工具用法之外,帶來的卻是便利與穩定等強大好處。
當事情可以用人或電腦來處理時,不同人、不同時間的同樣操作都有較高的錯誤與不一致機率,這些問題在利用電腦處理時可以大幅降低,只需要花一次時間精確地定義出處理的詳細規則;觀察許多工具其原始目的大致如此。Ant對於單一事件(通常是build版本)定義出詳細的處理過程,而Maven更進一步地定義出專案管理中的幾個階段,再整合其他工具、加上與程式碼相關的物件(library、testing、reporting……等),建構起一個能夠調校的自動管理系統。
收集軟體專案開發必須要做的事,定義出每個軟體專案能通用的開發流程、階段與當時可以做的事,同時允許使用者設定使用一般常用的方便工具,得到適用的客製化結果。當工具符合專案大部分的自動化需求時,即使需要額外投入學習的時間還是會加以運用。
回到自己部落格的內容,現在記錄的資料只是根據過去的零碎的經驗值推想一些改進的方法,沒有全面的整理與比較根本說不出這麼做的最終目的。此時的思緒已經逐漸清楚,明白自己是想定義用程式碼製作出來的全部事與物都有完全一致的型式與規則。如果像專案開發階段這樣令人感覺抽象且發散的事都能夠依賴設定之物來運作,試圖將程式碼轉化為某種特別的設定來驅動更豐富的自動化解析也應該是可以達成的。
這,正是我想逐步實現的理想。
2009年12月29日 星期二
2009年12月24日 星期四
X12 精確地拆解、完全地對應(4)──記錄的內容
從寫計畫書時的拆解目標到記錄安裝手冊的步驟,最近感覺慢慢地開始喜歡撰寫文件。主要因為發現無論是目標的拆解或是一堆軟體的安裝,都是將許許多多的物與關聯運用平鋪直敍的方式來記錄;套用將人視為電腦的觀念,就像在制訂匯出的規範(決定匯出的順序與內容),讓匯出的資訊進到任何一個人都可以還原前人腦中的想法。
●第一個考慮的是全部的範圍。根據需要安裝的軟體、需要的環境設定、專案的參數定義與需要完成的特定事件來思考並加以歸類;未來每一個項目都要製作對應文件說明。在這裡可以想像是Use Case的定義與群組化,再加上循序漸進地順序佈置以建構閱讀者對整個平台的瞭解。
●對於每一個說明點的內容,意義上與用文字敍述的功能劇本差不了多少。準備的檔案與起始狀態、每一個步驟的忠實記錄並佐以圖檔、每一步驟後的狀態檢查、還有最後完成的狀態與驗證,都是需要記載於文件的內容。其中若有小目的需要用多個步驟才能完成,應加以群組起來說明較為清楚(很像是寫程式時將多行群組為一個方法)。
●有時會需要兩層式的文件才能說明一件事。例如建置一個Maven專案的流程要在Eclipse上新建Maven專案、設定subversion儲存庫再share project,倘使流程文件直接記錄每個步驟,就會發生其他流程要使用設定subversion儲存庫這個步驟的說明時,不知是要參照其中的步驟(只參考流程的一部分)還是自己建立新的說明(重覆的資料)好。我的解法是每個步驟都拆到對應軟體的操作手冊裡,再從流程內容參照過去;整個流程需要輸入的資料則記錄在流程文件裡,畢竟那是該流程特有的內容。
在移交開發平台的過程中,曾經為了兩個沒有記錄到的小步驟,用了一個工作天才感覺似乎少了些什麼,一天之後才確認真的有缺少。記錄兩個小步驟只是幾分鐘的時間,但是可以省下不應花費的一天;用這個例子提醒自己撰寫文件的價值與影響,自然會時常懷著戒慎恐懼的心態力求完整。
●第一個考慮的是全部的範圍。根據需要安裝的軟體、需要的環境設定、專案的參數定義與需要完成的特定事件來思考並加以歸類;未來每一個項目都要製作對應文件說明。在這裡可以想像是Use Case的定義與群組化,再加上循序漸進地順序佈置以建構閱讀者對整個平台的瞭解。
●對於每一個說明點的內容,意義上與用文字敍述的功能劇本差不了多少。準備的檔案與起始狀態、每一個步驟的忠實記錄並佐以圖檔、每一步驟後的狀態檢查、還有最後完成的狀態與驗證,都是需要記載於文件的內容。其中若有小目的需要用多個步驟才能完成,應加以群組起來說明較為清楚(很像是寫程式時將多行群組為一個方法)。
●有時會需要兩層式的文件才能說明一件事。例如建置一個Maven專案的流程要在Eclipse上新建Maven專案、設定subversion儲存庫再share project,倘使流程文件直接記錄每個步驟,就會發生其他流程要使用設定subversion儲存庫這個步驟的說明時,不知是要參照其中的步驟(只參考流程的一部分)還是自己建立新的說明(重覆的資料)好。我的解法是每個步驟都拆到對應軟體的操作手冊裡,再從流程內容參照過去;整個流程需要輸入的資料則記錄在流程文件裡,畢竟那是該流程特有的內容。
在移交開發平台的過程中,曾經為了兩個沒有記錄到的小步驟,用了一個工作天才感覺似乎少了些什麼,一天之後才確認真的有缺少。記錄兩個小步驟只是幾分鐘的時間,但是可以省下不應花費的一天;用這個例子提醒自己撰寫文件的價值與影響,自然會時常懷著戒慎恐懼的心態力求完整。
2009年12月15日 星期二
X11 精確地拆解、完全地對應(3)──經驗的留存
先讓別人明白為什麼要做這些事之後,接著要讓別人知道為什麼會有那些物。將焦點放在搭配工具的那一欄:所有使用工具的聯集就是開發平台上應該安裝的全部。開發平台會分為Client端與Server端,專案起始的環境建置應同時準備好這些。前面提到的安裝文件就是描述整個平台從無到有的建置過程。
從使用者的觀點來看,並不需要知道開發平台是怎麼樣被建置起來的,只要提供一個能讓他們根據規定流程做事的東西即可。然而從管理面來看,如果設定需要調整要怎麼做?如果某個工具損壞了要怎麼安裝?如果某些工具有升級版要怎麼做?……用許多可能會發生的”如果”來檢視沒有完整說明的產出,就會發現根本不知從哪裡著手。
最近看了一些不錯的文章都有提到知識管理的重要性(高績效研發管理實務運作/李紹榮、研發人員常見問題之剖析與探討/吳英秦),這幾年我也體認到經驗的保存是很重要的事。為了特定目的如何定義需要的物、做哪些事可以得到那些物、怎麼設定能讓那些物具備功能、怎麼使用那些物可以達到我們要的目的,每一個想法與實現都忠實地記錄並收集起來,就能讓原先沒有參與的人很快地建構起與自己相近的觀念與成果。
這個開發平台現在連我在內一共有三個人完整安裝過,但是每個人都花了不少時間去詢問與搜索,像我就在網路設定上花費一整天才弄妥。做出一個完整的開發平台需要做很多的動作才能達成,我偶而會想:倘使幾個月後需要三個人根據自己手邊的記錄重灌一次的話,我們各自會花多少時間?如果各自找一位其他的工程師看著留下的資料重做的話,又需要多久?會問多少個問題呢?
有些道路是經過多次的摸索與碰壁後才發現到的最佳捷徑,沒法留下快速通往終點的記錄只會讓日後想走同樣路的人重覆花費摸索與碰壁的時間,如果那條路需要多人次的進行時更是重覆地浪費資源。留下足以讓後人快速達到終點的作法,可說是犧牲自己時間換取節省眾人時間的一種高尚行為──這是近來瀏覽其他人在網路上提供安裝設定方式與心得時,我心中所懷的敬意。
從使用者的觀點來看,並不需要知道開發平台是怎麼樣被建置起來的,只要提供一個能讓他們根據規定流程做事的東西即可。然而從管理面來看,如果設定需要調整要怎麼做?如果某個工具損壞了要怎麼安裝?如果某些工具有升級版要怎麼做?……用許多可能會發生的”如果”來檢視沒有完整說明的產出,就會發現根本不知從哪裡著手。
最近看了一些不錯的文章都有提到知識管理的重要性(高績效研發管理實務運作/李紹榮、研發人員常見問題之剖析與探討/吳英秦),這幾年我也體認到經驗的保存是很重要的事。為了特定目的如何定義需要的物、做哪些事可以得到那些物、怎麼設定能讓那些物具備功能、怎麼使用那些物可以達到我們要的目的,每一個想法與實現都忠實地記錄並收集起來,就能讓原先沒有參與的人很快地建構起與自己相近的觀念與成果。
這個開發平台現在連我在內一共有三個人完整安裝過,但是每個人都花了不少時間去詢問與搜索,像我就在網路設定上花費一整天才弄妥。做出一個完整的開發平台需要做很多的動作才能達成,我偶而會想:倘使幾個月後需要三個人根據自己手邊的記錄重灌一次的話,我們各自會花多少時間?如果各自找一位其他的工程師看著留下的資料重做的話,又需要多久?會問多少個問題呢?
有些道路是經過多次的摸索與碰壁後才發現到的最佳捷徑,沒法留下快速通往終點的記錄只會讓日後想走同樣路的人重覆花費摸索與碰壁的時間,如果那條路需要多人次的進行時更是重覆地浪費資源。留下足以讓後人快速達到終點的作法,可說是犧牲自己時間換取節省眾人時間的一種高尚行為──這是近來瀏覽其他人在網路上提供安裝設定方式與心得時,我心中所懷的敬意。
2009年12月14日 星期一
X10 精確地拆解、完全地對應(2)──目標的解析
認為現有的文件寫得不理想時,總得說出比較理想的寫法才算是建設性的意見。依據前面同事留下來的資料重新安裝Java Power Tool中提到的工具時,一邊問他們當初沒有記錄下來的部分、一邊思索要用什麼樣的方式表達才能讓其他人全面地明瞭所做的一切,並且可以製作出同樣的結果。
今年撰寫的那份計畫書其實也是沒人想寫的那種,不過在構思的期間與大主管們有過多次的討論,學習開始去切割目標為多個小目標,再對每個小目標定義要做些什麼、要怎麼做等等的想法。我們認同程式碼品質這個無法直接度量的目標,可以用程式員日常工作的規範來間接證明,所以先列出程式員所有“與程式碼相關“的行為,根據每個程式員的行為定義相關的動作,再思考每個動作是否有適當的工具搭配以及操作的必要規範。

註:這只是大致上的示意圖,還不是完整的定義與對應。
這張圖是根據“程式碼品質”這個目標延展出來的四個群組:專案事件、程式員做的事、搭配工具與定義的規範,其間的每個項目都與緊鄰群組中的項目產生關聯。以往討論程式碼品質時都僅能就幾個點提出建議,但是參考Java Power Tool的內容卻可以就完整的面來探討:從專案與程式員個人事件發生的起點開始展開處理的流程與要做的動作,並針對每個動作找出最適合的工具來加快處理速度並減少錯誤,一步步使用規定的工具做完應做的事同時讓所有產出都通過檢查且符合規範。
針對一個較大的目標,完整地定義出點、線、面來全面涵括相關的事物,不是更容易規範出大多數人都能接受的標準嗎?
今年撰寫的那份計畫書其實也是沒人想寫的那種,不過在構思的期間與大主管們有過多次的討論,學習開始去切割目標為多個小目標,再對每個小目標定義要做些什麼、要怎麼做等等的想法。我們認同程式碼品質這個無法直接度量的目標,可以用程式員日常工作的規範來間接證明,所以先列出程式員所有“與程式碼相關“的行為,根據每個程式員的行為定義相關的動作,再思考每個動作是否有適當的工具搭配以及操作的必要規範。

註:這只是大致上的示意圖,還不是完整的定義與對應。
這張圖是根據“程式碼品質”這個目標延展出來的四個群組:專案事件、程式員做的事、搭配工具與定義的規範,其間的每個項目都與緊鄰群組中的項目產生關聯。以往討論程式碼品質時都僅能就幾個點提出建議,但是參考Java Power Tool的內容卻可以就完整的面來探討:從專案與程式員個人事件發生的起點開始展開處理的流程與要做的動作,並針對每個動作找出最適合的工具來加快處理速度並減少錯誤,一步步使用規定的工具做完應做的事同時讓所有產出都通過檢查且符合規範。
針對一個較大的目標,完整地定義出點、線、面來全面涵括相關的事物,不是更容易規範出大多數人都能接受的標準嗎?
2009年12月11日 星期五
X09 精確地拆解、完全地對應(1)──遇到的現象
公司前陣子陸續驗收了幾個專案,主管利用可喘息的空檔重新思考如何確保程式碼的品質。品質,無法直接以數據衡量其好壞,因而參考Java Power Tools這本書中的工具與作法,同時決定沿用同事已經先行研究一陣子的產出再擴展下去。
同事的作法是使用虛擬機器安裝Ubuntu作業系統後加上需要的應用程式,雖然他同樣參考過那本書,但僅是在虛擬機器上裝好書上提到的軟體。我們拿到虛擬機器映像檔時真的是有點愣住,因為根本不知道軟體安裝的順序、方法與設定(他的說法是使用者只要有能用的東西就好,不用管怎麼安裝的),也不知道Programmer日常工作要在什麼時機、用什麼樣的方式來運用各個軟體(他有說了大概,但是沒有確實的工作流程)。
那時我還在別的專案忙著,主管先找了其他同事來幫忙弄清楚虛擬機器上的每個環節,同時希望他們能定義每個工具使用時的規範(例如Subversion在commit時說明的範本),當時也言明在完成後會由我根據產出的文件從頭到尾重做一次來檢驗結果。但是這幾天自己下去重頭做時才發現記錄的內容感覺很不齊全,很多地方不知道從哪裡開始、不確定要做些什麼、不知道做了之後改變了什麼。
工程師(指我遇到過的以及我自己)撰寫使用手冊與教學文件的產出普遍不理想,主要原因是對於撰寫這些文件的態度為“把自己完全清楚的東西全部寫一遍,只是浪費做其他事情的時間而已”,於是就以自己的角度思考寫出能回憶到的部分。在很多時候就因撰寫者與使用者的程度與觀念落差造成無效的文件。
同事的作法是使用虛擬機器安裝Ubuntu作業系統後加上需要的應用程式,雖然他同樣參考過那本書,但僅是在虛擬機器上裝好書上提到的軟體。我們拿到虛擬機器映像檔時真的是有點愣住,因為根本不知道軟體安裝的順序、方法與設定(他的說法是使用者只要有能用的東西就好,不用管怎麼安裝的),也不知道Programmer日常工作要在什麼時機、用什麼樣的方式來運用各個軟體(他有說了大概,但是沒有確實的工作流程)。
那時我還在別的專案忙著,主管先找了其他同事來幫忙弄清楚虛擬機器上的每個環節,同時希望他們能定義每個工具使用時的規範(例如Subversion在commit時說明的範本),當時也言明在完成後會由我根據產出的文件從頭到尾重做一次來檢驗結果。但是這幾天自己下去重頭做時才發現記錄的內容感覺很不齊全,很多地方不知道從哪裡開始、不確定要做些什麼、不知道做了之後改變了什麼。
工程師(指我遇到過的以及我自己)撰寫使用手冊與教學文件的產出普遍不理想,主要原因是對於撰寫這些文件的態度為“把自己完全清楚的東西全部寫一遍,只是浪費做其他事情的時間而已”,於是就以自己的角度思考寫出能回憶到的部分。在很多時候就因撰寫者與使用者的程度與觀念落差造成無效的文件。
2009年11月19日 星期四
Y09 關於共用核心元件(Core Component Library)
在因緣際會之下參加了經濟部標準檢驗局舉辦的Core Component Library(簡稱UN/CCL)座談會,才知道聯合國UNCEFACT已經提供一套方法,針對企業間電子商務行為關係將彼此的交易流程以共同同意之方式、順序及訊息格式進行整合。其範圍涵蓋了各行各業非常多的商業資訊物件,在最近的09A版本已經定義了五千多種。
UN/CCL主要的目的在於各國、各系統間的資料交換,翻閱過08A的中譯資料發現已經定義了許多曾經使用過的資料。席間有人發問說資訊物件內的欄位並沒有定義長度,學者回答資料若定義長度在語系轉換時會發生長度計算的問題,不過我認為資料在使用的意義上並沒有長度的規範,而是系統設計時因應儲存限制才加以規定的。
然而UN/CCL只是該組織計畫一部分,資料的定義用ebXML來描述,Business Process與Information Model會有UMM方法論,相對地這也是範圍更大、更難定義的部分。根據簡報的陳述,倘使各國的菁英最後能夠定義出絕大部分的商業流程與其對應使用的商業資訊物件,未來的電子商務相關系統開發模式很可能是:
●定義使用系統的所有Actor
●定義每個Actor所使用的Business Use Case(從清單中勾選)
●定義每個Business Use Case裡所需要的Business Process(從清單中勾選)
●定義Business Use Case裡的Business Process執行順序
●定義Business Process對應的CCL資料物件中的使用資料欄位(從清單中勾選)
●底層的架構會根據勾選的資料物件欄位產出ebXML傳送到另一端的系統
這個組織已經運作好幾年,但是以“Core Component Library”搜尋中文網頁時所得的資訊並不多。從另一個方面來看,自己定義的“人-事-物”關係能夠接近許多專家定義的“Actor-Business Process-Core Bomponent Library”精神時,總是對自我更多了幾分認同。
官方公佈UN/CCL版本的網址是 http://www.unece.org/cefact/codesfortrade/unccl/CCL_index.htm。
UN/CCL主要的目的在於各國、各系統間的資料交換,翻閱過08A的中譯資料發現已經定義了許多曾經使用過的資料。席間有人發問說資訊物件內的欄位並沒有定義長度,學者回答資料若定義長度在語系轉換時會發生長度計算的問題,不過我認為資料在使用的意義上並沒有長度的規範,而是系統設計時因應儲存限制才加以規定的。
然而UN/CCL只是該組織計畫一部分,資料的定義用ebXML來描述,Business Process與Information Model會有UMM方法論,相對地這也是範圍更大、更難定義的部分。根據簡報的陳述,倘使各國的菁英最後能夠定義出絕大部分的商業流程與其對應使用的商業資訊物件,未來的電子商務相關系統開發模式很可能是:
●定義使用系統的所有Actor
●定義每個Actor所使用的Business Use Case(從清單中勾選)
●定義每個Business Use Case裡所需要的Business Process(從清單中勾選)
●定義Business Use Case裡的Business Process執行順序
●定義Business Process對應的CCL資料物件中的使用資料欄位(從清單中勾選)
●底層的架構會根據勾選的資料物件欄位產出ebXML傳送到另一端的系統
這個組織已經運作好幾年,但是以“Core Component Library”搜尋中文網頁時所得的資訊並不多。從另一個方面來看,自己定義的“人-事-物”關係能夠接近許多專家定義的“Actor-Business Process-Core Bomponent Library”精神時,總是對自我更多了幾分認同。
官方公佈UN/CCL版本的網址是 http://www.unece.org/cefact/codesfortrade/unccl/CCL_index.htm。
2009年11月10日 星期二
X08 批評學生不敬業的事件
原始網頁:http://parenting.cw.com.tw/web/docDetail.do?docId=1844
學生回應:http://www.udn.com/2009/11/10/NEWS/OPINION/X1/5242253.shtml
聯合新聞網上刊登了這個事件,洪蘭小姐在訪視台大醫學院時對學生們上課表現出來的態度不以為然,在天下雜誌發表「不想讀,就讓給別人吧」一文,對此事件,台大醫學系系學會會長在新聞網的專題裡回應了一篇文章說明。我當然不懂學醫的人求學時會發生什麼事,不過我對每個人在不同情境下的思考邏輯很有興趣,所以順便探索一下。
洪蘭小姐的立場很簡單,她認為在求學時期應該對所有學校相關的事(包括與求學無關的)都應抱持負責的態度,更何況那是上課時間;學生的回應也很簡單,表面上承認態度的確有所不當,不過那些都是因為有更正當的理由才會造成那些現象的發生,如果在專業方面能有所表現的話應能體諒其他不拘小節的行為。
在許多人的觀念裡資訊人員是不拘小節的族群,以往的我就是落在這個集合裡,認為只要我能夠完成公司交付的所有任務就算是達成工作目標,平時上班穿著牛仔褲、涼鞋也不以為意。十年前應徵現在的工作被錄取時,詢問上班應該如何穿著,那時的J主管說:“你希望別人怎麼看你就怎麼穿”。從那天起,我每天都穿著長袖襯衫、西裝褲與皮鞋,因為我認同穿著可以反應出一個人的內心。我們在開會因為都帶著電腦,有時總會分心做些與當時會議無關的事,J主管有次生氣地說:“我放下手邊的工作專心地與各位開會,如果大家沒法付出與我相等的專心,我現在就離開“,自此之後我也不曾在會議上別其他事情。
我沒法認同學生的辯詞,因為我體認到在不同的情境下人都應該做該情境下應做的事,每個情境都是獨立存在的,不該拿其他情境的影響來解釋現在的錯誤。上課是學生與老師的互動,老師全心講課時,下面的學生付出了多少?相對地學生想來認真聽課時,敷衍的老師同樣對不起學生。上課會打瞌睡只是證明睡眠真的不夠,如果睡得夠的話看到看過的電影會拿起別的書來看;上課會吃便當只是證明不想犧牲吃的享受,如果時間真的不夠會寧願買個飯糰在休息時間隨便吃吃也不會想在課堂上分心。
在上課的態度不佳是事實,沒去承諾去努力改善這個現象,卻試圖用所有學生的“全”讓那些學生成為“偏”、用專業課程為重的“全”讓通識課程成為不重要的“偏”。一個小故事裡的壽司師傅在捏了上千個壽司後已經累了,仍同樣專心地製作壽司給關門前最後一位不重要的客人吃,旁邊的師傅說你已經很累了不如隨便應付一下,他正色道:“這個壽司只是我今天所做的千分之一,但對這位客人來說卻是他的全部。如果隨便做做,客人就會認為我做的壽司就是這麼爛!”
在想要合理解釋自己有問題的行為前,是否思考過洪蘭小姐所訪視的那一堂課就是她所看到的全部呢?
註:在電子工廠上班的朋友說,每批產品都會抽檢一定比例的樣品,只要其中一個有任何一個錯誤就會將整批產品重新作測試。每個人都可以決定要用什麼樣的標準來檢視自己!
學生回應:http://www.udn.com/2009/11/10/NEWS/OPINION/X1/5242253.shtml
聯合新聞網上刊登了這個事件,洪蘭小姐在訪視台大醫學院時對學生們上課表現出來的態度不以為然,在天下雜誌發表「不想讀,就讓給別人吧」一文,對此事件,台大醫學系系學會會長在新聞網的專題裡回應了一篇文章說明。我當然不懂學醫的人求學時會發生什麼事,不過我對每個人在不同情境下的思考邏輯很有興趣,所以順便探索一下。
洪蘭小姐的立場很簡單,她認為在求學時期應該對所有學校相關的事(包括與求學無關的)都應抱持負責的態度,更何況那是上課時間;學生的回應也很簡單,表面上承認態度的確有所不當,不過那些都是因為有更正當的理由才會造成那些現象的發生,如果在專業方面能有所表現的話應能體諒其他不拘小節的行為。
在許多人的觀念裡資訊人員是不拘小節的族群,以往的我就是落在這個集合裡,認為只要我能夠完成公司交付的所有任務就算是達成工作目標,平時上班穿著牛仔褲、涼鞋也不以為意。十年前應徵現在的工作被錄取時,詢問上班應該如何穿著,那時的J主管說:“你希望別人怎麼看你就怎麼穿”。從那天起,我每天都穿著長袖襯衫、西裝褲與皮鞋,因為我認同穿著可以反應出一個人的內心。我們在開會因為都帶著電腦,有時總會分心做些與當時會議無關的事,J主管有次生氣地說:“我放下手邊的工作專心地與各位開會,如果大家沒法付出與我相等的專心,我現在就離開“,自此之後我也不曾在會議上別其他事情。
我沒法認同學生的辯詞,因為我體認到在不同的情境下人都應該做該情境下應做的事,每個情境都是獨立存在的,不該拿其他情境的影響來解釋現在的錯誤。上課是學生與老師的互動,老師全心講課時,下面的學生付出了多少?相對地學生想來認真聽課時,敷衍的老師同樣對不起學生。上課會打瞌睡只是證明睡眠真的不夠,如果睡得夠的話看到看過的電影會拿起別的書來看;上課會吃便當只是證明不想犧牲吃的享受,如果時間真的不夠會寧願買個飯糰在休息時間隨便吃吃也不會想在課堂上分心。
在上課的態度不佳是事實,沒去承諾去努力改善這個現象,卻試圖用所有學生的“全”讓那些學生成為“偏”、用專業課程為重的“全”讓通識課程成為不重要的“偏”。一個小故事裡的壽司師傅在捏了上千個壽司後已經累了,仍同樣專心地製作壽司給關門前最後一位不重要的客人吃,旁邊的師傅說你已經很累了不如隨便應付一下,他正色道:“這個壽司只是我今天所做的千分之一,但對這位客人來說卻是他的全部。如果隨便做做,客人就會認為我做的壽司就是這麼爛!”
在想要合理解釋自己有問題的行為前,是否思考過洪蘭小姐所訪視的那一堂課就是她所看到的全部呢?
註:在電子工廠上班的朋友說,每批產品都會抽檢一定比例的樣品,只要其中一個有任何一個錯誤就會將整批產品重新作測試。每個人都可以決定要用什麼樣的標準來檢視自己!
2009年10月30日 星期五
Z03 振聾發聵的文章──別把專家當笨蛋(3)
小朋友有天說出他被學校的同學在部落格上攻擊,我們發現對方的文章裡盡是刻薄的字眼。把小朋友叫來詳細詢問事情經過,他起初描述是因為小事有誤會造成的,但是根據小朋友的習性抽絲剝繭後才發現他的行為也不恰當。與老師溝通時,我們傾向於說小朋友目前還是學習階段都難免有錯,請老師教導他們對錯觀念再修正即可;不過老師透露當初看到那些文章時,倒很擔心雙方的家長會在學校鬧出風波。
有些人完全不想學UML,但是在認定UML無用的同時卻無法做出大多數人看得懂的文件;很明顯地這是因為心裡沒將製作文件視為自己該做的事,因而不想要任何對應的處理工具。各類的文件在系統開發階段中一直要求得具備,倘使心裡認定撰寫文件是浪費自己的時間,自然不會在意文件對於其他人與日後自己的影響。要讓一個人願意學UML必須要先讓他認定撰寫文件是必須做的,要能接受撰寫文件是必要的得瞭解文件在各個開發階段的應用,要是心裡打一開始就認定開發方法論無效,就跟之前的我一樣什麼都不用再談了。
“主觀”是個殺傷力很強的念頭,可以將小朋友間的爭執鬧到上法院,可以讓自己變成別人眼中的老頑固,也可以將旁人的心血說得一文不值。同樣是一個人,為什麼從小到大的立場會如此轉變?為什麼會從天真瀾漫變為結黨營私?為什麼在互動頻繁的人類社會裡能夠變得自我中心?不是心理專長的我當然沒有答案,不過我至少發現了一把可以改變自己想法的鑰匙。
人們總是習慣從自己的角度看待事物,唯有學習從不同人的角度重新審視原先熟稔的事物,才有機會突破自己預先設下的侷限,重新顯現出不同的格局。將自己放低後,其他人的經驗與知識自然開始源源不絕地流入,收集眾多的資源後就比較容易分析比較各項優劣。我已經相信這個道理並且開始實行,至於你相不相信?都是你個人的選擇。
2009年10月29日 星期四
Z02 振聾發聵的文章──別把專家當笨蛋(2)
小時候遇到各種新的或不同的事物,總會很有興趣地去學、去瞭解,甚至還會提出一些新奇的想法來嘗試;沒想到這樣的熱忱於長大後卻大多演變為“我不需要”或“看起來沒用”的回應。小朋友前幾天對我說:“為什麼要學勾股定理?根本用不到嘛!”當時我心頭一震,彷彿看到在學校與工作時抵抗著其他知識的自己。我回答說:“學一些知識是讓自己擁有這個能力,未來要從事更高深的科學研究時就有機會用到;當然也有可能用不到,但是需要的時候沒有就是你自己的痛苦。”
同樣地,專家提供根據他們領域知識的精華,根據專家整理過的資訊能夠快速地提升自己的水平;要從一份整理資料裡去蕪存菁地擷取有用的經驗,還是要因為一些蕪而廢棄菁地整個丟棄都是自己的選擇。以往對一件事物習慣去看旁人對它的評論就吸收為自己的看法,藉此來決定是要接受還是抵抗,如今學會反問自己:“我完全瞭解它的意義嗎?能明確說出它的全部優缺點嗎?”,想要有明確而完整的答案,就非得親自去體會不可。
之前與年紀較大的同仁打交道時,總感覺他們的想法非常固執、極難溝通,現在的自己慢慢地朝高齡化發展,卻漸漸發現排斥其他想法與知識的行為與他們類似。似乎具有一種心態,認為某些事自己已經擁有很多的經驗值,如果別人隨隨便便提出幾句話就改變自己,會是很沒有面子的事,所以面對可能的改變時不是消極地掩耳盜鈴當作不知道,就是想出許多藉口來說服自己新的想法並沒有現在心裡面的好。
回憶自己的過去,故步自封的確是因為自己太有自信去控制一切,也就是過於輕視眼前的領域,不想接受其他不同的思維所造成。學歷可以無用,像在大學時我根本蹺課到等於沒去上課,現在的工作目標照樣可以用自己的方式達成;但是要能有良好的做事方法與產出內容,如今相信真的需要先參考專家們的經驗,再調校為適合自己實行的模式才會有機會更上一層樓。
同樣地,專家提供根據他們領域知識的精華,根據專家整理過的資訊能夠快速地提升自己的水平;要從一份整理資料裡去蕪存菁地擷取有用的經驗,還是要因為一些蕪而廢棄菁地整個丟棄都是自己的選擇。以往對一件事物習慣去看旁人對它的評論就吸收為自己的看法,藉此來決定是要接受還是抵抗,如今學會反問自己:“我完全瞭解它的意義嗎?能明確說出它的全部優缺點嗎?”,想要有明確而完整的答案,就非得親自去體會不可。
之前與年紀較大的同仁打交道時,總感覺他們的想法非常固執、極難溝通,現在的自己慢慢地朝高齡化發展,卻漸漸發現排斥其他想法與知識的行為與他們類似。似乎具有一種心態,認為某些事自己已經擁有很多的經驗值,如果別人隨隨便便提出幾句話就改變自己,會是很沒有面子的事,所以面對可能的改變時不是消極地掩耳盜鈴當作不知道,就是想出許多藉口來說服自己新的想法並沒有現在心裡面的好。
回憶自己的過去,故步自封的確是因為自己太有自信去控制一切,也就是過於輕視眼前的領域,不想接受其他不同的思維所造成。學歷可以無用,像在大學時我根本蹺課到等於沒去上課,現在的工作目標照樣可以用自己的方式達成;但是要能有良好的做事方法與產出內容,如今相信真的需要先參考專家們的經驗,再調校為適合自己實行的模式才會有機會更上一層樓。
2009年10月28日 星期三
Z01 振聾發聵的文章──別把專家當笨蛋(1)
原始網頁:http://www.ithome.com.tw/itadm/article.php?c=57685
是否曾經有過這樣的經驗?有一個東西在身邊已經存在很久卻一直沒有什麼感覺,等到某天的一個場合再看到它或是某件與它相關的東西,心裡頭各式各樣的想法就不自禁地流動起來,翻騰到最後定型下來卻是另外一個層次的感動。我提到的那個東西並不是女友或妻子(雖然很像是),而是E主管堆在我桌上的一疊書,這篇文章就是引發我不同觀念的催化劑。
Sun的OO-226課程是我接觸OOAD的最初,開始時隱隱覺得這是很不錯的設計作法,但是實際應用在開發時卻有很多無法串連起來的缺漏;累積幾年的經驗後試著以其為藍本,再自行定義一些捷徑作法將所有的點連成線再到面而形成現在的想法。雖然有自信可以合理地做出一些不同的東西來,但是那畢竟只是“用自己的經驗湊出符合既定目標”的產物。
RUP一直是有名的開發方法論,不過很多人的評價都說它過於笨重並不適合實用。在與E主管討論方法論(他傾向用RUP)時我常搬出這類的評價來抵抗,他總會說:“你瞭解RUP的全部作法與其精神嗎?你說得出哪裡有問題?哪些作法適用?哪些作法不適用嗎?”當時我認為這僅是強辯時的說詞而堅持己見,每次的討論也常不了了之。然而我現在已經在閱讀RUP的全部正式文件,因為現在終於明白應該從一個穩固的基礎為起點再用自己的經驗來調校它,並不是自己創建一個全新的作法。
完整的開發方法論是一大群人耗費心血所完成的,定義出所有階段、所有角色、所有行為與所有的產出,相信那都是每個人的多年經驗與思索研究的精華,是一個人在一、二十年的經驗所無法相比的。專家的產出是將其自身經驗輸出為系統化、組織化的作法,進而建構起環環相扣的關聯,在某些細節上或許的作法或許不盡理想,卻也不應因噎廢食而全盤否定。
是否曾經有過這樣的經驗?有一個東西在身邊已經存在很久卻一直沒有什麼感覺,等到某天的一個場合再看到它或是某件與它相關的東西,心裡頭各式各樣的想法就不自禁地流動起來,翻騰到最後定型下來卻是另外一個層次的感動。我提到的那個東西並不是女友或妻子(雖然很像是),而是E主管堆在我桌上的一疊書,這篇文章就是引發我不同觀念的催化劑。
Sun的OO-226課程是我接觸OOAD的最初,開始時隱隱覺得這是很不錯的設計作法,但是實際應用在開發時卻有很多無法串連起來的缺漏;累積幾年的經驗後試著以其為藍本,再自行定義一些捷徑作法將所有的點連成線再到面而形成現在的想法。雖然有自信可以合理地做出一些不同的東西來,但是那畢竟只是“用自己的經驗湊出符合既定目標”的產物。
RUP一直是有名的開發方法論,不過很多人的評價都說它過於笨重並不適合實用。在與E主管討論方法論(他傾向用RUP)時我常搬出這類的評價來抵抗,他總會說:“你瞭解RUP的全部作法與其精神嗎?你說得出哪裡有問題?哪些作法適用?哪些作法不適用嗎?”當時我認為這僅是強辯時的說詞而堅持己見,每次的討論也常不了了之。然而我現在已經在閱讀RUP的全部正式文件,因為現在終於明白應該從一個穩固的基礎為起點再用自己的經驗來調校它,並不是自己創建一個全新的作法。
完整的開發方法論是一大群人耗費心血所完成的,定義出所有階段、所有角色、所有行為與所有的產出,相信那都是每個人的多年經驗與思索研究的精華,是一個人在一、二十年的經驗所無法相比的。專家的產出是將其自身經驗輸出為系統化、組織化的作法,進而建構起環環相扣的關聯,在某些細節上或許的作法或許不盡理想,卻也不應因噎廢食而全盤否定。
2009年10月26日 星期一
X07 規畫書撰寫實務課程的收獲
公司打算開一門規畫書撰寫實務的課程,對象主要是業務與市場規劃的同仁。原本不在上課名單內,但是想起上回撰寫規畫書的慘痛教訓後著實希望自己具有這方面的基本能力,因此商請主管在上課的當天硬是向人事部門報名。
課程為十二小時,在授課的中途看著講師整理的投影片對應到之前的問題點時,才發現計畫書的編排除了把內容寫出來之外,是有目標、有架構、有不同角度與不同寫法的,同樣的內容必須根據不同的因素組合來調校。看得出講師在投影片的整理上花費了相當大的心血。休息時間與其他同事閒聊時,他們說雖然教材內容經過整理,但是提出的一些目標與原則感覺根本做不到,譬如說計畫書的內容要寫到能感動人心就太過理想。
認真觀察投影片的結構,慢慢領悟到:對一個難以直接達成的目標,可以拆解為數個可以分開完成的項目,每個項目有自己的作法、輸入與產出。概念就像是下面的圖所表示:

自行推想的思考原則如下:
●每個目標拆解出來的項目必須互斥。(項目拆解子項目時亦同)
●每個目標拆解出來的項目組合起來必須剛好等於目標。(項目拆解子項目時亦同)
●每個作法的輸出必須剛好符合項目的要求。
●每個作法內要有規定的執行步驟
●每個作法使用規定的輸入後,能夠產生規定的產出。
用簡單的一句話表示,會是“精確地拆解,完全地對應”,將目標分割為可以獨立完成的項目,每個項目全部完成後代表目標達成,輔以輸出項目的檢驗標準用以度量目標與項目的進度與品質。觀察自己身邊的許多事若能用這樣的原則處理,相信就會習慣用文件來記錄想法的拆解內容。
註:講師在投影片中根據經驗定義了評審審查的數個重點,根據每個重點建議一些適合的作法。如果定義的審查重點在邏輯上等同於那個目標,那麼針對各個重點的加強就能提升其效果,更有機會達到“打到人心”的目標。
課程為十二小時,在授課的中途看著講師整理的投影片對應到之前的問題點時,才發現計畫書的編排除了把內容寫出來之外,是有目標、有架構、有不同角度與不同寫法的,同樣的內容必須根據不同的因素組合來調校。看得出講師在投影片的整理上花費了相當大的心血。休息時間與其他同事閒聊時,他們說雖然教材內容經過整理,但是提出的一些目標與原則感覺根本做不到,譬如說計畫書的內容要寫到能感動人心就太過理想。
認真觀察投影片的結構,慢慢領悟到:對一個難以直接達成的目標,可以拆解為數個可以分開完成的項目,每個項目有自己的作法、輸入與產出。概念就像是下面的圖所表示:

自行推想的思考原則如下:
●每個目標拆解出來的項目必須互斥。(項目拆解子項目時亦同)
●每個目標拆解出來的項目組合起來必須剛好等於目標。(項目拆解子項目時亦同)
●每個作法的輸出必須剛好符合項目的要求。
●每個作法內要有規定的執行步驟
●每個作法使用規定的輸入後,能夠產生規定的產出。
用簡單的一句話表示,會是“精確地拆解,完全地對應”,將目標分割為可以獨立完成的項目,每個項目全部完成後代表目標達成,輔以輸出項目的檢驗標準用以度量目標與項目的進度與品質。觀察自己身邊的許多事若能用這樣的原則處理,相信就會習慣用文件來記錄想法的拆解內容。
註:講師在投影片中根據經驗定義了評審審查的數個重點,根據每個重點建議一些適合的作法。如果定義的審查重點在邏輯上等同於那個目標,那麼針對各個重點的加強就能提升其效果,更有機會達到“打到人心”的目標。
2009年10月18日 星期日
Y08 不要只用技術的角度想事情(3)
業務人員是最貼近客戶的,在拜訪客戶的同時蒐集客戶目前欠缺與可改善的資訊,回報給公司的市場規劃人員作整體性的計畫;以技術人員的立場來說,一直以來都認為這是最有機會瞭解客戶需要的管道。不過,得到的資訊與真實的差距到底有多遠?我在最近才開始體認到其中可能的誤差。
不管是SOA或是服務體驗,初接觸客戶服務時我都直覺地認為不過是“從客戶的角度來想事情”,然而在很多的時候我們只是“把自己視為客戶”來討論;即使直接對客戶訪談或作問卷調查,取得的資訊通常只是片面的資訊,因為得到的答案是經過思考(可能帶有修正)才輸出的。
德國的服務工程與美國顧客體驗洞察技術提倡的是使用科學化、系統化的方法,將客戶的真實行為模組化為數種Model再進行服務設計。剛開始時實在不以為然,甚至萌生不知道為什麼要學習這種東西的負面想法;隨著漸漸瞭解服務的本意,才慢慢明白要用什麼樣的立場與方式去思考客戶的事。現在與技術人員開會(我當然還算是技術人員啦)時,時常會感覺他們看事情的立場有很大的差異,才猛然省悟原來自己以前也是這樣!
從完全不懂到能初窺其奧妙經過至少四個月,心態上也從抗拒轉變接受並嘗試;回首歷程,能不能聽懂是第一個關卡,想不想接受是第二個關卡,會不會去做是第三個關卡。倘使不去嘗試、不去吸收、不去思考、不去改變,是永遠不可能走出現有模式的。
事情常有一體兩面,以往自己獲知一件事時最先想到的都是找出其問題點並提出難以施行的障礙,現在則會先考慮可以順利執行的狀況然後想出困難點再思考克服的方式。從負面指出哪裡有問題的確是技術人員(與政治人物)會最先想到的,我覺得這才是想事情角度不對的最大癥結吧?
不管是SOA或是服務體驗,初接觸客戶服務時我都直覺地認為不過是“從客戶的角度來想事情”,然而在很多的時候我們只是“把自己視為客戶”來討論;即使直接對客戶訪談或作問卷調查,取得的資訊通常只是片面的資訊,因為得到的答案是經過思考(可能帶有修正)才輸出的。
德國的服務工程與美國顧客體驗洞察技術提倡的是使用科學化、系統化的方法,將客戶的真實行為模組化為數種Model再進行服務設計。剛開始時實在不以為然,甚至萌生不知道為什麼要學習這種東西的負面想法;隨著漸漸瞭解服務的本意,才慢慢明白要用什麼樣的立場與方式去思考客戶的事。現在與技術人員開會(我當然還算是技術人員啦)時,時常會感覺他們看事情的立場有很大的差異,才猛然省悟原來自己以前也是這樣!
從完全不懂到能初窺其奧妙經過至少四個月,心態上也從抗拒轉變接受並嘗試;回首歷程,能不能聽懂是第一個關卡,想不想接受是第二個關卡,會不會去做是第三個關卡。倘使不去嘗試、不去吸收、不去思考、不去改變,是永遠不可能走出現有模式的。
事情常有一體兩面,以往自己獲知一件事時最先想到的都是找出其問題點並提出難以施行的障礙,現在則會先考慮可以順利執行的狀況然後想出困難點再思考克服的方式。從負面指出哪裡有問題的確是技術人員(與政治人物)會最先想到的,我覺得這才是想事情角度不對的最大癥結吧?
2009年10月16日 星期五
Y07 不要只用技術的角度想事情(2)

與不同的同事們聊天時,才發現每個人的設計想法差異很大,最常見的設計想法是將執行交易種類次數報表與記錄模組全部都綁在一個模組裡,然後套用“只作出客戶需要的東西”這個說法。如此一來,這個模組的存在最差的情況下只符合這一個報表,而且記錄的資料元素很可能因沒妥善思考而不足,根本沒法應付未來的各種可能。
不去想其他可能而只注重單一功能,進行速度當然可以很快。但是在未來有需要修改記錄的資料元素才能產生的報表時,就需要改動最底層的模組,連帶地影響其他原本可以正常運作的報表;為了隔絕對舊有系統的影響,唯有copy-paste出另外一套來修改。這樣就產生了號稱絕不疊床架屋的設計──只是同樣的東西有很多套而已。
交易記錄模組是需要良好的設計來提供最大範圍的支援,報表部份則從底層模組取得資料只作客戶所需要的就好。底層的模組用最大化的可能設計來應付未來需求的改變,實際的呈現則只實作客戶提出的部分即可;雖然客戶想要的可能會增加,但是多送他不需要的東西也絕對不會收的。
觀察主管的感覺,發現他們通常會先定出做事目標,然後會陳述做事的順序與原則,但是對於每個步驟所需要用到的資源與可能的困難點幾乎都不涉獵,通常變成很理想化的想法。實際做事的人需要顧及每個步驟的可行性、風險與替代方案,這些都不是只談原則就能夠順利推動,而是需要精確地衡量與思考才有可能做好的。
在主管的想法與實際施行有衝突時,實在有股衝動想跑去主管面前大聲疾呼:可不可以拜託你們從技術的角度來想事情!
2009年10月14日 星期三
Y06 不要只用技術的角度想事情(1)
從程式員的角色成長後,慢慢會接觸到業務與主管等非技術的角色,有時在討論對事物的看法時,他們總會冒出一句:“不要只從技術的角度想事情”。任何事物當然都有不同的切入角度與思考觀點,其他人說這句話時多少都否定說自己提供的僅是片面的想法。然而,只用技術的角度來想事情就表示有缺漏嗎?
在開會時思考系統可以加強的地方時,我想到之前很需要但是沒辦法產生的一份報表(註:不能描述太詳細,就暫時以執行交易種類的次數報表稱之),連帶地想到產生該報表時需要配合記錄Log的各個時間點,並想這個想法整合為一個Log記錄模組的概念。後來將這個概念私下陳述給E主管聽時,他回答說:不要只用技術的角度想事情,不要習慣從bottom-up思考而應該是top-down。意思是說概念要思考能符合客戶的需求且賣得出去才算是成熟的概念。
當時我的腦中忽然發出像是什麼斷掉的聲音,立即有了否定的回答。
現在我需要一份現有系統無法產生的報表,便開始思考要怎麼做才可以滿足自己的需求;發現報表所需要的資料可以從增加特定時間點的Log來取得後,就認為應該有一個專門負責記錄Log的模組來收集各種資料。這個模組概念的產生是由我自己(客戶)需要的報表(需求)所引導出來的,完全符合由上到下、根據使用者需求而出現的想法。
目前其他客戶想要什麼樣的報表我們都不可能知道,即使今天訪談了十個客戶所收集到的報表種類,在找到第十一個客戶時還是有可能要之前沒提過的報表;就算我們想從客戶的角度來思考,也不能肯定思考出來的範圍是不是百分之百。在無法肯定未來變化的現在,我只能以現有模組的角度來定義其中的資料元素(譬如人、事、時、地、物),期望在設計的同時可以有最大範圍的排列組合,而未來客戶想要的報表儘可能地落在設計的範圍裡。

用最小的額外花費涵蓋最大範圍的可能需求,不就是設計的目的嗎?我這麼反問E主管,他沒有反駁。
在開會時思考系統可以加強的地方時,我想到之前很需要但是沒辦法產生的一份報表(註:不能描述太詳細,就暫時以執行交易種類的次數報表稱之),連帶地想到產生該報表時需要配合記錄Log的各個時間點,並想這個想法整合為一個Log記錄模組的概念。後來將這個概念私下陳述給E主管聽時,他回答說:不要只用技術的角度想事情,不要習慣從bottom-up思考而應該是top-down。意思是說概念要思考能符合客戶的需求且賣得出去才算是成熟的概念。
當時我的腦中忽然發出像是什麼斷掉的聲音,立即有了否定的回答。
現在我需要一份現有系統無法產生的報表,便開始思考要怎麼做才可以滿足自己的需求;發現報表所需要的資料可以從增加特定時間點的Log來取得後,就認為應該有一個專門負責記錄Log的模組來收集各種資料。這個模組概念的產生是由我自己(客戶)需要的報表(需求)所引導出來的,完全符合由上到下、根據使用者需求而出現的想法。
目前其他客戶想要什麼樣的報表我們都不可能知道,即使今天訪談了十個客戶所收集到的報表種類,在找到第十一個客戶時還是有可能要之前沒提過的報表;就算我們想從客戶的角度來思考,也不能肯定思考出來的範圍是不是百分之百。在無法肯定未來變化的現在,我只能以現有模組的角度來定義其中的資料元素(譬如人、事、時、地、物),期望在設計的同時可以有最大範圍的排列組合,而未來客戶想要的報表儘可能地落在設計的範圍裡。

用最小的額外花費涵蓋最大範圍的可能需求,不就是設計的目的嗎?我這麼反問E主管,他沒有反駁。
2009年10月10日 星期六
Y05 都只是為了完成功能……
對程式設計人員來說,被要求的結果就是要寫出能達成需求的程式碼,而最尋常的情況就是遵循最簡單的道理:產出一堆可以完成功能的程式碼交差。暫且不管程式碼對於功能是否有多餘的設計、也不管程式流程控管的處理是否完善(這些是程式碼與功能的內容對應),光是“程式碼為可見之物”這個事實就會衍生出一些管理的事。

就像作文一樣,看到題目之後心裡就要先有文章的架構鋪陳;功能明確之後同樣會有執行的順序。如同作文時的擬定大綱,設計程式也需要概略描述達成功能的過程。作文的大綱完成後要開始逐段、逐句、逐字寫出文章,程式碼的產出也是如此;其中的差別在於作文強調的是從頭到尾、一氣呵成的感覺,寫程式除了這個感覺之後還有逐步的例外處理。
寫出程式後需要經過測試來精確地保證功能可被達成,測出錯誤會使得程式碼有再次的修改,每次修改都會有版本的記錄;每個版本各修改了哪些地方,造成什麼影響都必須要能迅速查詢到。怎麼佈置、怎麼撰寫、如何保證與如何管理,是因為有程式碼的存在所連帶產生的四件事情,標準化的做事會有方法與準則,這意味著還要定義出至少四組的做事方法與做事準則。倘使做這些事的過程裡需要有其他的物(工具)協助時,還會再衍生更多的事……。
只是為了達成一個功能,在產生程式碼的過程需要考慮很多其他的事,可以想見如果沒有全面性地看待而只注重在如何完成功能,就會造成除了執行正確之外的全部都有潛在的問題。雖說完成功能是最終目標,然而考慮程式時常被修改的特性後應同時注重其他方面的要求。
2009年10月6日 星期二
X06 建立小朋友的能力架構
在小朋友的成長過程裡,父母總會希望他們具備各種能力以應付日後社會上的各種競爭。有些父母會以“多才多藝”作為小朋友的學習目標,但是學習項目過多會使得小朋友們失去童年的時間,因此我的想法在於建立他們的能力架構。能力架構倘使可以適當地建立起來,日後可以根據個人的興趣喜好選擇適合自己的項目,再經由這個能力架構達到更快速的學習與產出。
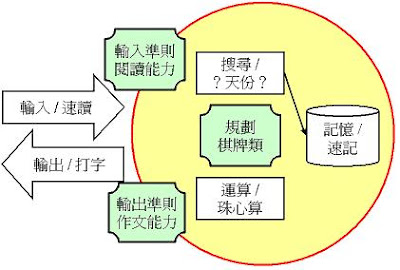
能力架構的想法類似於電腦的架構,在最底層的需求有輸入、記憶、搜尋、運算與輸出五種能力。每種能力根據自己的認知定義應該要學習的技能。
●輸入:單位時間內傳入的資料量越多就有機會攝取更多的知識,速讀可以提升傳入資訊的速率。速讀的訓練可以從國小低、中年級開始。
●記憶:傳入的資料需要被記憶下來才能在日後再度使用,速記可以提高傳入資訊被記憶下來的比率。坊間的速記課程也包含了速讀,同樣從國小低、中年級開始。
●搜尋:根據現在的情境到腦中的龐大記憶裡搜尋各式各樣符合的資訊運用,我不知道學習什麼技能才能提升這項能力。或許,這是倚賴天份的?
●運算:年輕時跟算術有關的運算都會佔據考試很多時間,學習珠心算將運算時間降到最低,自然有充分的時間驗算並思考其他更有意義的問題。從剛學會筆寫阿拉伯數字的中班年紀開始。
●輸出:思考的結果會經由肢體創造出一些產出,其中很大的部分會是文字,現在電腦的使用佔了很大的比例,因此打字可以提升輸出文字的速率。從認字與注音都稍具基礎的國小中年級開始。
在這五項基本能力之上,我認為還有三個概念性的能力需要加強:
●輸入準則:閱讀能力有助於拆解文字(或圖形)成為腦中可記憶的儲存想法,拆解得越多越可以看懂更多其他人所想要表達的想法。
●輸出準則:作文能力有助於將腦中儲存的想法用文字(或圖形)組織為別人可以看懂的內容,想法描寫得越詳實越有助於讓旁人的腦中建構出與自己相彷的想法。
●規劃能力:利用棋牌類必須規劃佈局同時推算對手各種對策的規則特性,養成每一步進行都先思考各種可能的習慣;同時等待對手回應也能夠培養等待的耐心。
建立起基本的架構能力後,其他需要輸入、記憶、運算與輸入的技能都能有事半功倍的效果,同時運用輸入準則、輸出準則與規劃等概念性的能力還能夠再加強這些架構能力處理資訊的品質。這樣的道理與架構的設計不是很接近嗎?

能力架構的想法類似於電腦的架構,在最底層的需求有輸入、記憶、搜尋、運算與輸出五種能力。每種能力根據自己的認知定義應該要學習的技能。
●輸入:單位時間內傳入的資料量越多就有機會攝取更多的知識,速讀可以提升傳入資訊的速率。速讀的訓練可以從國小低、中年級開始。
●記憶:傳入的資料需要被記憶下來才能在日後再度使用,速記可以提高傳入資訊被記憶下來的比率。坊間的速記課程也包含了速讀,同樣從國小低、中年級開始。
●搜尋:根據現在的情境到腦中的龐大記憶裡搜尋各式各樣符合的資訊運用,我不知道學習什麼技能才能提升這項能力。或許,這是倚賴天份的?
●運算:年輕時跟算術有關的運算都會佔據考試很多時間,學習珠心算將運算時間降到最低,自然有充分的時間驗算並思考其他更有意義的問題。從剛學會筆寫阿拉伯數字的中班年紀開始。
●輸出:思考的結果會經由肢體創造出一些產出,其中很大的部分會是文字,現在電腦的使用佔了很大的比例,因此打字可以提升輸出文字的速率。從認字與注音都稍具基礎的國小中年級開始。
在這五項基本能力之上,我認為還有三個概念性的能力需要加強:
●輸入準則:閱讀能力有助於拆解文字(或圖形)成為腦中可記憶的儲存想法,拆解得越多越可以看懂更多其他人所想要表達的想法。
●輸出準則:作文能力有助於將腦中儲存的想法用文字(或圖形)組織為別人可以看懂的內容,想法描寫得越詳實越有助於讓旁人的腦中建構出與自己相彷的想法。
●規劃能力:利用棋牌類必須規劃佈局同時推算對手各種對策的規則特性,養成每一步進行都先思考各種可能的習慣;同時等待對手回應也能夠培養等待的耐心。
建立起基本的架構能力後,其他需要輸入、記憶、運算與輸入的技能都能有事半功倍的效果,同時運用輸入準則、輸出準則與規劃等概念性的能力還能夠再加強這些架構能力處理資訊的品質。這樣的道理與架構的設計不是很接近嗎?
2009年9月30日 星期三
Y04 POC的產出不適合直接使用
有些專案在競標之前會先製作POC(Prototype of Concept),等到專案開始後會有人直接拿POC裡的產出放到真正執行的環境裡。理由當然是說這個功能在POC已經做出來而且可以執行,只要再加上相關環節後就能擴充到足以驗收的程度。
這當然是從“可以驗收”的角度來看待POC的產出,但是深入一層去想,POC這個名稱已經很清楚地說是“概念的雛型”,目的在於驗證想法是否可被實現。在架構已經選定的前提下,自己在製作POC時思考的是:
●什麼時間點需要執行這個功能(入口)
●執行這個功能時需要哪些步驟(流程)
●每一個步驟各需要什麼元件來支援(動作)
決定執行的時間點後可以導向入口,在專案裡掛上功能的入口很簡單,但是需要調整傳入與傳出的資料。流程是功能進行的順序,在POC時幾乎都只製作正常的流程與幾個需要呈現的錯誤,要在專案實用就得加上所有的錯誤控制。動作方面大多會使用到其他元件提供的功能來組成自己的分解動作,倘若是第三方提供的元件使用的方式會比較固定,但要是使用元件預定是在專案內才設計的就會有被變動影響的風險。
達成目標經過的每一步以及收送的資料內容都需要經過設計,這些並不是在製作為了測試概念能否執行的POC時會考慮到的,僅求一時之快將POC的內容直接引用,未來勢必會出現設計想法不同的落差。能夠只作些小修改就融入專案設計算是最好的,但是大多數的情況還是需要打掉重做才能符合專案需要。
曾經在專案後期被POC改寫的元件卡著上下不得:想作些專案需要的修改時覺得綁手綁腳,想重做又會浪費重新測試的資源。捨棄POC所寫的功能而僅參考執行概念再重新設計出新的元件,是我決定的作法。
這當然是從“可以驗收”的角度來看待POC的產出,但是深入一層去想,POC這個名稱已經很清楚地說是“概念的雛型”,目的在於驗證想法是否可被實現。在架構已經選定的前提下,自己在製作POC時思考的是:
●什麼時間點需要執行這個功能(入口)
●執行這個功能時需要哪些步驟(流程)
●每一個步驟各需要什麼元件來支援(動作)
決定執行的時間點後可以導向入口,在專案裡掛上功能的入口很簡單,但是需要調整傳入與傳出的資料。流程是功能進行的順序,在POC時幾乎都只製作正常的流程與幾個需要呈現的錯誤,要在專案實用就得加上所有的錯誤控制。動作方面大多會使用到其他元件提供的功能來組成自己的分解動作,倘若是第三方提供的元件使用的方式會比較固定,但要是使用元件預定是在專案內才設計的就會有被變動影響的風險。
達成目標經過的每一步以及收送的資料內容都需要經過設計,這些並不是在製作為了測試概念能否執行的POC時會考慮到的,僅求一時之快將POC的內容直接引用,未來勢必會出現設計想法不同的落差。能夠只作些小修改就融入專案設計算是最好的,但是大多數的情況還是需要打掉重做才能符合專案需要。
曾經在專案後期被POC改寫的元件卡著上下不得:想作些專案需要的修改時覺得綁手綁腳,想重做又會浪費重新測試的資源。捨棄POC所寫的功能而僅參考執行概念再重新設計出新的元件,是我決定的作法。
2009年9月28日 星期一
X05 積極主動的態度
在前面的例子裡,為了同步同一階層人員的想法建立的同步機制,相當於建立了一個“物”;而一個新“物”的產生所增加的“事”,至少需要讓不同角色的人知道怎麼使用,還有維持其運作的管理與維護。使用關係到個人怎麼操作,是每個人都必定要會的,但是管理與維護的工作卻不是明確屬於任一個人的。
在一個團隊裡要做的事非常多,明確屬於個人的責任就是自己所該做的,另外還有許多是沒法歸屬責任或是多人共同用到的。觀察人們面對那些公共事項時的反應是很有趣的,當然大多數人的心態是多一事不如少一事,拼命地閃躲或是推卸責任讓別人來負責。從個人的角度來看,會有這樣的反應是很正常的。
將視野提升到專案來看,當人們都自掃門前雪時就表示著那些事可能落在不適任的人身上,或者是被敷衍地完成,進而造成做出的結果並不符合眾人真正的期待;倘若很不幸地這些公共建設沒有做好時嚴重影響到日後每個人的工作方式與效率,就會造成深遠的影響。對於管理者來說,看著成員們動不動就說“那不是我負責的”或“我不知道”時,也會有深深的無力感吧。
在專案裡客戶會打電話過來問些問題,若詢問的對象不在,接電話的人通常會說那是誰負責的,然後就幫忙留話。這樣做當然沒有錯,假如態度積極一些,直接問清楚要問的問題後再問負責的人細節後再回覆客戶,對專案來說代表著反應機制的迅速,對個人來說可以多知道一件事情。具有如此積極態度的團隊,無論士氣或是效率都會提升很多的。
在一個團隊裡要做的事非常多,明確屬於個人的責任就是自己所該做的,另外還有許多是沒法歸屬責任或是多人共同用到的。觀察人們面對那些公共事項時的反應是很有趣的,當然大多數人的心態是多一事不如少一事,拼命地閃躲或是推卸責任讓別人來負責。從個人的角度來看,會有這樣的反應是很正常的。
將視野提升到專案來看,當人們都自掃門前雪時就表示著那些事可能落在不適任的人身上,或者是被敷衍地完成,進而造成做出的結果並不符合眾人真正的期待;倘若很不幸地這些公共建設沒有做好時嚴重影響到日後每個人的工作方式與效率,就會造成深遠的影響。對於管理者來說,看著成員們動不動就說“那不是我負責的”或“我不知道”時,也會有深深的無力感吧。
在專案裡客戶會打電話過來問些問題,若詢問的對象不在,接電話的人通常會說那是誰負責的,然後就幫忙留話。這樣做當然沒有錯,假如態度積極一些,直接問清楚要問的問題後再問負責的人細節後再回覆客戶,對專案來說代表著反應機制的迅速,對個人來說可以多知道一件事情。具有如此積極態度的團隊,無論士氣或是效率都會提升很多的。
2009年9月23日 星期三
X04 同步的速度與內容是團隊戰力的關鍵

用這張圖簡單地描繪專案裡的人員階層與關聯,從人員間的關係可以看出訊息的傳遞普遍存在於每個人,同樣一個訊息需要根據不同的對象各自傳送一次。今天領導者A解決某個重要問題時剛好成員B不在身邊,他就將原因與解法對成員A與成員C說明,這個時候就造成成員B根本不知道發生過這件事。
將事件與對應的處理讓其他人知道的最佳解決方式是留下記錄。如果有個機制記錄每一天發生的事情與對應處理,那麼成員B回來後只要查詢一下就能知道那件事;如果有個機制記錄特定事情的歷史軌跡,那麼任何一個人都可以交待那件事的來龍去脈;如果有個機制記錄事情的類型,那麼可以延伸查詢相同類型的事件都哪些……。
記錄的類型與管理方式會造成不同的效果。電子郵件、文件、程式、錯誤回報系統都可能會有事件的記錄,假如保存與歸類的機制都沒有定義,所有的記錄就形同一盤散沙般無法整合。我們不應從記錄的角度來看待說只要在相關的地方註明清楚即可,而應該從事件的角度來看如何從一件特定的事件找到所有相關的一切,像是處理方式、前因後果、改變與影響等等的資訊,如此才能全面性地來看待該事件。

這正是我重視知識管理系統的原因,因為它提供的是記錄內容的整合。一個歸類後的題目,可以在類型與事件中交互查詢,也能深入一個問題內找出所有的關聯、追查所有的產出,更重要的是累積下來的資訊都可以在任何時候給任何人作為處理事件的標準參考教材。(當然,資訊的關聯都是由人所建立的,唯有全部成員都有正確的觀念後才有可能施行這個想法)
可以試著想像在需要某些資訊時,不知道放在哪裡、不知道是否完整、不知道為什麼要這樣做、不知道做了有什麼影響這些狀況都會影響一個人的認知與反應。從需要者的角度建立好他們需要的資訊是一種只需建立一次卻有永久影響的花費,資訊在成員間同步的速度與內容將會決定該團隊的戰力強弱──因為團隊的能力強弱並不是看最強的有多強,而是看最弱的有多弱!
2009年9月21日 星期一
X03 定義出正確的客戶並找出全部的需要
已知有一個重要的功能即將交給自己開發,這個時候在心裡盤算的是些什麼呢?大多技術人員都知道需要定義出功能清單作為開發的基準,功能清單應由提出需求的人認可才算數。但是若承接的功能是屬於底層架構的功能,未來會有許多專案人員根據這個功能來開發許多程式,這個時候心裡應該盤算什麼呢?
優先考慮的當然是誰來驗收這個功能?從句意來看很明顯地有兩類客戶:
●使用者:需要這個功能可以正常執行的人。
●專案人員:基於這個功能來開發其他程式的人。

做出可正常執行的功能給使用者驗收是一定要的,因為你的東西一定要先能用才有可能收得到錢。但是專案人員是使用自己產出的功能予以加工而包裝出使用者要的東西,需要考慮的項目就多很多。像是:
●功能的目的與限制條件
●使用方式與範例
●定義檔的格式
●設計的過程與想法(維護需要)
●輔助的設定工具(使用方式太複雜時需要)
雖然對專案人員來說提供這些是正常的,但要讓專案人員能熟練地使用必須要額外付出不少努力。聰明的人自然會提出能讓自己信服的理由:“這個功能最終目的是要讓使用者正常地執行,因此只要符合這個目標即可”,所以就縮小了客戶的範圍與要做的事;主管們當然很高興聰明的人可以用很短的時間“做好”這個功能而且驗收,可以繼續處理下一個功能創造更多的產能。
主管只看產能且設計者只看驗收的情形下,專案人員需要的東西大半被忽視,難以訓練成用快速的方法做出正確的東西,工作久了自然會有嚴重的倦怠感。專案人員在主管眼中僅是可被取代的生產工具而已,發出的聲音幾乎都被忽略,在此狀況之下公司的開發團隊文化就只能取決於聰明的人怎麼做了。
優先考慮的當然是誰來驗收這個功能?從句意來看很明顯地有兩類客戶:
●使用者:需要這個功能可以正常執行的人。
●專案人員:基於這個功能來開發其他程式的人。

做出可正常執行的功能給使用者驗收是一定要的,因為你的東西一定要先能用才有可能收得到錢。但是專案人員是使用自己產出的功能予以加工而包裝出使用者要的東西,需要考慮的項目就多很多。像是:
●功能的目的與限制條件
●使用方式與範例
●定義檔的格式
●設計的過程與想法(維護需要)
●輔助的設定工具(使用方式太複雜時需要)
雖然對專案人員來說提供這些是正常的,但要讓專案人員能熟練地使用必須要額外付出不少努力。聰明的人自然會提出能讓自己信服的理由:“這個功能最終目的是要讓使用者正常地執行,因此只要符合這個目標即可”,所以就縮小了客戶的範圍與要做的事;主管們當然很高興聰明的人可以用很短的時間“做好”這個功能而且驗收,可以繼續處理下一個功能創造更多的產能。
主管只看產能且設計者只看驗收的情形下,專案人員需要的東西大半被忽視,難以訓練成用快速的方法做出正確的東西,工作久了自然會有嚴重的倦怠感。專案人員在主管眼中僅是可被取代的生產工具而已,發出的聲音幾乎都被忽略,在此狀況之下公司的開發團隊文化就只能取決於聰明的人怎麼做了。
2009年9月18日 星期五
X02 領導的風格決定了文化
迪爾(Terry Deal)與甘迺迪(Allan Kennedy)在“企業文化”(Corporate Cultures)一書中明示:“企業文化是公司員工上下一致共同遵循的行為準則,一套做事情的方式”。企業文化也代表“在這裡,事情如何完成”與“組織成員間的互動關係”。
工作上有時遇到某些事情沒處理好,會聽人講起公司文化的影響與重要性。原先認為公司文化是種虛無的概念,在無形之中慢慢自行形成的;但經歷過一些狀況之後卻感覺到文化的形成主要在於“上行下效”,每個團隊的領導者如何做事連帶地會影響到團體內所有成員的做事態度。這個感想也剛好對應了前面的企業文化定義。
領導者在意的面向會影響成員的做事方式,絕大部分的領導者基於成本與績效的壓力,想法都是目標導向的。僅在意“事情何時完成”時成員就會找出最快符合驗收條件的方式來做事,連帶地成員之間在分配任務時也只在意自己的目標何時可以達成。每個階層都用自己的目標來檢視所有的事,眼光就逐漸變為短淺,落在自己頭上的事才算事,別人的事能夠不沾上邊就不要去碰,久而久之自然就會形成冷漠的公司文化。(切割系統介面如果也能切割到這麼乾淨的話,會是很令人佩服的事,可惜二者總是恰好相反)
領導者普遍在意的還有“解決眼前的問題”,資源的調度都是為了要快速地解決會影響驗收與成本的問題,只要搞定跟錢有關的問題就好,其他的都看不上眼。若是再搭配之前形成的冷漠文化,公司的氣氛低迷,團隊的士氣渙散等現象自然會跟著出現。更重要的是問題的根本原因從來都不會被搬上檯面來討論,也沒去研究未來如何要如何避免相同的現象,成員就這樣眼睜睜看著幾個同樣的原因造成各種不同的問題,令人疲於奔命。
希莉格在“真希望我二十歲就懂的事“書中說:“聰明的人往往陷入一個陷阱:他們寧可做〔聰明〕的事,而不是〔正確〕的事。所謂聰明,就是最符合自己的利益。”如果要提出公司文化形成的最重要因素,我深深地認同這一句話。
工作上有時遇到某些事情沒處理好,會聽人講起公司文化的影響與重要性。原先認為公司文化是種虛無的概念,在無形之中慢慢自行形成的;但經歷過一些狀況之後卻感覺到文化的形成主要在於“上行下效”,每個團隊的領導者如何做事連帶地會影響到團體內所有成員的做事態度。這個感想也剛好對應了前面的企業文化定義。
領導者在意的面向會影響成員的做事方式,絕大部分的領導者基於成本與績效的壓力,想法都是目標導向的。僅在意“事情何時完成”時成員就會找出最快符合驗收條件的方式來做事,連帶地成員之間在分配任務時也只在意自己的目標何時可以達成。每個階層都用自己的目標來檢視所有的事,眼光就逐漸變為短淺,落在自己頭上的事才算事,別人的事能夠不沾上邊就不要去碰,久而久之自然就會形成冷漠的公司文化。(切割系統介面如果也能切割到這麼乾淨的話,會是很令人佩服的事,可惜二者總是恰好相反)
領導者普遍在意的還有“解決眼前的問題”,資源的調度都是為了要快速地解決會影響驗收與成本的問題,只要搞定跟錢有關的問題就好,其他的都看不上眼。若是再搭配之前形成的冷漠文化,公司的氣氛低迷,團隊的士氣渙散等現象自然會跟著出現。更重要的是問題的根本原因從來都不會被搬上檯面來討論,也沒去研究未來如何要如何避免相同的現象,成員就這樣眼睜睜看著幾個同樣的原因造成各種不同的問題,令人疲於奔命。
希莉格在“真希望我二十歲就懂的事“書中說:“聰明的人往往陷入一個陷阱:他們寧可做〔聰明〕的事,而不是〔正確〕的事。所謂聰明,就是最符合自己的利益。”如果要提出公司文化形成的最重要因素,我深深地認同這一句話。
2009年9月16日 星期三
X01 系統的功能來自客戶需要的服務
系統的開發大多著重於系統如何滿足使用系統者的需求,對系統使用者作需求訪談後就會往下展開系統內部的相關分析設計。近幾年IBM提出服務導向架構(Service Oriented Architecture)的想法,資策會也在推廣服務體驗工程(Service Experience Engineering)的方法,最近剛好有機會接觸到這些從不同角度看待事物而產生的概念。

開發系統的時候注重的是從使用者角度做事時系統提供的功能;在以使用者為中心處理一件事時,系統提供越大範圍的支持會讓使用者做事越輕鬆。然而在很多情境下,像是銀行、電信局、郵局等等的櫃檯人員,使用者會做什麼事情是根據臨櫃的客戶的需要而決定的,使用者端提供越快、越正確、越完善的服務就有助於客戶的認同。(此時的系統只屬於服務的一部分而已)
既然發動使用者做出對應行為的真正原因是客戶想要的服務,那麼研究客戶端的需要便形成了現在的趨勢。定義出客戶在特定情境下想要達成的目標,洞察客戶在該情境下的行為、對四周人與物的互動,從中找出可以改善現有服務或是建立新服務的地方,就有機會提供給客戶更好的服務體驗並有機會為公司帶來更多的客戶。
在系統的關係圖上從Actor一分為二,在系統方面需要的是方便好用的整合環境,在客戶方面需要的是提供更切合需要的服務。原則聽起來並不難,但是要從原本的技術角度轉換到客戶角度來看待這層關係,視野很容易就被原有的思維所限制住而難以突破──至少我就經歷過這段痛苦期。
所有的事都發生的原因,也有其完成的目標,發掘出最根本的需要並依此展開為實行的細節就更有機會真正地滿足原始的需求。這不是很簡單的道理嗎?

開發系統的時候注重的是從使用者角度做事時系統提供的功能;在以使用者為中心處理一件事時,系統提供越大範圍的支持會讓使用者做事越輕鬆。然而在很多情境下,像是銀行、電信局、郵局等等的櫃檯人員,使用者會做什麼事情是根據臨櫃的客戶的需要而決定的,使用者端提供越快、越正確、越完善的服務就有助於客戶的認同。(此時的系統只屬於服務的一部分而已)
既然發動使用者做出對應行為的真正原因是客戶想要的服務,那麼研究客戶端的需要便形成了現在的趨勢。定義出客戶在特定情境下想要達成的目標,洞察客戶在該情境下的行為、對四周人與物的互動,從中找出可以改善現有服務或是建立新服務的地方,就有機會提供給客戶更好的服務體驗並有機會為公司帶來更多的客戶。
在系統的關係圖上從Actor一分為二,在系統方面需要的是方便好用的整合環境,在客戶方面需要的是提供更切合需要的服務。原則聽起來並不難,但是要從原本的技術角度轉換到客戶角度來看待這層關係,視野很容易就被原有的思維所限制住而難以突破──至少我就經歷過這段痛苦期。
所有的事都發生的原因,也有其完成的目標,發掘出最根本的需要並依此展開為實行的細節就更有機會真正地滿足原始的需求。這不是很簡單的道理嗎?
2009年9月14日 星期一
Y03 與理論型同事對設計作法的討論
E主管是之前提到過的理論型同事,在技術部門裡可以說就只有我與他有把握能夠將分析與設計全部轉化為可以實現的作法。最近我們在參考RUP想要定義出一套可實現的OOAD作法,但是為了用什麼而做的議題有了一場“熱烈”的討論。
他的想法主要是參考大師們的說法,因為那些都是根據有經驗者的智慧結晶而定義出來的;不管是分析設計時應該做的步驟、使用的工具與應有的產出等等,都鉅細靡遺地遵循書上的方式。我則根據部落格上的心得,先把使用UML工具會作出的產出定義為程式碼,再逐一將分析與設計的想法衍伸在程式碼裡。
我們的分歧點在於“不應該用程式碼作設計”。E主管的感覺是直接產出程式碼而不先模組化就會回到以前設計不良的窠臼,同時也提到以前在學校若先寫出程式碼會被教授責備根本不作設計的事,當然也聽不進去我希望解決之前使用UML工具進度緩慢、達到分析與設計模組追溯的目標,因為他暫時落入“馬上有程式碼絕對作不出好設計”的想法中。
爭辯了一陣子雙方僵持不下,最後我只好換一種方式說明。先解釋說,現在有一個功能與Rose完全一樣的UML工具,採用的OOAD作法也與RUP完全一樣,然而那個工具的存檔格式剛好與Java程式碼一模一樣。今天我們的OOAD作法每一步應該做什麼就同樣地在“程式碼”會有什麼,這樣一來無論分析或是設計都能夠採用我計畫的工具作出全部的管理與追溯;分析的“程式碼”則在build產出時不處理而僅作為模組化的分途。
E主管認同了我的說法,但有個前提是:要先明確定義好OOAD的詳細步驟後,才能逐一定義與我想法之間的對應。前面的討論對於modeling來說都只是產出的物,先要有應做之事與其順序後再去談應有之物;這也正是做事的基本前提。
他的想法主要是參考大師們的說法,因為那些都是根據有經驗者的智慧結晶而定義出來的;不管是分析設計時應該做的步驟、使用的工具與應有的產出等等,都鉅細靡遺地遵循書上的方式。我則根據部落格上的心得,先把使用UML工具會作出的產出定義為程式碼,再逐一將分析與設計的想法衍伸在程式碼裡。
我們的分歧點在於“不應該用程式碼作設計”。E主管的感覺是直接產出程式碼而不先模組化就會回到以前設計不良的窠臼,同時也提到以前在學校若先寫出程式碼會被教授責備根本不作設計的事,當然也聽不進去我希望解決之前使用UML工具進度緩慢、達到分析與設計模組追溯的目標,因為他暫時落入“馬上有程式碼絕對作不出好設計”的想法中。
爭辯了一陣子雙方僵持不下,最後我只好換一種方式說明。先解釋說,現在有一個功能與Rose完全一樣的UML工具,採用的OOAD作法也與RUP完全一樣,然而那個工具的存檔格式剛好與Java程式碼一模一樣。今天我們的OOAD作法每一步應該做什麼就同樣地在“程式碼”會有什麼,這樣一來無論分析或是設計都能夠採用我計畫的工具作出全部的管理與追溯;分析的“程式碼”則在build產出時不處理而僅作為模組化的分途。
E主管認同了我的說法,但有個前提是:要先明確定義好OOAD的詳細步驟後,才能逐一定義與我想法之間的對應。前面的討論對於modeling來說都只是產出的物,先要有應做之事與其順序後再去談應有之物;這也正是做事的基本前提。
2009年9月9日 星期三
Y02 如何寫出難改又難懂的程式碼?
一直都在談如何作好分析與設計,這回就來個逆向思考的建議。
●目標:如何寫出難改又難懂的程式碼?
想像公司早上第一個到的人所要做的事如下:開鐵捲門、用識別證開門、開一號盤的15個電燈開關(1-15)與二號盤的15個電燈開關(16-30)。現要設計一個功能來實現這些行為,建議使用以下推薦的方式來撰寫程式,保證可以達到難改又難懂的特殊效果同時不會影響功能的正常執行。(此等技術暫時命名為程式碼的人工混淆化)
●Class、Method與Field的隨興命名
效果:讓人即使看到名稱也不見得知道這就是他要找的程式。
●Class隨便放到某個Package裡
效果:與上一招同時施展,可以讓人感覺Class在某個雲深不知處的地方。
●Class、Method與Field內外完全不寫任何註解
效果:讓別人從眾多的程式碼反推你原本想要做什麼。如有人能完全識破此機關的話一定要選為衣缽繼承人,因為那是萬中無一的奇人。
●執行的大大小小步驟都寫在同一個Method
效果一:搭配前一招時可以讓邏輯處理的焦點忽大忽小,明明在講進門要做的事卻一下子跳到拿出識別證的動作,完全不知道在幹嘛。
效果二:可以保護自己想出來的程式解法,例如自己發明一個很帥的識別證拿法就可以直接寫在Method裡,其他人想要用就只能copy(因為要抽方法就得幫你改寫程式,以我所知沒幾個人有這閒工夫);有天你發現姿勢可以更帥時可以保證只有你知道,因為別人抄到的是你前一次的姿勢,跟你肯定沒得比。
●不要花時間去想執行發生錯誤時該怎麼辦
效果一:程式碼裡一定存在著錯誤,這樣一來可以用更多的錯來證明這句話是極為正確的。
效果二:搭配前前招使用,可以讓別人在不知道處理邏輯之餘更不知道發生錯誤要怎麼辦?同時讓老板知道只有你能搞定這樣的錯誤處理問題。(註:平時常逛逛求職網站是有助益的,因為總有一天會發生連自己都搞不定的重大問題……)
採用以上方式撰寫程式碼,將會產生下列各方面的效益:
●個人方面:
加速個人的效率與產能(不用抽Class與Method可減少思考與重構時間)
提升個人在開發團隊中的重要性(沒人有把握修改別人的程式)
●公司方面:
加強與其他公司合作的意願(即使程式碼外流也毌用擔心技術被學走)
減少額外控管程式碼的成本(只要從jar file反組譯回來就是完整程式碼)
●產業方面:
創造更多的營業額(因應提高開發與維護的成本會增加系統的售價)
提升開發人員的素質(無法看懂別人程式碼者會被淘汰,只留下適任者)
註:最近一個多月狂寫公司某份計劃書,因而導致這篇文章的風格被影響。
2009年9月4日 星期五
Y01 程式設計是藝術創作?
K主管常說一句話:“程式設計在實質上是一種藝術的創作,同樣的需要被不同的人實現時會有不同的產出。”就我所知有不少人都贊同這個觀點。前陣子我也認為這個說法挺有道理的,可是總覺得似乎有哪裡不對勁;思索幾天之後終於有了不同的想法而與K主管聊起這件事。
我提出的切入點是人像的雕塑,這很明顯是屬於藝術的範疇,每一位作者都可以任憑喜好去製作各式各樣的人像。接著提出同樣屬於人像創作的秦朝兵馬俑,我們都曉得兵馬俑的數量很多,雖然姿勢、表情與裝扮都有不同,但是服裝與身材卻是大致上相同的。再極端一點可以想像有一國的統治者想在全國各地放置出他的雕像,於是他穿上最喜愛的服裝並擺出某種姿勢,要求全國所有工匠全部都得做出一模一樣的人像。(以上的前提建立在工廠出現之前,所有的人像都必須經由手工製作)
從上面的說法,我們可以發現隨著要求的規格越來越多,每個藝術家的創作也可以從依各人隨興而作演變為具有統一規格的產出。同樣的道理也適用在程式設計之上:在沒有規範時每個人寫出程式碼的想法與風格會是相異的,隨著種種規範與規格的建立將會調整每個人的想法與寫法,漸漸演進為所有人產出的程式碼每個人一看就明白。
K主管認同了我的看法,想法調整為:遵循規範與規則的部分像是工程,其他的部分則屬於藝術的創作。然而隨著規範與規則訂定地更加完整,藝術創作的範圍勢必越來越小;等到某一天程式設計的一切都有人定義出良好的規範與規則時,programmer是不是真的就會像作業員一樣,每個行為都只能根據該生產線的SOP找出適合的零件來組裝產品呢?
我提出的切入點是人像的雕塑,這很明顯是屬於藝術的範疇,每一位作者都可以任憑喜好去製作各式各樣的人像。接著提出同樣屬於人像創作的秦朝兵馬俑,我們都曉得兵馬俑的數量很多,雖然姿勢、表情與裝扮都有不同,但是服裝與身材卻是大致上相同的。再極端一點可以想像有一國的統治者想在全國各地放置出他的雕像,於是他穿上最喜愛的服裝並擺出某種姿勢,要求全國所有工匠全部都得做出一模一樣的人像。(以上的前提建立在工廠出現之前,所有的人像都必須經由手工製作)
從上面的說法,我們可以發現隨著要求的規格越來越多,每個藝術家的創作也可以從依各人隨興而作演變為具有統一規格的產出。同樣的道理也適用在程式設計之上:在沒有規範時每個人寫出程式碼的想法與風格會是相異的,隨著種種規範與規格的建立將會調整每個人的想法與寫法,漸漸演進為所有人產出的程式碼每個人一看就明白。
K主管認同了我的看法,想法調整為:遵循規範與規則的部分像是工程,其他的部分則屬於藝術的創作。然而隨著規範與規則訂定地更加完整,藝術創作的範圍勢必越來越小;等到某一天程式設計的一切都有人定義出良好的規範與規則時,programmer是不是真的就會像作業員一樣,每個行為都只能根據該生產線的SOP找出適合的零件來組裝產品呢?
2009年6月30日 星期二
W26 一名家教班裡的小三學生
不久之前造訪一位朋友所開的國小家教班。在裡面遇到一位小三女學生,她的基礎非常不好,面對簡單的加減應用問題時,是用猜的來決定要用加號或是減號。我試著用數線的方向性來對應加減,也試過讓她固定用大的減去小的來得到答案,但是沒有真實理解數的概念時,一切的說法都沒法讓她解出任何一個類似的應用問題。
周遭遇到的小朋友都還算聰明,很訝異還是有小朋友的理解力如此不佳,這時不禁連想到李家同先生的文章與他所堅持的教育理念。會去留意其他人的的退休計劃,有不少人認為勞碌了大半輩子後,剩下的時光想要過輕鬆的生活或是享受異地的旅遊。
對妻說過,退休後想每年都住在一個不同的偏遠地方,一方面體驗不同環境中生活差異,另一方面就是主動地為附近的小孩進行課業輔導並傳授做人做事的方法。教育的平均有兩個方向可以努力,一個是提升偏遠地區的教育資源,另一個是提升資質較差的小孩到平均的水準,每年旅居到一個不同的區域協助當時所能遇到的所有人,這應該是能力範圍內所能做到的。
資質不好的人因為聽不懂而無法改變自己到能理解的程度,但是聰明的人反倒因為聽懂而更無法改變到更進一層(為他人服務)的程度。缺乏"吸收資訊,判斷對錯,調整自己,成就他人"的成長彈性,到底只能讓自己的聰明才智僅讓自己獲得利益,同時還認為其他人的改變也只是為了他自己而已。(奇怪的是,反倒是心裡有不好的想法時大半會說是因為別的某某事件被連帶影響的)
今天的我對於系統開發與人生想法是如此。明天呢?後天呢?想法還會有再度改變的那一天嗎?
周遭遇到的小朋友都還算聰明,很訝異還是有小朋友的理解力如此不佳,這時不禁連想到李家同先生的文章與他所堅持的教育理念。會去留意其他人的的退休計劃,有不少人認為勞碌了大半輩子後,剩下的時光想要過輕鬆的生活或是享受異地的旅遊。
對妻說過,退休後想每年都住在一個不同的偏遠地方,一方面體驗不同環境中生活差異,另一方面就是主動地為附近的小孩進行課業輔導並傳授做人做事的方法。教育的平均有兩個方向可以努力,一個是提升偏遠地區的教育資源,另一個是提升資質較差的小孩到平均的水準,每年旅居到一個不同的區域協助當時所能遇到的所有人,這應該是能力範圍內所能做到的。
資質不好的人因為聽不懂而無法改變自己到能理解的程度,但是聰明的人反倒因為聽懂而更無法改變到更進一層(為他人服務)的程度。缺乏"吸收資訊,判斷對錯,調整自己,成就他人"的成長彈性,到底只能讓自己的聰明才智僅讓自己獲得利益,同時還認為其他人的改變也只是為了他自己而已。(奇怪的是,反倒是心裡有不好的想法時大半會說是因為別的某某事件被連帶影響的)
今天的我對於系統開發與人生想法是如此。明天呢?後天呢?想法還會有再度改變的那一天嗎?
2009年6月29日 星期一
W25 My Object = Data + Behavior
在與兩位同事討論時,其中一位同事說,每個行為包裝為一個方法的想法很像Behavior Driven Design(後來查過資料,發現應更像先不看架構的責任導向設計--Responsibility Driven Design)。Object一直都是包含資料與行為,既然具有這兩類元素,Data Driven Design與Behavior Driven Design就應該同時注重。
角色、物件、大小事都對應到各自的Object(或是元件)並依其特性抽取共用是我的設計基礎,資料結構與處理步驟全採用一對一的對應設計是我的堅持,符合原始特性的定義才能夠將改變局部化到最小區塊,進而得到最少化的測試範圍。這些好處的相對代價是開發人員要額外作設計,必須花費較多的時間為自己與別人安排程式碼。
對於OOAD的題目,我一個人思考了兩年,提出的經驗與作法盡可能涵蓋到工作中所經歷到的各個角落。有一位喜歡看書的理論型同事是我經常討論的伙伴,從他那裡聽說到許多不用功就不會知道的名詞與作法;共事的同事們是我主要的經驗來源,由於他們現有的產出我才能明白各個角落的好處與缺失;專案上的同事則是我琢磨想法的對象,常問他們現在的作法與優缺點是什麼,同時提出我的作法詢問是否能留下好處並改善弱點。
每個地方的說法我都推論與驗證過,雖然能有可以解決的方案,但是我相信並不會是最佳的作法。許多同好都投注許多心力鑽研軟體工程的各個方面,沒有道理我只用兩個人年就有最後的結論。目前差不多是我的極限了,未來除了製作對應的工具之外,更需要的是有其他相信這一條路的人一同討論每個角落的最佳化。
這十年來在工作上所遇到能夠抱持相近努力方向的人,實在是屈一手之指可數呀。(當然不包含發現專案有問題時才喊著要好好設計口號、作下一個專案時又開始計較時程與產出的那些人)
角色、物件、大小事都對應到各自的Object(或是元件)並依其特性抽取共用是我的設計基礎,資料結構與處理步驟全採用一對一的對應設計是我的堅持,符合原始特性的定義才能夠將改變局部化到最小區塊,進而得到最少化的測試範圍。這些好處的相對代價是開發人員要額外作設計,必須花費較多的時間為自己與別人安排程式碼。
對於OOAD的題目,我一個人思考了兩年,提出的經驗與作法盡可能涵蓋到工作中所經歷到的各個角落。有一位喜歡看書的理論型同事是我經常討論的伙伴,從他那裡聽說到許多不用功就不會知道的名詞與作法;共事的同事們是我主要的經驗來源,由於他們現有的產出我才能明白各個角落的好處與缺失;專案上的同事則是我琢磨想法的對象,常問他們現在的作法與優缺點是什麼,同時提出我的作法詢問是否能留下好處並改善弱點。
每個地方的說法我都推論與驗證過,雖然能有可以解決的方案,但是我相信並不會是最佳的作法。許多同好都投注許多心力鑽研軟體工程的各個方面,沒有道理我只用兩個人年就有最後的結論。目前差不多是我的極限了,未來除了製作對應的工具之外,更需要的是有其他相信這一條路的人一同討論每個角落的最佳化。
這十年來在工作上所遇到能夠抱持相近努力方向的人,實在是屈一手之指可數呀。(當然不包含發現專案有問題時才喊著要好好設計口號、作下一個專案時又開始計較時程與產出的那些人)
2009年6月27日 星期六
W24 成敗的關鍵(2)──看待的角度不同
收集一些在專案開發期間常聽到的話語,用類似的語意表達如下:
●專案經理:專案的目標在於系統的準時驗收,任何可能影響時程的額外活動最好避免。
●前來支援的架構師:我已建立好可以執行的基礎架構,只要這樣這樣使用就可以。至於元件要怎麼安排、程式怎麼規定,那是專案團隊的事。
●系統分析人員:每個交易或功能的需求訪談都已經完成,並彙整到各自的需求文件裡。
●系統設計人員:根據每個交易的需求文件,已經設計並開發好對應的程式。同時單元測試過的內容都正常。
表面上看起來沒什麼問題,對不?每個人都做好每個人自己應做的工作。可惜的是,即使每個人都努力地讓產出滿足驗收清單上的每個檢核項目,卻還是有些莫名其妙的問題跑出來、客戶也會莫名其妙地抱怨系統品質不大好、每個人也莫外其妙地幾乎不懂別人負責的部分。
專案裡的產出,不管是文件還是程式都有許多共用的部分,每個人都用自己的角度處理共用的部分當然很容易令其他人難以使用。共用的地方最好是可以符合全部人都方便使用,那是需要投入時間去整理與調整(設計)的;但是"為了公眾的利益去作設計,會影響到投入自己的工作的時間"卻是一種衝突,在管理上不去注重共用的部分而強調個人產出,終究會使大家只留意被要求的地方。
我在N年前也還是可以用極快的速度達成個人產出目標的,不過每次完成工作後再回頭為新需求修改程式時,總是發現內部已經錯綜複雜到難以變動;這樣的經驗累積幾次後終於覺悟自己還缺少了些什麼。現在的我在進行某個步驟時,都會額外花一些時間去整理共用的部分,但是在與其他較年輕的人討論類似話題時,總是發現他們雖已知道現況有些窒礙而還看不到我所注重的地方。
我並不清楚每個人看待的方向是訓練出來或者是依檢查標準而定,但是消極地不想去碰灰色地帶的心情卻感受得到。每戶人家都自掃門前雪時,共用的通路肯定是不會有人去清理的!
●專案經理:專案的目標在於系統的準時驗收,任何可能影響時程的額外活動最好避免。
●前來支援的架構師:我已建立好可以執行的基礎架構,只要這樣這樣使用就可以。至於元件要怎麼安排、程式怎麼規定,那是專案團隊的事。
●系統分析人員:每個交易或功能的需求訪談都已經完成,並彙整到各自的需求文件裡。
●系統設計人員:根據每個交易的需求文件,已經設計並開發好對應的程式。同時單元測試過的內容都正常。
表面上看起來沒什麼問題,對不?每個人都做好每個人自己應做的工作。可惜的是,即使每個人都努力地讓產出滿足驗收清單上的每個檢核項目,卻還是有些莫名其妙的問題跑出來、客戶也會莫名其妙地抱怨系統品質不大好、每個人也莫外其妙地幾乎不懂別人負責的部分。
專案裡的產出,不管是文件還是程式都有許多共用的部分,每個人都用自己的角度處理共用的部分當然很容易令其他人難以使用。共用的地方最好是可以符合全部人都方便使用,那是需要投入時間去整理與調整(設計)的;但是"為了公眾的利益去作設計,會影響到投入自己的工作的時間"卻是一種衝突,在管理上不去注重共用的部分而強調個人產出,終究會使大家只留意被要求的地方。
我在N年前也還是可以用極快的速度達成個人產出目標的,不過每次完成工作後再回頭為新需求修改程式時,總是發現內部已經錯綜複雜到難以變動;這樣的經驗累積幾次後終於覺悟自己還缺少了些什麼。現在的我在進行某個步驟時,都會額外花一些時間去整理共用的部分,但是在與其他較年輕的人討論類似話題時,總是發現他們雖已知道現況有些窒礙而還看不到我所注重的地方。
我並不清楚每個人看待的方向是訓練出來或者是依檢查標準而定,但是消極地不想去碰灰色地帶的心情卻感受得到。每戶人家都自掃門前雪時,共用的通路肯定是不會有人去清理的!
2009年6月26日 星期五
W23 做人的方法(16)──態度與高度決定一切
態度:接收到外來資訊後能與自己想法比對並朝最大的最佳化加以調整。越自我的人越不容易改變。
高度:從不同人的角度來看待一件事物並朝對最多人有利的方向改變。越自我的人越無法從別人的角度看待事物。
這些當然是我自己的解釋,不過卻是從一些事件裡得到的結論。
團隊裡有位超強的工程師,能夠快速地選擇對的技術作出功能,也能夠快速地判斷問題提供作法;聽起來一切都很好,但是唯一的問題是方法沒有適當切割且沒有註解,就造成沒有人的理解跟得上他的思緒。有位專案經理跟他說,寫出讓其他團隊成員可以快速理解的註解與寫法,讓多一點人瞭解他的產出未來可以讓自己輕鬆一點,他回答道:我不會UML,也不會寫敍述性的文件。
2009/05與大主管面談時提到對現有設計的改善作法,他說能夠瞭解我想法帶來的好處,稍晚他安排我與兩位資深工程師討論我的想法。在聽過我的敍述之後,他們說:我們可以聽懂你所想要做的事,但是看不到好處在哪裡?我的作法對做事的人來說是浪費一些時間來換取更多的人快速知道自己做了什麼,看不到好處的意思很可能是因為他們並未從旁人的角度來看待。
前面的工程師留下了很多作品,包括我之前維護的那個產品;這個產品應用在專案時的使用門檻很高,目前被重用的其他工程師都花了很多時間去摸索程式碼。他們異口同聲地說,想要深入瞭解這個產品沒有捷徑,一定要自己下苦功。不過在面對同樣沒有註解且風格與自己不同的程式碼時,那位工程師終於說:看不懂他寫的程式!
有些懷疑現在的大師們是否都在開發上具有強大的能力,以至於他們從未完整維護過全由別人所寫的程式碼?賦予自己的責任是開發系統時自然會專注在這個課題;至於怎樣讓別人容易維護程式碼?管他的,反正我自己維護完全沒有問題而且不會找我去做。
高度:從不同人的角度來看待一件事物並朝對最多人有利的方向改變。越自我的人越無法從別人的角度看待事物。
這些當然是我自己的解釋,不過卻是從一些事件裡得到的結論。
團隊裡有位超強的工程師,能夠快速地選擇對的技術作出功能,也能夠快速地判斷問題提供作法;聽起來一切都很好,但是唯一的問題是方法沒有適當切割且沒有註解,就造成沒有人的理解跟得上他的思緒。有位專案經理跟他說,寫出讓其他團隊成員可以快速理解的註解與寫法,讓多一點人瞭解他的產出未來可以讓自己輕鬆一點,他回答道:我不會UML,也不會寫敍述性的文件。
2009/05與大主管面談時提到對現有設計的改善作法,他說能夠瞭解我想法帶來的好處,稍晚他安排我與兩位資深工程師討論我的想法。在聽過我的敍述之後,他們說:我們可以聽懂你所想要做的事,但是看不到好處在哪裡?我的作法對做事的人來說是浪費一些時間來換取更多的人快速知道自己做了什麼,看不到好處的意思很可能是因為他們並未從旁人的角度來看待。
前面的工程師留下了很多作品,包括我之前維護的那個產品;這個產品應用在專案時的使用門檻很高,目前被重用的其他工程師都花了很多時間去摸索程式碼。他們異口同聲地說,想要深入瞭解這個產品沒有捷徑,一定要自己下苦功。不過在面對同樣沒有註解且風格與自己不同的程式碼時,那位工程師終於說:看不懂他寫的程式!
有些懷疑現在的大師們是否都在開發上具有強大的能力,以至於他們從未完整維護過全由別人所寫的程式碼?賦予自己的責任是開發系統時自然會專注在這個課題;至於怎樣讓別人容易維護程式碼?管他的,反正我自己維護完全沒有問題而且不會找我去做。
2009年6月25日 星期四
W22 成敗的關鍵(1)──開發速度的考量
專案裡需要一個分析資料結構的功能,該結構裡的ParentDataModel與ChileDataModel是從屬關係,但是都具有相同的屬性存取方法,需要寫的功能是處理多個屬性的集合,從兩種Data Model取得屬性的設定值來檢查是否Class字串。
由於這個功能時間上比較趕,撰寫ParentDataModel的時候就直接只思考它的特性,將完成該方法的功能填在一個Method裡。等到撰寫ChildDataModel的時候發現與前一個方法似乎只有傳入的物件不同而已,但是再抽取前一個方法似乎要浪費一些時間,於是copy-paste後再修改了幾個地方。用極快的速度寫好這個取得屬性的功能。

認真地分析一下,這兩個方法只是傳入的物件與紅色框內的程式碼不同,其他的內容幾乎一樣,裡面包含了兩個分解動作與一個迴圈。開發最快的方式是像前面一樣直接複製後修改物件名程,但是就有一堆重覆的程式碼。理想的作法應該再切分為兩個小方法並串連呼叫才對。下面是把分解動作另外抽出方法的結果,同樣是沒有註解的程式碼卻具有很高的可讀性。

之前提過曾把一個元件的View與Controller寫在一起,寫的時候連測試用了三小時,改寫時連測試又多花五個小時,但是一開始就分開撰寫的話估計應要五個小時;概略計算的話,如果沒有修改可以省兩個小時,修改時要多花五個小時。觀點拉到有100個元件的系統來看,假設未來因需要而有20個需要重構。直接作的時候省下100 X 2 = 200小時,另外花費20 X 5 = 100小時重構,整個開發與測試的投入反而省下100個小時。
這是專案開發裡的數字迷思,缺乏彈性的快速設計反而會比設計充滿彈性的作法快200小時,即使面對需求改變還是快了100小時。以前我估計的設計時間常被說為留有buffer,因為別人估兩天可完成的東西我需要五天;如果你是專案經理的話,會用什麼角度思考而出抉擇呢?
由於這個功能時間上比較趕,撰寫ParentDataModel的時候就直接只思考它的特性,將完成該方法的功能填在一個Method裡。等到撰寫ChildDataModel的時候發現與前一個方法似乎只有傳入的物件不同而已,但是再抽取前一個方法似乎要浪費一些時間,於是copy-paste後再修改了幾個地方。用極快的速度寫好這個取得屬性的功能。
認真地分析一下,這兩個方法只是傳入的物件與紅色框內的程式碼不同,其他的內容幾乎一樣,裡面包含了兩個分解動作與一個迴圈。開發最快的方式是像前面一樣直接複製後修改物件名程,但是就有一堆重覆的程式碼。理想的作法應該再切分為兩個小方法並串連呼叫才對。下面是把分解動作另外抽出方法的結果,同樣是沒有註解的程式碼卻具有很高的可讀性。
之前提過曾把一個元件的View與Controller寫在一起,寫的時候連測試用了三小時,改寫時連測試又多花五個小時,但是一開始就分開撰寫的話估計應要五個小時;概略計算的話,如果沒有修改可以省兩個小時,修改時要多花五個小時。觀點拉到有100個元件的系統來看,假設未來因需要而有20個需要重構。直接作的時候省下100 X 2 = 200小時,另外花費20 X 5 = 100小時重構,整個開發與測試的投入反而省下100個小時。
這是專案開發裡的數字迷思,缺乏彈性的快速設計反而會比設計充滿彈性的作法快200小時,即使面對需求改變還是快了100小時。以前我估計的設計時間常被說為留有buffer,因為別人估兩天可完成的東西我需要五天;如果你是專案經理的話,會用什麼角度思考而出抉擇呢?
2009年6月24日 星期三
W21 記錄的設計(2)──交易記錄Data Model的集合與應用
經過適當的設計,我們可以從server的Log檔案裡用工具取得所有使用者的交易記錄。雖然從電子日誌的資料庫也可以拿到類似的項目,但是在一個嚴格控管的環境裡並不是隨時都可以接觸到資料庫且隨心所欲地下達想要作的指令。
分析出來的交易記錄可以用人、事、時、地、物各種不同的角度去篩選範圍內的資料,如果篩選的條件有適當的分群可以有更方便的應用,像可選擇從個人角度與單位角度去篩選資料。對於一個時間範圍內(通常是給定的Log記錄範圍),較常見的需求是交易的執行種類、執行次數與執行時間,這可以反應系統的使用效益與效能,也可能被要求作成統計圖表以方便查看。
就曾因交易執行時間過長的問題被要求分析Log,當時拿了五個工作天之間的四台server與十台client的Log記錄後,利用之前寫的分析工具來處理上千萬行的Log記錄,最後得到了客戶反應時間慢的區間內的各種數據用以佐證對於問題所在的推測。另外,查看個人在某個時間點所作的事情序列,也是除錯時重要的資訊。
概略說之,全部Log記錄檔還是以Data Model的方式來看待,裡面包含的每行Log記錄組合為一個個的交易記錄Data Model後,就能夠像是搜尋資料庫一般篩選出任何需要的資訊──當然,前提是Log記錄的內容要能確切反應出該時間點的系統執行資訊。
分析出來的交易記錄可以用人、事、時、地、物各種不同的角度去篩選範圍內的資料,如果篩選的條件有適當的分群可以有更方便的應用,像可選擇從個人角度與單位角度去篩選資料。對於一個時間範圍內(通常是給定的Log記錄範圍),較常見的需求是交易的執行種類、執行次數與執行時間,這可以反應系統的使用效益與效能,也可能被要求作成統計圖表以方便查看。
就曾因交易執行時間過長的問題被要求分析Log,當時拿了五個工作天之間的四台server與十台client的Log記錄後,利用之前寫的分析工具來處理上千萬行的Log記錄,最後得到了客戶反應時間慢的區間內的各種數據用以佐證對於問題所在的推測。另外,查看個人在某個時間點所作的事情序列,也是除錯時重要的資訊。
概略說之,全部Log記錄檔還是以Data Model的方式來看待,裡面包含的每行Log記錄組合為一個個的交易記錄Data Model後,就能夠像是搜尋資料庫一般篩選出任何需要的資訊──當然,前提是Log記錄的內容要能確切反應出該時間點的系統執行資訊。
2009年6月23日 星期二
W20 現在的執行位置──getClass()與getMethod()
在Log裡的記錄需要註明程式的出處時,一定會用到getClass(),經由這個方法可以取得Class名稱;但是再細部定位到程式的發生點時就只能拿到行號,然後再找程式碼看看那一行是在做什麼事。
為什麼拿到的資訊不是Method Name而是與程式碼內容無關的行號呢?在執行時有getClass()與this可以取得現在執行的物件資訊、卻沒有getRunningMethod()與thisMethos(二者均為虛構)等取得現在執行方法的功能呢?推測應該與程式設計者較注重結果卻不注重過程有關係──因為只要知道確實在哪裡出錯就好,不需要知道原來想要做的目的。
若去詢問什麼樣的程式碼需要被抽取到Method存放?一個很尋常的答案是"發現某一段程式碼在其他地方存在且完全相同時",這就是我感到奇怪的地方。檢查兩段程式碼是否相同的觀點僅是查看其外表,但是我一直認為程式碼被群聚為Method是它們屬於分解動作之一才會被提出的。重構的觀點提到"有一行註解之下的一段程式碼可以抽出為一個方法",這比較接近事實,不過要如何保證一行註解之下的是"一段程式"而不是"三段程式"?
Method抽取時依這樣的概略原則拿到的可能是錯誤的對應:或許是應該在一起的程式碼被拆開,或者是不該在一起的被放在一起,這些都會在某些場合下造成系統的複雜調整。當每個Method都是依照負責某個行為的目的而被建立起來之後,才會有對getRunningMethod()的需要。
註:目前的getRunningMethod()可以利用Exception裡的printTraceStach()來達成。將這個內容輸出為字串,就可以解析出指定位置的完整method call stack,利用此方法可以省下在很多方法內插入Log的時間。
為什麼拿到的資訊不是Method Name而是與程式碼內容無關的行號呢?在執行時有getClass()與this可以取得現在執行的物件資訊、卻沒有getRunningMethod()與thisMethos(二者均為虛構)等取得現在執行方法的功能呢?推測應該與程式設計者較注重結果卻不注重過程有關係──因為只要知道確實在哪裡出錯就好,不需要知道原來想要做的目的。
若去詢問什麼樣的程式碼需要被抽取到Method存放?一個很尋常的答案是"發現某一段程式碼在其他地方存在且完全相同時",這就是我感到奇怪的地方。檢查兩段程式碼是否相同的觀點僅是查看其外表,但是我一直認為程式碼被群聚為Method是它們屬於分解動作之一才會被提出的。重構的觀點提到"有一行註解之下的一段程式碼可以抽出為一個方法",這比較接近事實,不過要如何保證一行註解之下的是"一段程式"而不是"三段程式"?
Method抽取時依這樣的概略原則拿到的可能是錯誤的對應:或許是應該在一起的程式碼被拆開,或者是不該在一起的被放在一起,這些都會在某些場合下造成系統的複雜調整。當每個Method都是依照負責某個行為的目的而被建立起來之後,才會有對getRunningMethod()的需要。
註:目前的getRunningMethod()可以利用Exception裡的printTraceStach()來達成。將這個內容輸出為字串,就可以解析出指定位置的完整method call stack,利用此方法可以省下在很多方法內插入Log的時間。
2009年6月22日 星期一
W19 記錄的設計(1)──記錄行與交易記錄Data Model
系統執行狀態與歷史的內容能夠提供許多分析的資訊,這些資訊我們習慣在執行中隨時記錄為Log。不過Log的特性是一次記錄一筆與上下文無關的文字,所以如何在一行文字間涵蓋到重要的資訊以及建立起前後Log的關聯,是定義記錄內容的重要關鍵。
對單行記錄而言,人、事、時、地、物五個基本資訊加上想要記錄的內容應是最基本的構成。記錄的內容原則上是由能識別系統行為的關鍵字,加上進行該動作時所需的相關資訊所組成;這部份最好是格式化為固定字串,能夠轉換為基本Data Model會較容易處理。
在一個交易期間會有多行的記錄存在,因此要定義交易開始與結束的記錄內容,夾在這兩行之間的表示為同一個交易期間。以範圍框住同一交易的想法雖然沒錯,但是遇到多執行緒執行交易時會發生兩個交易內容混雜產出的問題,因此記錄行必須再定義一個交易序號的資訊以供識別。此外多行交易記錄經過處理應該能夠取得一個交易記錄Data Model,具有從交易方面看待時應有的執行屬性。
記錄行的意義與達成目標的分解動作是很相似的,記錄的是單一動作的執行內容;交易記錄的意義則像是功能的定義,在裡面可取得執行時的相關資訊。記錄行主要提供的是有沒有進行該項動作、有沒有錯誤發生,交易記錄主要提供的是該交易的基本資訊、輸出輸入資訊與結果;前者是系統人員所檢視,後者則應用在使用交易的記錄分析。
對單行記錄而言,人、事、時、地、物五個基本資訊加上想要記錄的內容應是最基本的構成。記錄的內容原則上是由能識別系統行為的關鍵字,加上進行該動作時所需的相關資訊所組成;這部份最好是格式化為固定字串,能夠轉換為基本Data Model會較容易處理。
在一個交易期間會有多行的記錄存在,因此要定義交易開始與結束的記錄內容,夾在這兩行之間的表示為同一個交易期間。以範圍框住同一交易的想法雖然沒錯,但是遇到多執行緒執行交易時會發生兩個交易內容混雜產出的問題,因此記錄行必須再定義一個交易序號的資訊以供識別。此外多行交易記錄經過處理應該能夠取得一個交易記錄Data Model,具有從交易方面看待時應有的執行屬性。
記錄行的意義與達成目標的分解動作是很相似的,記錄的是單一動作的執行內容;交易記錄的意義則像是功能的定義,在裡面可取得執行時的相關資訊。記錄行主要提供的是有沒有進行該項動作、有沒有錯誤發生,交易記錄主要提供的是該交易的基本資訊、輸出輸入資訊與結果;前者是系統人員所檢視,後者則應用在使用交易的記錄分析。
2009年6月20日 星期六
W18 快速開發的工具(3)──進化為系統分析工具(SA Tool)
限制整個Workspace的UI編輯工具為只能編輯專案層級的元件時,編輯的對象就會只有Use Case下的流程,選用的範圍則是該tier提供的Activity。執行流程的定義只是SA的一部分,所有與交易相關的定義都應該被容納到系統分析工具裡才是完整的SA Tool。
這表示交易相關的輸入與輸出都要被考慮,像是畫面的設計、列印的格式、主機電文的切割定義、主流程的功能選擇、輸出入欄位與Context的對應……等等都應該呈現在工具裡。另外整個系統的設計也應該被定義,像是角色的定義、交易的定義、資料的定義、以及任二者之間的關聯……等等。SA Tool的好處在於進行需求訪談的同時,可以利用系統收集全部相關資訊並立即使用,在快速定義交易的同時盡量避免產生一些已知的問題。
上述每一個編輯項目都應該要能嵌裝與拆解,施行時視系統實際的架構關聯來設定SA Tool應該具有哪些模組。這是一個更龐大的工程,系統開發時所需要的一切概念組成的架構與關係需要精確地定義與設定,再根據這個架構去設計呈現的UI編輯工具;我們當然明白,只要那個架構有所變更就會影響到SA Tool需要再度改寫。換句話說,除非能夠研究出開發系統時會有的所有定義與關聯,要不然SA Tool應該是個會被改來改去的玩具,或者是寫死為只適用在自己專案裡某部分的特定工具而已。
"可被遞迴處理的元件結構"是對程式設計的目標,"通用的系統分析工具"則是對系統開發的理想。縱使這兩個想法的背後都需要艱難的分析設計與實作,不過若能確認能夠解決大部分的現有問題而沒有邏輯上的破綻,這個決心是不會變的。
這表示交易相關的輸入與輸出都要被考慮,像是畫面的設計、列印的格式、主機電文的切割定義、主流程的功能選擇、輸出入欄位與Context的對應……等等都應該呈現在工具裡。另外整個系統的設計也應該被定義,像是角色的定義、交易的定義、資料的定義、以及任二者之間的關聯……等等。SA Tool的好處在於進行需求訪談的同時,可以利用系統收集全部相關資訊並立即使用,在快速定義交易的同時盡量避免產生一些已知的問題。
上述每一個編輯項目都應該要能嵌裝與拆解,施行時視系統實際的架構關聯來設定SA Tool應該具有哪些模組。這是一個更龐大的工程,系統開發時所需要的一切概念組成的架構與關係需要精確地定義與設定,再根據這個架構去設計呈現的UI編輯工具;我們當然明白,只要那個架構有所變更就會影響到SA Tool需要再度改寫。換句話說,除非能夠研究出開發系統時會有的所有定義與關聯,要不然SA Tool應該是個會被改來改去的玩具,或者是寫死為只適用在自己專案裡某部分的特定工具而已。
"可被遞迴處理的元件結構"是對程式設計的目標,"通用的系統分析工具"則是對系統開發的理想。縱使這兩個想法的背後都需要艱難的分析設計與實作,不過若能確認能夠解決大部分的現有問題而沒有邏輯上的破綻,這個決心是不會變的。
2009年6月19日 星期五
W17 快速開發的工具(2)──Project、Workspace元件的UI編輯工具
Component結構UI編輯工具是針對單一元件的設計,但是將系統用tier與layer切割之後會發現每一個格子都具有相同的特性,與同一層及自己繼承的元件都擁有類似的關聯。根據這個特性,只要詳加定義可以使用的範圍,就可以在指定編輯某一格子時只顯示出有關聯的其他資訊。
設定關聯後顯示相關的範圍是這個想法的核心。目前的想法是用一個設定工具將Workspace內的每個Project都對應到一個tier-layer切割出來的格子,每個格子可以引用的範圍是同layer、同tier的合部與同tier、下一個layer的全部;然後再更進一步地對每一個格子裡的Package定義使用關聯,不在使用方向下的Package都是不能呼叫的。
編輯工具的元件索引區應列示現有的所有元件以及它們所在的格子,選擇一個元件就會開啟它的結構與方法列表;選擇一個方法後在旁邊列出所有可選用的元件與API,可以為方法繪製流程圖並引用那些元件方法與API來組裝。依此模式來設計全部元件的每一個方法。
與註解有關的功能部分可以加在這個工具裡,像是編輯Class或Method的註解與自動產生基本資訊等。或許還有更多的部分還可以加上,目前對於這個龐大的工具只有初步的輪廓知道可行,但是還沒有很清楚地定義各個細節。
設定關聯後顯示相關的範圍是這個想法的核心。目前的想法是用一個設定工具將Workspace內的每個Project都對應到一個tier-layer切割出來的格子,每個格子可以引用的範圍是同layer、同tier的合部與同tier、下一個layer的全部;然後再更進一步地對每一個格子裡的Package定義使用關聯,不在使用方向下的Package都是不能呼叫的。
編輯工具的元件索引區應列示現有的所有元件以及它們所在的格子,選擇一個元件就會開啟它的結構與方法列表;選擇一個方法後在旁邊列出所有可選用的元件與API,可以為方法繪製流程圖並引用那些元件方法與API來組裝。依此模式來設計全部元件的每一個方法。
與註解有關的功能部分可以加在這個工具裡,像是編輯Class或Method的註解與自動產生基本資訊等。或許還有更多的部分還可以加上,目前對於這個龐大的工具只有初步的輪廓知道可行,但是還沒有很清楚地定義各個細節。
2009年6月18日 星期四
W16 快速開發的工具(1)──Component結構UI編輯工具
在資訊業裡的大多數人員都有著一個夢想:是不是哪天能夠出現一個工具,只要根據需求勾選一些選項或是畫出流程圖後,就可以自動產出能夠達成功能且具有一定品質的程式?雖然絕大多數的人覺得這像是被工作壓榨過度後的囈語,但是我這兩來年在心裡盤算與推演卻感覺那是有機會達成的事。
回憶一下設計一個小方法時自己的行為。首先先根據需要所要處理的資料來定義處理的迴圈、決定每層迴圈內所要執行判斷條件或動作、針對每個動作挑選出最適合的API方法、最後再將處理結果或例外傳出去。簡單地看,設計的過程只有流程順序的定義與動作方法的選取而已,不是嗎?(不存在的動作方法可以宣告一個新的,再回歸為選取)
印度公司的電文處理流程定義與IBM的SOA概念,多少都幫助我更完整地思考這個可能性。想像有那麼一個元件設計的UI工具,在設計方法時的主要編輯區是繪製流程圖的區域,我們可以先在這裡決定方法內處理迴圈,之後要定義處理動作時右邊有個區域列出允許呼叫的全部元件方法與API,只要從中挑選出想要使用來組裝。(宣告與給予初值也視為一種動作)
對於程式人員來說,用工具來產生程式的效率實在是慢太多了,倒不如直接寫程式省事。用工具的好處是可以降低學習的門檻、限定使用方法的範圍並產出結構與寫法一致的程式碼,這都是寫程式時難以達成的標準。把程式碼倒回工具產生流程圖倒也可以,順便篩選那些無法倒回流程圖的程式,那表示撰寫時並沒有按照一定的規範。
回憶一下設計一個小方法時自己的行為。首先先根據需要所要處理的資料來定義處理的迴圈、決定每層迴圈內所要執行判斷條件或動作、針對每個動作挑選出最適合的API方法、最後再將處理結果或例外傳出去。簡單地看,設計的過程只有流程順序的定義與動作方法的選取而已,不是嗎?(不存在的動作方法可以宣告一個新的,再回歸為選取)
印度公司的電文處理流程定義與IBM的SOA概念,多少都幫助我更完整地思考這個可能性。想像有那麼一個元件設計的UI工具,在設計方法時的主要編輯區是繪製流程圖的區域,我們可以先在這裡決定方法內處理迴圈,之後要定義處理動作時右邊有個區域列出允許呼叫的全部元件方法與API,只要從中挑選出想要使用來組裝。(宣告與給予初值也視為一種動作)
對於程式人員來說,用工具來產生程式的效率實在是慢太多了,倒不如直接寫程式省事。用工具的好處是可以降低學習的門檻、限定使用方法的範圍並產出結構與寫法一致的程式碼,這都是寫程式時難以達成的標準。把程式碼倒回工具產生流程圖倒也可以,順便篩選那些無法倒回流程圖的程式,那表示撰寫時並沒有按照一定的規範。
2009年6月17日 星期三
W15 令人感到麻煩的設計(16)──固定值與固定常數的意義
在設計與實作的時候,所有的固定數值與字串都應該被抽取為常數,使用的時候就將固定數值與字串置換為該常數。原本我也依這個方式使用常數,但是不久前製作計算function points工具程式時卻發現不同的用法。
上下傳電文欄位是功能點計算的來源之一,第一個專案的電文定義檔命名規則是在交易代號後加上u或d來表示,因此將上下傳檔名另外用常數代表,取檔時就使用txnNo+UPLOAD_FILENAME+".xml"來組成完整檔名。程式拿到第二個專案就發生了錯誤,因為檔名是以別的名稱識別,只好直接修改常數內容讓程式可以正常執行。
依照事對物的想法,有UPLOAD_FILENAME的存在就應該對應存在一個getUploadFilename()的事存在,之前在檔名裡直接嵌入UPLOAD_FILENAME的作法是一種綑綁。"取得上傳的檔名"應是一件事,其中包含的是一種規則,雖然在大多數的情況下規則是直接取得UPLOAD_FILENAME,但是規則總有變的一天,將改變的規則限定在一個給定的方法裡可以增加設計的彈性。
那個工具程式後來作了一個改變:收集所有在專案裡可能有所不同的規則,定義一個Interface容納取得那些規則的方法,看要執行哪一個專案的內容就使用該專案特有的規則定義。
得到了寶貴的經驗:每個常數都應該轉換為具有該層級元件意義的名稱與存取方法,以便操作時明白其含義。呼叫時可直接在參數裡引用常數,但是在取用時要使用存取方法,因為取用時隱含規則,規則都可能改變。
上下傳電文欄位是功能點計算的來源之一,第一個專案的電文定義檔命名規則是在交易代號後加上u或d來表示,因此將上下傳檔名另外用常數代表,取檔時就使用txnNo+UPLOAD_FILENAME+".xml"來組成完整檔名。程式拿到第二個專案就發生了錯誤,因為檔名是以別的名稱識別,只好直接修改常數內容讓程式可以正常執行。
依照事對物的想法,有UPLOAD_FILENAME的存在就應該對應存在一個getUploadFilename()的事存在,之前在檔名裡直接嵌入UPLOAD_FILENAME的作法是一種綑綁。"取得上傳的檔名"應是一件事,其中包含的是一種規則,雖然在大多數的情況下規則是直接取得UPLOAD_FILENAME,但是規則總有變的一天,將改變的規則限定在一個給定的方法裡可以增加設計的彈性。
那個工具程式後來作了一個改變:收集所有在專案裡可能有所不同的規則,定義一個Interface容納取得那些規則的方法,看要執行哪一個專案的內容就使用該專案特有的規則定義。
得到了寶貴的經驗:每個常數都應該轉換為具有該層級元件意義的名稱與存取方法,以便操作時明白其含義。呼叫時可直接在參數裡引用常數,但是在取用時要使用存取方法,因為取用時隱含規則,規則都可能改變。
2009年6月16日 星期二
W14 專案的開發(6)──Component的方法設計
每一個Component Interface Method都可被視為該元件的一個Use Case,在設計時同樣以輸出輸入為起點,再決定內部的處理流程與動作。
設計中若需有其他元件的功能支援,必須是位居同一層次的元件才可以;讓同一次層次負責該項功能的元件集中管理達成功能所需的資源,可以有效減少上下層的交互關聯。如何明確切割出有對應意義的分解動作、動作要放置自己這一層還是父元件,這個作法的好壞會影響到元件變更時的彈性。應切出方法的動作沒切分而直接實作在原有方法裡,會讓多個動作混在一個方法裡;應放置在父元件的方法沒拉上去,會令方法的功能對應在錯誤的層級上。
從上而下將所有元件的方法逐一設計出來、收集每個元件內的所有方法、記錄每個元件方法與其他元件方法的關聯,這些是設計階段所要做到的事。將方法的設計依"達成目標的SOP”之思維組織,並將動作放置在正確對應的位置,會得到較有組織化的程式結構。
看過物件導向程式的九個規則這篇文章,看起來像是從程式碼的呈現上去避免或改善一些寫法。比起"看到某種狀況就改用另一種方式做",倒不如"依其需求的想法作出對應的寫法"能夠更教人明瞭其中含義。例如以下列出的幾個規則:
●每個函式裡面只能有一層縮排,如果需要多一層,請多寫一個Method去呼叫
●不要使用else這個關鍵字
●所有基本型別都包裝成物件
●保持東西輕薄(Class不超過50行,每個Package不超過10個檔案)
●使用第一級collections
遞迴設計所有流程元件的每一個方法,直到剩下要實作功能元件為止;功能元件應由該功能領域的專家設計實作或是由元件庫裡挑選適合的元件使用。經過基本設計概念課程與系統領域教學的每一個人,應該都有能力進行流程元件的設計。
設計中若需有其他元件的功能支援,必須是位居同一層次的元件才可以;讓同一次層次負責該項功能的元件集中管理達成功能所需的資源,可以有效減少上下層的交互關聯。如何明確切割出有對應意義的分解動作、動作要放置自己這一層還是父元件,這個作法的好壞會影響到元件變更時的彈性。應切出方法的動作沒切分而直接實作在原有方法裡,會讓多個動作混在一個方法裡;應放置在父元件的方法沒拉上去,會令方法的功能對應在錯誤的層級上。
從上而下將所有元件的方法逐一設計出來、收集每個元件內的所有方法、記錄每個元件方法與其他元件方法的關聯,這些是設計階段所要做到的事。將方法的設計依"達成目標的SOP”之思維組織,並將動作放置在正確對應的位置,會得到較有組織化的程式結構。
看過物件導向程式的九個規則這篇文章,看起來像是從程式碼的呈現上去避免或改善一些寫法。比起"看到某種狀況就改用另一種方式做",倒不如"依其需求的想法作出對應的寫法"能夠更教人明瞭其中含義。例如以下列出的幾個規則:
●每個函式裡面只能有一層縮排,如果需要多一層,請多寫一個Method去呼叫
●不要使用else這個關鍵字
●所有基本型別都包裝成物件
●保持東西輕薄(Class不超過50行,每個Package不超過10個檔案)
●使用第一級collections
遞迴設計所有流程元件的每一個方法,直到剩下要實作功能元件為止;功能元件應由該功能領域的專家設計實作或是由元件庫裡挑選適合的元件使用。經過基本設計概念課程與系統領域教學的每一個人,應該都有能力進行流程元件的設計。
2009年6月15日 星期一
W13 專案的開發(5)──決定完整的Component Diagram

首先要進行整個系統的元件佈置。一開始先參考架構先定義好系統的tier,再根據L05的切割層級(參考上圖)來定義layer,如此可以得到一張矩陣圖。
●分析的Component Interface必須放在專案的那一層,根據發生的地點放到對應的tier裡
●研判是否有相似度很高的Interface或Interface Method,在此先作調整
●每一個Component Interface都要繼承一個上一層級的Component Interface
●循環繼承到最基本那一層,不能有跳層或是沒有繼承的Component Interface
●一直review這張圖直到大家都沒有異議為止
系統這張Component Diagram非常地重要,因為一旦要移動位置或是調整繼承的話,基於這個靜態佈置上所作的動作設計全部會因架構變動而重新調整,影響是非常巨大的。還有在設計的時候每個元件都只需要放置一個Component Interface就好,不用顯示方法(方法可以在接下來的階段移動)。
定稿之後,可以再使用一個小工具讀出Component Diagram內所有的Component Interface與繼承關係,再呼叫Component產生工具一次鋪設出所有的元件結構。只要這個元件結構能適應未來的變動,那麼一切的工作都只有在元件與其繼承的元件內部設計而已。
●分析的Component Interface必須放在專案的那一層,根據發生的地點放到對應的tier裡
●研判是否有相似度很高的Interface或Interface Method,在此先作調整
●每一個Component Interface都要繼承一個上一層級的Component Interface
●循環繼承到最基本那一層,不能有跳層或是沒有繼承的Component Interface
●一直review這張圖直到大家都沒有異議為止
系統這張Component Diagram非常地重要,因為一旦要移動位置或是調整繼承的話,基於這個靜態佈置上所作的動作設計全部會因架構變動而重新調整,影響是非常巨大的。還有在設計的時候每個元件都只需要放置一個Component Interface就好,不用顯示方法(方法可以在接下來的階段移動)。
定稿之後,可以再使用一個小工具讀出Component Diagram內所有的Component Interface與繼承關係,再呼叫Component產生工具一次鋪設出所有的元件結構。只要這個元件結構能適應未來的變動,那麼一切的工作都只有在元件與其繼承的元件內部設計而已。
2009年6月13日 星期六
W12 自動收集或產出系統需要的資訊
在開發階段會陸續建立新的message id,一般作法是用人工將新的message id貼到properties檔案後再放上詳細的訊息內容。漏掉時就看哪一個message id不存在再另外補上。
現行的ResouceBundle作法令訊息檔的內容只能讀出而無法寫入,在基本Data Model加入PropertiesDataModelInterface為了改善這個現象,讓訊息檔可以新增並寫入。基於這個設計可以再往上包裝一個訊息元件,在開發與測試時設定參數為可增加模式,把找不到對應訊息的message id加入後立即寫回properties;在正式執行時再設定為ResouceBundle模式加快速度。
系統開發的時候還有很多自動化收集的機會,只要是用人工重覆輸入的都有機會寫出輔助工具。像是系統的參數設定也可以設計類似的作法予以自動新增、收集後群組化的Data可以利用工具自動轉出資料庫用的DDL檔案、Actor列表與Use Case列表、Actor與Use Case使用關聯可以產出權限定義資訊……等等,還有之前提過將所有Activity對應設定為Component Interface Method後再自動產出Component Interface。
分析完這次Iteration裡所有Activity並定義妥全部Component Interface後,就可以進入設計階段。
現行的ResouceBundle作法令訊息檔的內容只能讀出而無法寫入,在基本Data Model加入PropertiesDataModelInterface為了改善這個現象,讓訊息檔可以新增並寫入。基於這個設計可以再往上包裝一個訊息元件,在開發與測試時設定參數為可增加模式,把找不到對應訊息的message id加入後立即寫回properties;在正式執行時再設定為ResouceBundle模式加快速度。
系統開發的時候還有很多自動化收集的機會,只要是用人工重覆輸入的都有機會寫出輔助工具。像是系統的參數設定也可以設計類似的作法予以自動新增、收集後群組化的Data可以利用工具自動轉出資料庫用的DDL檔案、Actor列表與Use Case列表、Actor與Use Case使用關聯可以產出權限定義資訊……等等,還有之前提過將所有Activity對應設定為Component Interface Method後再自動產出Component Interface。
分析完這次Iteration裡所有Activity並定義妥全部Component Interface後,就可以進入設計階段。
2009年6月12日 星期五
W11 專案的開發(4)──Use Case的結果與訊息
做每一件事都有成功的結果或是失敗的原因,這同樣是每一個Activity所應考慮的範圍。使用者操作時必須明白操作的結果,因此每一個Activity都應該要有各自的回傳結果,在Use Case結束時顯示相關訊息讓使用者看到。
底層的錯誤要到設計時才會詳細定義,但是在使用者端還是會有明確的狀態可收集。像從密碼輸入器輸入密碼來說,使用者很明顯地可以考慮到沒有接續、無法按鍵、逾時未輸入等等的錯誤,這些都應先收集起來成為message id。
message id最好是每個Activity都擁有自己的編號而不要共用,這樣做的目的是可以在一拿到編號就知道是在哪裡發生的問題;當然,不同的id可以指定顯示相同的名稱,因為使用者只是需要知道有錯而不一定要知道在哪裡錯。密碼輸入器與鍵盤輸入的逾時理應有兩個不同的message id但是在顯示時可以只有"密碼輸入逾時"一種敍述。如果二者的message id都相同,要是哪天客戶希望二者顯示的訊息不同時,又會令人跳腳。
軟體的複雜度其實有很多是人為造成的,其中又有很大部分是把多個來源混雜成為一個定義。在系統沒有變動的時候,因為執行的結果全都正確所以這種定義並沒有問題;但若有問題或變更造成的修改落在原來的多個來源得分割為不同的定義時,真的是改的越底層就陣亡越多人。忠實地用一個定義對應一個來源是降低這類風險的最佳作法。
讓每個Activity都只擁有自己的message id就毋需製作追溯表,因為這只是一對多的擁有關係。message id與實際顯示的訊息內容是多對一的關聯,不過在實作時會因為properties的作法而被攤平為一對一。
底層的錯誤要到設計時才會詳細定義,但是在使用者端還是會有明確的狀態可收集。像從密碼輸入器輸入密碼來說,使用者很明顯地可以考慮到沒有接續、無法按鍵、逾時未輸入等等的錯誤,這些都應先收集起來成為message id。
message id最好是每個Activity都擁有自己的編號而不要共用,這樣做的目的是可以在一拿到編號就知道是在哪裡發生的問題;當然,不同的id可以指定顯示相同的名稱,因為使用者只是需要知道有錯而不一定要知道在哪裡錯。密碼輸入器與鍵盤輸入的逾時理應有兩個不同的message id但是在顯示時可以只有"密碼輸入逾時"一種敍述。如果二者的message id都相同,要是哪天客戶希望二者顯示的訊息不同時,又會令人跳腳。
軟體的複雜度其實有很多是人為造成的,其中又有很大部分是把多個來源混雜成為一個定義。在系統沒有變動的時候,因為執行的結果全都正確所以這種定義並沒有問題;但若有問題或變更造成的修改落在原來的多個來源得分割為不同的定義時,真的是改的越底層就陣亡越多人。忠實地用一個定義對應一個來源是降低這類風險的最佳作法。
讓每個Activity都只擁有自己的message id就毋需製作追溯表,因為這只是一對多的擁有關係。message id與實際顯示的訊息內容是多對一的關聯,不過在實作時會因為properties的作法而被攤平為一對一。
2009年6月11日 星期四
W10 專案的開發(3)──擬定流程與收集Activity、Data
統合看待已經找出的Use Case,接下來要詳細分析每一個Use Case內部的必要執行步驟(視為該Use Case的SOP)。進行之前的前置作業是準備系統詞彙表的收集處,這在進行分析時會逐步新增。
盡可能地收集每一個Use Case的完整執行劇本,定義出劇本中的分解動作,請記得要以使用者的角度來看待每一個Activity,同時從數個劇本中分析出必要流程與選擇流程,盡可能製作為一張Activity Diagram。只製作成一張Activity的目的是在後面要直接轉成程式。
每一個Activity如果牽涉到資料的變動,就從需求文件裡找出定義的名詞,一方面加入系統詞彙表,一方面註明Activity-Data的關聯。(目前的UML沒有這個記錄,只好自己作Activity-Data的垂直追溯表)分析完全部的Use Case後,收集的系統詞彙表可以用CRC Card的方法定義彼此的關聯,藉以產出Data Model的定義。
繪製Activity Diagram的時候如果Activity已經有了"絕對"要使用已經存在的,因為那才是實際有的關聯;如果畫成兩個就會讓關聯分開到兩邊而產生不正確的結果。Activity的package佈置就偏向設計,將類似作用的動作集合到同一個群組裡。像上面兩種密碼輸入設備的Use Case若Activity放在同一個package就較容易看出相似性。
Use Case下的Activity Diagram裡擁有的Activity可以產生Use Case-Activity垂直追溯表,也可以產生流程程式;記錄Activity-Data的關聯,可以產生Activity-Data的垂直追溯表。根據一層層的關聯,最後可以得到Use Case-Data的垂直追溯表,就能夠清楚地知道二者的完整關聯。
盡可能地收集每一個Use Case的完整執行劇本,定義出劇本中的分解動作,請記得要以使用者的角度來看待每一個Activity,同時從數個劇本中分析出必要流程與選擇流程,盡可能製作為一張Activity Diagram。只製作成一張Activity的目的是在後面要直接轉成程式。
每一個Activity如果牽涉到資料的變動,就從需求文件裡找出定義的名詞,一方面加入系統詞彙表,一方面註明Activity-Data的關聯。(目前的UML沒有這個記錄,只好自己作Activity-Data的垂直追溯表)分析完全部的Use Case後,收集的系統詞彙表可以用CRC Card的方法定義彼此的關聯,藉以產出Data Model的定義。
繪製Activity Diagram的時候如果Activity已經有了"絕對"要使用已經存在的,因為那才是實際有的關聯;如果畫成兩個就會讓關聯分開到兩邊而產生不正確的結果。Activity的package佈置就偏向設計,將類似作用的動作集合到同一個群組裡。像上面兩種密碼輸入設備的Use Case若Activity放在同一個package就較容易看出相似性。
Use Case下的Activity Diagram裡擁有的Activity可以產生Use Case-Activity垂直追溯表,也可以產生流程程式;記錄Activity-Data的關聯,可以產生Activity-Data的垂直追溯表。根據一層層的關聯,最後可以得到Use Case-Data的垂直追溯表,就能夠清楚地知道二者的完整關聯。
2009年6月10日 星期三
W09 專案的開發(2)──決定系統的主要架構
Use Case收集到一個程度,需要開始分析Use Case間的關聯,目的是檢查被定義為include或extends次數多的Use Case將之納入主要架構的設計。
直接查看Use Case的關聯(項目)看哪些拉出很多關係當然可以,不過製作出Use Case-Use Case水平追溯表(清單)會更有一目瞭然的效果。UML工具應要支援關聯的記錄與存取的API,那麼就可以撰寫工具程式直接產出為Excel檔案並註明include或extends的關係,再運用Excel的功能作排序、計數等等的運用找出適合納入主要架構的Use Case。
在主要架構裡會有些隱含的Use Case。像是在client-server架構下,如果沒有採用現成的framework勢必要自己設計一個收送的功能,即使客戶沒提也一定要有記錄log的功能,這些都是必須額外加上的Use Case。在這裡加上的Use Case大多與設計有關,必須視使用的framework予以調整到完備。另外還有一些event時間點的處理功能,也要一併納入考慮。
從UML model裡再轉換出Actor-Use Case的垂直追溯表,可以定義出執行功能的權限管理。在分析階段收集範圍後再追溯關聯,可以精確地得到相關資訊作為架構設計的依據。
直接查看Use Case的關聯(項目)看哪些拉出很多關係當然可以,不過製作出Use Case-Use Case水平追溯表(清單)會更有一目瞭然的效果。UML工具應要支援關聯的記錄與存取的API,那麼就可以撰寫工具程式直接產出為Excel檔案並註明include或extends的關係,再運用Excel的功能作排序、計數等等的運用找出適合納入主要架構的Use Case。
在主要架構裡會有些隱含的Use Case。像是在client-server架構下,如果沒有採用現成的framework勢必要自己設計一個收送的功能,即使客戶沒提也一定要有記錄log的功能,這些都是必須額外加上的Use Case。在這裡加上的Use Case大多與設計有關,必須視使用的framework予以調整到完備。另外還有一些event時間點的處理功能,也要一併納入考慮。
從UML model裡再轉換出Actor-Use Case的垂直追溯表,可以定義出執行功能的權限管理。在分析階段收集範圍後再追溯關聯,可以精確地得到相關資訊作為架構設計的依據。
2009年6月9日 星期二
W08 專案的開發(1)──收集Use Case
在開始之前,先讓觀念作點轉換:
人=Actor
事=Use Case
物=Data
時=Use Case Entry Point
地=Use Case Precondition
在系統分析時對Actor與Use Case應進行的步驟如下:
●收集全部Actor與Use Case以明確定義系統可以做的所有功能
●建立全部Actor與Use Case之間的使用關係
●分析Actor之間的使用範疇有包含關係者改為繼承
●所有Actor區分群組並定義在其所屬的Package下
●分析Use Case之間的使用範疇有包含關係者改為繼承
●分析Use Case內是否能拆解出include或extends關係的子Use Case
●所有Use Case區分群組並定義在其所屬的Package下
●明確定義每一個Use Case的發動時機
●明確定義每一個Use Case發動前的狀態
●明確定義每一個Use Case發動後的狀態
●收集每一個Use Case的所有可能劇本
在抽取共用Use Case的同時,思考的是"某種特定的使用者目的"。例如最近幫客戶設計晶片卡密碼驗證的功能,其目的是把使用者從密碼輸入器輸入的密碼傳到晶片卡模組去檢查,這雖然可以是一個獨立的Use Case,但也可以將用途切割為"取得密碼輸入器上輸入的密碼"與"將密碼送到晶片卡模組檢查"兩個Use Case,後者include前者。如果輸入密碼的方式又多了"從鍵盤輸入密碼",由於是二擇一的關係,關聯就要更改為extends。
 對設計者而言,Use Case與Activity的抽取常會混淆,Use Case必須從Actor的角度看待,其目的是"對使用者有意義的獨立行為"。上面若將不同的密碼輸入功能合併為一個"從輸入設備輸入密碼"就會有點模糊,因為輸入設備只是個概括的名詞(除非再另外定義輸入設備包括哪些);若在其他功能內只允許用密碼輸入器輸入密碼時,這個Use Case就會變為不合用,重新定一個會造成功能重覆,修改原來的又怕會影響之前的Use Case造成問題。
對設計者而言,Use Case與Activity的抽取常會混淆,Use Case必須從Actor的角度看待,其目的是"對使用者有意義的獨立行為"。上面若將不同的密碼輸入功能合併為一個"從輸入設備輸入密碼"就會有點模糊,因為輸入設備只是個概括的名詞(除非再另外定義輸入設備包括哪些);若在其他功能內只允許用密碼輸入器輸入密碼時,這個Use Case就會變為不合用,重新定一個會造成功能重覆,修改原來的又怕會影響之前的Use Case造成問題。
沒有作好一對一的分析與設計,就常會有這樣的兩難局面。
人=Actor
事=Use Case
物=Data
時=Use Case Entry Point
地=Use Case Precondition
在系統分析時對Actor與Use Case應進行的步驟如下:
●收集全部Actor與Use Case以明確定義系統可以做的所有功能
●建立全部Actor與Use Case之間的使用關係
●分析Actor之間的使用範疇有包含關係者改為繼承
●所有Actor區分群組並定義在其所屬的Package下
●分析Use Case之間的使用範疇有包含關係者改為繼承
●分析Use Case內是否能拆解出include或extends關係的子Use Case
●所有Use Case區分群組並定義在其所屬的Package下
●明確定義每一個Use Case的發動時機
●明確定義每一個Use Case發動前的狀態
●明確定義每一個Use Case發動後的狀態
●收集每一個Use Case的所有可能劇本
在抽取共用Use Case的同時,思考的是"某種特定的使用者目的"。例如最近幫客戶設計晶片卡密碼驗證的功能,其目的是把使用者從密碼輸入器輸入的密碼傳到晶片卡模組去檢查,這雖然可以是一個獨立的Use Case,但也可以將用途切割為"取得密碼輸入器上輸入的密碼"與"將密碼送到晶片卡模組檢查"兩個Use Case,後者include前者。如果輸入密碼的方式又多了"從鍵盤輸入密碼",由於是二擇一的關係,關聯就要更改為extends。
對設計者而言,Use Case與Activity的抽取常會混淆,Use Case必須從Actor的角度看待,其目的是"對使用者有意義的獨立行為"。上面若將不同的密碼輸入功能合併為一個"從輸入設備輸入密碼"就會有點模糊,因為輸入設備只是個概括的名詞(除非再另外定義輸入設備包括哪些);若在其他功能內只允許用密碼輸入器輸入密碼時,這個Use Case就會變為不合用,重新定一個會造成功能重覆,修改原來的又怕會影響之前的Use Case造成問題。沒有作好一對一的分析與設計,就常會有這樣的兩難局面。
2009年6月8日 星期一
W07 一般工程設計與軟體設計的不同
最近參與公司內的討論,聽到了"因為軟體本質上的不同,所以一般工程方法難以適用在軟體工程"的話語。發言者強調軟體是易變的,所以無法像工廠一樣產出固定不變的元件,同時設計也常因需求改變而隨時變動,建立在易變產出上的方法自然無法固定。
依照慣例,我還是仔細地思考了一下話中的含意。
根據自己的經驗推論,建築工程是三度空間的設計,但是軟體設計就像是四度空間的思考。像建設高速公路時只要在必要的通道上設收費站就一定收得到過路費,但是軟體即使規定好設計的層次,但任誰都可以修改為完全不經過那一個點而進入;汽車的動力從引擎經過傳動軸再傳到輪胎,但是在程式定義上直接讓動力直接轉動輪胎也是可行的作法;還有就是蓋房子時九樓往上一層一定是十樓,但是在軟體裡卻可以跳躍到任何一層,完全不受空間限制。
就製作的成本考量,一般工程需要零件時因為自己開模製作很慢於是會開好規格訂購現成零件,但是軟體元件卻因程式修改快速且成本不大,所以就在該要的地方直接作出可以應付的結果,全然不去考慮日後重用的兼容問題,反正複製一個後再改程式微調差異即可。
只注重結果的思維造成跳躍式的使用、零成本的修改(指非人力的)造成隨意的改變,雖然執行的結果相同,卻使得產出的程式碼有難以統一的多變風格、修改時也不易找出問題的真正原因。也由於同樣的需求會觸發各種不同的想法與設計,我們又無法像一般工程那樣證明哪個作法是最好的而規定下來,更增加了產出的不確定因素。
邏輯上只要檢查不出錯誤就可以說是對的。在沒法證明哪一種作法具有全部好處時,大家只能針對自己著重的方向使用自己覺得好處最多的方法。然而在對應種類眾多的時刻,選擇作法時比照一般工程嚴謹地讓每個零件限定只能接續特定的零件,是否就能適用一般工程的作法呢?
依照慣例,我還是仔細地思考了一下話中的含意。
根據自己的經驗推論,建築工程是三度空間的設計,但是軟體設計就像是四度空間的思考。像建設高速公路時只要在必要的通道上設收費站就一定收得到過路費,但是軟體即使規定好設計的層次,但任誰都可以修改為完全不經過那一個點而進入;汽車的動力從引擎經過傳動軸再傳到輪胎,但是在程式定義上直接讓動力直接轉動輪胎也是可行的作法;還有就是蓋房子時九樓往上一層一定是十樓,但是在軟體裡卻可以跳躍到任何一層,完全不受空間限制。
就製作的成本考量,一般工程需要零件時因為自己開模製作很慢於是會開好規格訂購現成零件,但是軟體元件卻因程式修改快速且成本不大,所以就在該要的地方直接作出可以應付的結果,全然不去考慮日後重用的兼容問題,反正複製一個後再改程式微調差異即可。
只注重結果的思維造成跳躍式的使用、零成本的修改(指非人力的)造成隨意的改變,雖然執行的結果相同,卻使得產出的程式碼有難以統一的多變風格、修改時也不易找出問題的真正原因。也由於同樣的需求會觸發各種不同的想法與設計,我們又無法像一般工程那樣證明哪個作法是最好的而規定下來,更增加了產出的不確定因素。
邏輯上只要檢查不出錯誤就可以說是對的。在沒法證明哪一種作法具有全部好處時,大家只能針對自己著重的方向使用自己覺得好處最多的方法。然而在對應種類眾多的時刻,選擇作法時比照一般工程嚴謹地讓每個零件限定只能接續特定的零件,是否就能適用一般工程的作法呢?
2009年6月6日 星期六
W06 做事的方法(16)──對小朋友所說的做事接物摘要
●使用一個物時一定會有一個連帶的動詞,該動詞稱之為一件事。
例如:拿剪刀、穿鞋子、背書包等。
●物要固定放在一個地方,需要的時候只要找一個地方;如果平時物隨意亂放,需要的時候就得找很多地方,而且不一定找得到。
●每一件事都有一系列的動作要做,而且要依照一定的順序。
例如:用剪刀時要將拇指與食指伸入剪刀的圈圈、把要剪的東西放在另一側的兩個剪片之間、拇指與食指用力夾起。
●直接使用一個物的事稱之為小事,包含數個小事的事稱為大事。
例如:整理書桌是大事,因為包括了整理小書架、桌面、抽屜與桌下等四件小事。
●指派一件事時要有能力把它拆解為小一點的事,並各自一直循環到最小的事為止。
例如:要你整理房間時,意思是要你整理書桌、整理書櫃、整理衣櫥與清掃地面。
●指派給你的大事拆解的定義要跟我想的一樣;當然,會先告訴你定義的範圍是什麼。
例如:要你整理房間時,不要只整理好書桌就回報說已經做好了。
●做事的範圍要看實際的物有些什麼而加以變動。
例如:現在的書桌上有小書架,如果換了一個沒有小書架的新書桌,整理書桌時就不用整理小書架。
●要能判斷自己應該做的事是否需要立即動手去做。
例如:感覺書桌有點亂時,不需要人講就應該自己收拾;睡前與出門前檢查應帶的東西是否都已放入書包。
生活上接觸得到的事物很多,要一件件都在適當的時機做而且要做得好,實在是不容易的事;大人都已經是如此,更何況心性未定的小朋友。整理出做事與接物的原則雖然可以比較明白其原理,但是對真正要做事的細節並沒有很大的幫助,因為會忘的還是會忘、不做的終究不做。理論與實作,不就是像這樣的對照嗎?
例如:拿剪刀、穿鞋子、背書包等。
●物要固定放在一個地方,需要的時候只要找一個地方;如果平時物隨意亂放,需要的時候就得找很多地方,而且不一定找得到。
●每一件事都有一系列的動作要做,而且要依照一定的順序。
例如:用剪刀時要將拇指與食指伸入剪刀的圈圈、把要剪的東西放在另一側的兩個剪片之間、拇指與食指用力夾起。
●直接使用一個物的事稱之為小事,包含數個小事的事稱為大事。
例如:整理書桌是大事,因為包括了整理小書架、桌面、抽屜與桌下等四件小事。
●指派一件事時要有能力把它拆解為小一點的事,並各自一直循環到最小的事為止。
例如:要你整理房間時,意思是要你整理書桌、整理書櫃、整理衣櫥與清掃地面。
●指派給你的大事拆解的定義要跟我想的一樣;當然,會先告訴你定義的範圍是什麼。
例如:要你整理房間時,不要只整理好書桌就回報說已經做好了。
●做事的範圍要看實際的物有些什麼而加以變動。
例如:現在的書桌上有小書架,如果換了一個沒有小書架的新書桌,整理書桌時就不用整理小書架。
●要能判斷自己應該做的事是否需要立即動手去做。
例如:感覺書桌有點亂時,不需要人講就應該自己收拾;睡前與出門前檢查應帶的東西是否都已放入書包。
生活上接觸得到的事物很多,要一件件都在適當的時機做而且要做得好,實在是不容易的事;大人都已經是如此,更何況心性未定的小朋友。整理出做事與接物的原則雖然可以比較明白其原理,但是對真正要做事的細節並沒有很大的幫助,因為會忘的還是會忘、不做的終究不做。理論與實作,不就是像這樣的對照嗎?
2009年6月5日 星期五
W05 三看簡單型Component
 運用人、事、物的想法再回頭來檢視簡單型Component。如果直接可以操作物的只有最小的事,那麼先將之定義為Action,其他無法直接操作到物的事則是不同層級的Flow;這麼一來除了最底層的動作要包裝為功能元件之外,其他各層級的流程應該都只是流程元件?!
運用人、事、物的想法再回頭來檢視簡單型Component。如果直接可以操作物的只有最小的事,那麼先將之定義為Action,其他無法直接操作到物的事則是不同層級的Flow;這麼一來除了最底層的動作要包裝為功能元件之外,其他各層級的流程應該都只是流程元件?!這樣的切割法又讓我對元件的結構有了不同想法。依這裡的思緒我應該包裝出只有Action的功能元件,使用Action的流程再另外包裝出流程元件;不過在特定需求的系統裡我也可以產出一個包裝不同流程元件與功能元件的複合式元件,依參數調整內部使用的流程元件;流程元件操作功能元件時,也可以依設定更換不同實作的功能元件。這樣的作法將可以提供更靈活、更多樣化的組裝。
程式解析工具在元件分離的情況下依然可以運作:流程元件只需要處理流程方法是原本就要做的,動作方法不需要做所以不存在也沒關係;但是功能元件內部就需要再拆解出與執行流程相關的方法,標示給工具去解析。不過基本上並沒有很大的影響。(唯有元件產生工具需要調整)
註:人、事、物的關聯一開始只是為了對小朋友講解做人做事的基本原則所整理出來的想法,卻沒料到完全適用在元件結構的應用,這是原本始料未及的。
2009年6月4日 星期四
W04 我的設計準則(6)──追溯關聯
所有的單位在操作或使用的同時就發生了關聯。無論是一對一、一對多、多對一或是多對多,關聯都是追蹤影響的最重要依據;唯有透過關聯的追蹤才能發現某個單位的變動範圍到底有多廣泛。
收集範圍與追溯關聯是在求快速開發的同時最易忽略不做的工作。由於程式碼經常變動造成使用關聯頻繁變化,使得修改追溯表的速度根本追不上變動的頻率,長久下來完全沒有人可以追蹤出任一個底層API修改之後向上隔了數個層次的Use Case到底有哪些會被影響。縱使現在的IDE工具可以查出全部的呼叫歷程,但是在出版本前的迴歸測試要如何取得幾十個變更的影響範圍?
無論人對事、事對物、地對事、時對人與事或是事與事之間的全部關聯都應該要記錄下來,不管是做事的SOP或是程式的呼叫也都有使用的關聯,如何快速列出能夠操作目標單位的全部集合雖然不易,卻是在某些狀況下必須得到的結果。程式碼中快速且正確地列出使用集合,正是我要定義程式結構的主要目的。
針對UML裡的Use Case我實測了三種UML軟體:Rose 7.0.0.0、JUDE Community 5.5與Star UML 5.0.2.1570,測試範圍是Actor與Use Case的關聯、Activity與Activity的關聯。Rose明確地標示出三種圖示與兩種關聯;JUDE連Activity都沒被視為保存的單位(這表示activity無法分析是否重用),更不用提關聯;Star UML標示出三種圖示,也在各圖示內管理自己的關聯。
忽略多個Use Case之間的使用關係時,雖然對於單一Use Case可以快速開發,但是就沒法作出最佳化的分析與設計(如果向下的層次也不追蹤使用關係的話)。使用關聯的雜亂是專案產出的品質難以控管的重要因素之一,卻是被許多人所忽略的。
收集範圍與追溯關聯是在求快速開發的同時最易忽略不做的工作。由於程式碼經常變動造成使用關聯頻繁變化,使得修改追溯表的速度根本追不上變動的頻率,長久下來完全沒有人可以追蹤出任一個底層API修改之後向上隔了數個層次的Use Case到底有哪些會被影響。縱使現在的IDE工具可以查出全部的呼叫歷程,但是在出版本前的迴歸測試要如何取得幾十個變更的影響範圍?
無論人對事、事對物、地對事、時對人與事或是事與事之間的全部關聯都應該要記錄下來,不管是做事的SOP或是程式的呼叫也都有使用的關聯,如何快速列出能夠操作目標單位的全部集合雖然不易,卻是在某些狀況下必須得到的結果。程式碼中快速且正確地列出使用集合,正是我要定義程式結構的主要目的。
針對UML裡的Use Case我實測了三種UML軟體:Rose 7.0.0.0、JUDE Community 5.5與Star UML 5.0.2.1570,測試範圍是Actor與Use Case的關聯、Activity與Activity的關聯。Rose明確地標示出三種圖示與兩種關聯;JUDE連Activity都沒被視為保存的單位(這表示activity無法分析是否重用),更不用提關聯;Star UML標示出三種圖示,也在各圖示內管理自己的關聯。
忽略多個Use Case之間的使用關係時,雖然對於單一Use Case可以快速開發,但是就沒法作出最佳化的分析與設計(如果向下的層次也不追蹤使用關係的話)。使用關聯的雜亂是專案產出的品質難以控管的重要因素之一,卻是被許多人所忽略的。
2009年6月3日 星期三
W03 我的設計準則(5)──收集範圍
分析設計時的人、事、時、地、物都需要各自收集範圍以便定義各自的邊界,收集的好處在於接觸到某一個單位的同時能夠立即知道它是否在該單位的集合,已存在的話可以直接重用,不存在的話就必須另外建立。這個方式對於reuse的幫助很大。
收集起來的單位數會非常多,因而需要建立各自的分類方法依特性分群組放置,這樣可以加快定位的速度;當然加上搜尋的功能也很好。在"事"的分類佈置可以衍伸為Package的定義,搭配Component工具就能夠將所有新"事"的定義直接匯出元件程式結構,舊"事"則依設定參考原有的元件功能。
觀察到很多SA、SD與PG的想法都偏向輸入與輸出,在意得到什麼樣的輸入且應有什麼樣的輸出而忽略了處理輸入輸出的做事流程。在明確定義做事流程的方式下可以得到處理的SOP,進而與其他做事流程共同抽取相同的部分成為API;忽略做事流程的作法下任何想法都以湊出對的結果為目標,雖然效率很好,但是僵化、綑綁與難修改都會跟隨其中。
這是可以套用在任何地方的想法。分析時一個群組(例如會計室)收集的應做之事就是該群組的功能,一個單位(例如出納)收集的應做之事就是這個單位的責任;每一個群組與每一個單位都依其特性給予它應有的責任範圍,並要求該責任只有這個單位具有而其他單位都不得處理。
每個部份要先依其大小意義定出有多少層次,在收集範圍的同時都要依層級分開收集在不同的層次,唯有將所有單位都分門別類地放置的一致化作法才能夠再定義出更上一層的存取規則。這也正是各種工具程式的操作依據。
收集起來的單位數會非常多,因而需要建立各自的分類方法依特性分群組放置,這樣可以加快定位的速度;當然加上搜尋的功能也很好。在"事"的分類佈置可以衍伸為Package的定義,搭配Component工具就能夠將所有新"事"的定義直接匯出元件程式結構,舊"事"則依設定參考原有的元件功能。
觀察到很多SA、SD與PG的想法都偏向輸入與輸出,在意得到什麼樣的輸入且應有什麼樣的輸出而忽略了處理輸入輸出的做事流程。在明確定義做事流程的方式下可以得到處理的SOP,進而與其他做事流程共同抽取相同的部分成為API;忽略做事流程的作法下任何想法都以湊出對的結果為目標,雖然效率很好,但是僵化、綑綁與難修改都會跟隨其中。
這是可以套用在任何地方的想法。分析時一個群組(例如會計室)收集的應做之事就是該群組的功能,一個單位(例如出納)收集的應做之事就是這個單位的責任;每一個群組與每一個單位都依其特性給予它應有的責任範圍,並要求該責任只有這個單位具有而其他單位都不得處理。
每個部份要先依其大小意義定出有多少層次,在收集範圍的同時都要依層級分開收集在不同的層次,唯有將所有單位都分門別類地放置的一致化作法才能夠再定義出更上一層的存取規則。這也正是各種工具程式的操作依據。
2009年6月2日 星期二
W02 Use Case裡的人、事、時、地、物

"人"必須透過"事"才能操作"物"是分析與設計的根本,某個物被改變"必然"是因為某個人做了某件事,確定了這個關係後就可以很容易地接受Actor、Use Case與Data的說法。再加上該件事發生的時機與執行的地方,就構成了人、事、時、地、物的思考模式。
在系統裡通常會用角色來取代Actor,當某個角色發動做某件事時,權限控管會根據角色與功能的關係決定是否允許。功能被執行後會進行一連串的動作,執行動作的流程會被編輯為Activity Diagram,而被執行的動作就是Activity。

事件可以區分為一次操作一物的"小事"與一次包括許多小事的"大事"。舉例來說,整理書房是一件很大的事,至少包含整理書桌、整理書櫃、清掃地面幾件較小的事;整理書桌又包含整理書架、整理桌面與整理抽屜三件明確的小事,每件小事都關聯到一個物件。切割範圍的思維一致後,每個人對事物切割範圍的誤差才不致大大。
單位切割之後要處理的是每個單位的分類方式,如何訂定各種存放類別、單位存放時如何分類也是必須同步的想法;另外單位之間原有存在的關聯都是必須保存下來的資訊。
2009年6月1日 星期一
W01 公司應有的文化──所有人員的想法與行為一致
公司的CMMI導入團隊說現在訂立的規範都只強調精神,各專案要根據自己的特性予以調適;由於沒有提供一個基本的範本,造成每個專案各做各的沒有交集,等於是沒有規範。也由於各個專案作法與產出不同,卻擁有相似的問題──沒人看得懂,修改沒品質,無人想維護。
敏捷開發的原則非常強調開發成員間的想法同步。2006年開發UI編輯器時小組裡有四個人,我們每天上午十一點與下午五點都各開半小時內的會議,內容為核對進度、提出問題與回饋作法;目的是讓所有人都對不熟的技術與平台獲得同樣的了解,當時我覺得效果相當好。可是當時的主管有天卻問我這句話:你們一天到晚常常開會,這樣進度來得及嗎?
一間較大公司內會有數個專案,一個較大的專案下會有數個小組,把眼光提升到公司的層級就會有一個疑問:要怎麼做才能讓公司內所有專案、所有小組、所有角色產出的內容與品質接近一致?採用CMMI的流程控管會有許多繁瑣的手續耗費開發的時間,使用快速的方法可以讓開發迅速卻讓其他人難以瞭解系統。
無論是人為的控制或是自由的開發都有可能因為每個人的思考方式不同而導致結果有差異。要能同步所有人的思維,應從瞭解設計的本質開始,再搭配每一個階段、每一個步驟為什麼要這樣做,這樣做有什麼樣的好處與壞處著手。讓所有人打從心裡相信雖然自己多花一點時間,卻能夠留下足夠資訊達成各個面向的要求。
做事方法與思考原則的完全一致化,會訓練出有紀律的團隊,同時會有讓所有成員一看就懂的產出。
敏捷開發的原則非常強調開發成員間的想法同步。2006年開發UI編輯器時小組裡有四個人,我們每天上午十一點與下午五點都各開半小時內的會議,內容為核對進度、提出問題與回饋作法;目的是讓所有人都對不熟的技術與平台獲得同樣的了解,當時我覺得效果相當好。可是當時的主管有天卻問我這句話:你們一天到晚常常開會,這樣進度來得及嗎?
一間較大公司內會有數個專案,一個較大的專案下會有數個小組,把眼光提升到公司的層級就會有一個疑問:要怎麼做才能讓公司內所有專案、所有小組、所有角色產出的內容與品質接近一致?採用CMMI的流程控管會有許多繁瑣的手續耗費開發的時間,使用快速的方法可以讓開發迅速卻讓其他人難以瞭解系統。
無論是人為的控制或是自由的開發都有可能因為每個人的思考方式不同而導致結果有差異。要能同步所有人的思維,應從瞭解設計的本質開始,再搭配每一個階段、每一個步驟為什麼要這樣做,這樣做有什麼樣的好處與壞處著手。讓所有人打從心裡相信雖然自己多花一點時間,卻能夠留下足夠資訊達成各個面向的要求。
做事方法與思考原則的完全一致化,會訓練出有紀律的團隊,同時會有讓所有成員一看就懂的產出。
2009年5月29日 星期五
V22 程式碼註解解析工具的後續連結
 這張是程式碼與相關文件經過程式碼解析工具處理後預想的關係圖,在理想的作法之下應該滿足全部相關部分的需要。簡單的說明如下:
這張是程式碼與相關文件經過程式碼解析工具處理後預想的關係圖,在理想的作法之下應該滿足全部相關部分的需要。簡單的說明如下:●UML工具:從UML工具內讀取有用的資訊加以轉換到其他產出,或是從程式碼裡取得必要的資訊放到UML工具裡。除了程式碼與Model之間原有generate code與reverse之外,可以再擴充其他元素的雙向存取。
●各種文件:主要是要產出符合CMMI需要的設計規格書與追溯表,必要時也可以有流程圖。如果專案上有其他的需要,也能夠另外再設計不同的產出。一般會匯出的文件格式會是word、excel與pdf。
●元件庫:專案中適合reuse的功能元件要有納入元件庫的機制,屆時需要產出軟體元件的規格;專案在使用軟體元件時可以再匯入之前產出的元件文件作進一步的分析與追溯。
●問題單系統:搜尋特定的修改註解取得修改的程式與說明,自動填寫到問題單系統內同一單號的說明。這需要問題單系統提供API或是直接修改其資料檔內容。
●版本資訊:搜尋指定時間範圍的修改註解取得修改的範圍與問題原因(搭配問題單系統取得),以及受到影響的所有方法作為參考資訊。
●知識庫:搜尋指定時間範圍的修改註解取得修改說明,列出作為是否進入知識庫的備選。知識庫管理人員可以取得知識備選清單並與現有的知識庫內容作比對,以決定要不要放入知識庫並加上補充說明。這需要知識庫系統提供API或是直接修改其資料檔內容。
●系統測試:參考判斷條件、使用關聯與流程圖來決定如何編排測試個案,以涵蓋每一種條件變化的流程為目標。
2009年5月28日 星期四
V21 敏捷開發原則與CMMI精神的共存
閒暇時偶而會與同事或管理階層的人談起開發時程與彈性設計的問題,也會上網搜尋一下目前其他人對於設計的看法(中文網頁裡的)。得到的大致說法都是敏捷開發的原則是以快速滿足需求與變化為目標,而CMMI的精神會以檢驗各個步驟的產出來確認軟體製程的各個階段;前者認為軟體設計是多變的心智活動,後者則相信軟體可以像產品一樣由工廠來開發組裝。
某天與其他部門主管聊起時,談到OOAD設計與這兩者的關係,我強調說設計的物件能否完整地一對一對應到真實的物件才是最重要的關鍵。今天一個有三層結構關係的物件在設計的時候被縮減為一層,無論用什麼樣的方法論作出來的程式都會在需要切割時出問題的一天;反過來說只要物件結構能正確對應,無論用什麼樣的方式開發都不會出現切割的問題。
乍看起來敏捷開發與CMMI是沒有交集的,快速開發可能造成佈置的雜亂(所以需要重構來調整),設計的完整會耗費許多時間製作文件,因此幾乎所有人都不認為它們可以相輔相成。經過這兩年的思索,我認為唯有使用"固定且具有彈性的統一軟體結構"才能滿足快速與完整的並存,同時再夾帶讓全部開發人員(不限同一個開發團隊)能快速明白設計概念的好處。
將軟體切割為靜態結構佈置與動態方法設計,作好完整的靜態結構佈置後以敏捷開發的原則進行動態方法設計,通過各個階段測試之後再運用工具程式解析以產生CMMI需要的文件。這些想法的關鍵都已經在這兩年陸續在實際工作裡加以驗證,有絕對的把握可以實現。
雖然要事先開發好所有的工具的確需要不少時間,不過在下一章會先說明專案開發時大致的流程、作法與需要的工具,並且構築出一個完整的開發roadmap。
某天與其他部門主管聊起時,談到OOAD設計與這兩者的關係,我強調說設計的物件能否完整地一對一對應到真實的物件才是最重要的關鍵。今天一個有三層結構關係的物件在設計的時候被縮減為一層,無論用什麼樣的方法論作出來的程式都會在需要切割時出問題的一天;反過來說只要物件結構能正確對應,無論用什麼樣的方式開發都不會出現切割的問題。
乍看起來敏捷開發與CMMI是沒有交集的,快速開發可能造成佈置的雜亂(所以需要重構來調整),設計的完整會耗費許多時間製作文件,因此幾乎所有人都不認為它們可以相輔相成。經過這兩年的思索,我認為唯有使用"固定且具有彈性的統一軟體結構"才能滿足快速與完整的並存,同時再夾帶讓全部開發人員(不限同一個開發團隊)能快速明白設計概念的好處。
將軟體切割為靜態結構佈置與動態方法設計,作好完整的靜態結構佈置後以敏捷開發的原則進行動態方法設計,通過各個階段測試之後再運用工具程式解析以產生CMMI需要的文件。這些想法的關鍵都已經在這兩年陸續在實際工作裡加以驗證,有絕對的把握可以實現。
雖然要事先開發好所有的工具的確需要不少時間,不過在下一章會先說明專案開發時大致的流程、作法與需要的工具,並且構築出一個完整的開發roadmap。
2009年5月27日 星期三
V20 修改的追溯(3)──系統追溯總表與關聯搜尋工具
在系統要出一個新的版本時,輸入上次出版日期與這次出版日期,修改註解收集工具應該要能收集到程式碼內的所有修改記錄,進而輸出在Use Case層面的追溯總表。這份表格可以作為迴歸測試的參考標準。在理論上還可以更進一步作出每一個修改所影響的是呼叫它的方法裡哪一個判斷條件,這將是最為精確的結果。
應該追溯的當然不只是系統的Use Case,呼叫的歷程中每一個部分都應該要能夠被定義出來,這樣才能夠對中間的所有元件重作單元測試。如果有作好Unit Test的話只要知道元件後自動重作全部測試觀察是否有錯誤,然而有時還是得知道到底是哪裡被影響到。目前的IDE工具可以直接看到呼叫指定方法的全部關聯,卻仍無法向下呼叫的關係。
我的想法是製作一個工具,先分析出系統元件間的使用關聯。使用者在系統元件樹狀圖裡選擇指定的數個方法(或從產出的修改彙總表匯入)後,就直接在向上區與向下區用樹狀結構的方式表示各個相關的呼叫結構。其間也可以用滑鼠點選擇集合裡的任一個方法限制只顯示與之有關的。最後還可以匯出找到的關聯集合作為參考或正式記錄。
應該追溯的當然不只是系統的Use Case,呼叫的歷程中每一個部分都應該要能夠被定義出來,這樣才能夠對中間的所有元件重作單元測試。如果有作好Unit Test的話只要知道元件後自動重作全部測試觀察是否有錯誤,然而有時還是得知道到底是哪裡被影響到。目前的IDE工具可以直接看到呼叫指定方法的全部關聯,卻仍無法向下呼叫的關係。
我的想法是製作一個工具,先分析出系統元件間的使用關聯。使用者在系統元件樹狀圖裡選擇指定的數個方法(或從產出的修改彙總表匯入)後,就直接在向上區與向下區用樹狀結構的方式表示各個相關的呼叫結構。其間也可以用滑鼠點選擇集合裡的任一個方法限制只顯示與之有關的。最後還可以匯出找到的關聯集合作為參考或正式記錄。
2009年5月26日 星期二
V19 修改的追溯(2)──時間與空間交集的修改集合
對系統來說雖然切割的單位是Package,但是在意義上應追溯到Method才是最精確的。然而一般的作法光是追溯Class都已經很難正確,更何況是要到Method。一個略具規模的完整Class-Class的追溯表大概可以到1000 X 1000的矩陣,到Method更不用談了;不過追溯並不是一次要看全部內容,而且侷限於需要看的部分。
需要看的追溯通常有兩種:從上往下的追溯與從下往上的追溯。想要從功能面上取出一個獨立的模組或功能時同時需要哪些物件,可用自上往下的使用關聯取得完全的集合;想要從中間一個方法得知在這個系統裡,總共有哪些地方的方法直接或間接呼叫到它,就是從下往上的追溯。理想的追溯是指定一個方法之後同時追查出所有向下與向上的全部關聯。
對於修改歷程的集合,除了要可以定義變動程式碼的範圍之外還要可以調整時間的範圍,這樣才能夠定義時間(像版本之間的時間)進而找出變更的空間(異動程式與向上追溯)。在任意變換的定義時間帶與定義的Project裡找出變更與影響集合用人工是很難作好的,無法正確地定義影響的範圍正是為什麼造成品質不佳的原因。
把這個很花時間的功能自動化後,任何時候都可以查出當時有哪些修改;唯一要多作的只是多註記問題單的編號註解。
需要看的追溯通常有兩種:從上往下的追溯與從下往上的追溯。想要從功能面上取出一個獨立的模組或功能時同時需要哪些物件,可用自上往下的使用關聯取得完全的集合;想要從中間一個方法得知在這個系統裡,總共有哪些地方的方法直接或間接呼叫到它,就是從下往上的追溯。理想的追溯是指定一個方法之後同時追查出所有向下與向上的全部關聯。
對於修改歷程的集合,除了要可以定義變動程式碼的範圍之外還要可以調整時間的範圍,這樣才能夠定義時間(像版本之間的時間)進而找出變更的空間(異動程式與向上追溯)。在任意變換的定義時間帶與定義的Project裡找出變更與影響集合用人工是很難作好的,無法正確地定義影響的範圍正是為什麼造成品質不佳的原因。
把這個很花時間的功能自動化後,任何時候都可以查出當時有哪些修改;唯一要多作的只是多註記問題單的編號註解。
2009年5月25日 星期一
V18 修改的追溯(1)──修改處的註解與收集程式
一個系統上的問題通常會在問題單系統裡建立一張問題單並給予一個編號,程式人員會針對解決這個問題而修改一些程式碼。以往的作法是填寫一份問題報告,描述問題的產出與解法,並記錄改了哪些程式;程式部分也另外填寫到一份release notes等到要上新的版本時,可以知道共有哪些程式需要更換。
版本-問題單-修改的程式是除錯與維護時物件的關聯,其中最基本的是問題單與修改程式間的關係。假設有一張問題單單號1234的錯誤在於初始值給錯,那麼就用根據本章前面所提的註解原則來修改程式並填寫註解。
/*
* 記錄索引的變數給予初值.
*/
// index = -1; /* IR=1234 */
index = 0; /* IR=1234 */
原則固定之後,註解處理工具就需要多設計一個程式來收集這些資訊。從最底層起要做的事有:
●每個Method裡為了每張問題單所修改的全部程式碼。
●每個Method內處理過的問題單集合。(回填到Method註解)
●每個Class內處理過的問題單集合。(回填到Class註解)
●每個Component內處理過的問題單集合。(回填到Component Interface註解)
●每個Package、Project直到workspace內處理過的問題單集合。(回填到對應的註解說明)
確認每個階層可以收集到所有填寫的修改註解,同時更新到Method、Class的註解裡是這個階段所要達成的目標。
版本-問題單-修改的程式是除錯與維護時物件的關聯,其中最基本的是問題單與修改程式間的關係。假設有一張問題單單號1234的錯誤在於初始值給錯,那麼就用根據本章前面所提的註解原則來修改程式並填寫註解。
/*
* 記錄索引的變數給予初值.
*/
// index = -1; /* IR=1234 */
index = 0; /* IR=1234 */
原則固定之後,註解處理工具就需要多設計一個程式來收集這些資訊。從最底層起要做的事有:
●每個Method裡為了每張問題單所修改的全部程式碼。
●每個Method內處理過的問題單集合。(回填到Method註解)
●每個Class內處理過的問題單集合。(回填到Class註解)
●每個Component內處理過的問題單集合。(回填到Component Interface註解)
●每個Package、Project直到workspace內處理過的問題單集合。(回填到對應的註解說明)
確認每個階層可以收集到所有填寫的修改註解,同時更新到Method、Class的註解裡是這個階段所要達成的目標。
2009年5月22日 星期五
V17 Sequence Diagram──一次只能表達一種呼叫順序的圖表
雖然Sequence Diagram是UML的一種標準圖,但是由於它只能表示在某種情況(通常是導向正確結果的流程)下的物件互動順序,沒有辦法表示分歧點判斷後的差異,因此我並不喜歡使用這張圖而寧願用Activity Diagram或流程圖來完整地表達。
有位曾共事的同事在討論時喜歡用Sequence Diagram表達物件的關係,無可否認地依序表達物件的合作關係時是非常清楚的,轉換為Collaboration Diagram時也可以立即知道達成功能時所需物件的關聯,然而無法立即由一張圖就知道整個功能的處理流程是十分不便的。
在不想繪製這張圖時,許多IDE工具提供在執行同時產生Sequence Diagram的功能。在IBM RSA 7.0(含)之前的版本是從頭到尾的呼叫流程都擠在一張圖而無法分割,這樣的圖表更是難以看懂其中的設計。不過這麼鉅細靡遺的圖表放到CMMI的設計規格書裡倒是挺適合的──反正許多規格書都只需要填滿指定的章節就好,並沒有人要求內容的正確性與適當性。
我認為Sequence Diagram如果增加branch node與merge node的定義後就會非常理想,但若是在分析設計Method的同時,把每個Activity都一對一對應到一個呼叫的Method的話,Activity Diagram就等同於Sequence Diagram的意義而不需要再重覆製作。而且這張圖表可以藉由程式流程Data Model自動產生出符合該Method層級的流程圖,比較起來反而可以省下更多製作圖表的時間。(若應用swinlane區隔出每一個不同activity所存在的物件,同樣也能夠產生Collaboration Diagram)
對於這種區解原意的應用,應該會有理論擁護者發出不平的聲音。理論難以應用時應該修改理論使之符合實用,而非堅持大師的想法造成無法進行的瓶頸。
有位曾共事的同事在討論時喜歡用Sequence Diagram表達物件的關係,無可否認地依序表達物件的合作關係時是非常清楚的,轉換為Collaboration Diagram時也可以立即知道達成功能時所需物件的關聯,然而無法立即由一張圖就知道整個功能的處理流程是十分不便的。
在不想繪製這張圖時,許多IDE工具提供在執行同時產生Sequence Diagram的功能。在IBM RSA 7.0(含)之前的版本是從頭到尾的呼叫流程都擠在一張圖而無法分割,這樣的圖表更是難以看懂其中的設計。不過這麼鉅細靡遺的圖表放到CMMI的設計規格書裡倒是挺適合的──反正許多規格書都只需要填滿指定的章節就好,並沒有人要求內容的正確性與適當性。
我認為Sequence Diagram如果增加branch node與merge node的定義後就會非常理想,但若是在分析設計Method的同時,把每個Activity都一對一對應到一個呼叫的Method的話,Activity Diagram就等同於Sequence Diagram的意義而不需要再重覆製作。而且這張圖表可以藉由程式流程Data Model自動產生出符合該Method層級的流程圖,比較起來反而可以省下更多製作圖表的時間。(若應用swinlane區隔出每一個不同activity所存在的物件,同樣也能夠產生Collaboration Diagram)
對於這種區解原意的應用,應該會有理論擁護者發出不平的聲音。理論難以應用時應該修改理論使之符合實用,而非堅持大師的想法造成無法進行的瓶頸。
2009年5月21日 星期四
V16 流程的存取(3)──從程式流程Data Model產出流程圖
一個Component Interface Method的實作會產生一組對應的程式流程Data Model,這個集合的內容應該產生一張對應的流程圖。同一個Component的流程圖要收集在一起,因為那是元件內部的完整流程說明文件。
處理的過程其實不難,依下面的順序進行:(依集合內程式流程Data Model的順序)
●逐一在流程圖上建立對應的節點,並標示節點名稱。
●根據程式流程Data Model內的關聯定義建立節點間的關聯,並標示關聯資訊。
●自動排版所有節點。
●自動命名與存檔。
困難的其實在於工具的配合,在2009/04看過幾套UML工具只有JUDE/Professional有支援API存取物件(US$ 280,但不知是否支援繪圖),其他像Rational Rose、StartUML、JUDE/Community都只能在產生報表時選取輸出的物件而沒有提供操作的API;即使是Microsoft Visio也只有data link API而沒有提供圖表的。
目前的潮流是先畫流程圖再產生程式,如果找不到用程式產生流程圖的免費工具,未來在實作這個功能時真的得另外製作一個用API畫流程圖的工具了。
處理的過程其實不難,依下面的順序進行:(依集合內程式流程Data Model的順序)
●逐一在流程圖上建立對應的節點,並標示節點名稱。
●根據程式流程Data Model內的關聯定義建立節點間的關聯,並標示關聯資訊。
●自動排版所有節點。
●自動命名與存檔。
困難的其實在於工具的配合,在2009/04看過幾套UML工具只有JUDE/Professional有支援API存取物件(US$ 280,但不知是否支援繪圖),其他像Rational Rose、StartUML、JUDE/Community都只能在產生報表時選取輸出的物件而沒有提供操作的API;即使是Microsoft Visio也只有data link API而沒有提供圖表的。
目前的潮流是先畫流程圖再產生程式,如果找不到用程式產生流程圖的免費工具,未來在實作這個功能時真的得另外製作一個用API畫流程圖的工具了。
2009年5月20日 星期三
V15 流程的存取(2)──Flow與Action方法的處理原則
處理的範圍限定在Component內部。首先要將Component內部的Implementation與Flow兩類方法收集起來,這是流程進行的範圍;Action方法原則上不用處理。倘使Action方法也有製作流程的需要,則把被Flow呼叫的Action視為範圍再進行Action方法的流程分析。
一開始要定義一個迴圈逐一處理每一個Component Interface Method,先進入Implementation方法再依程式流程進行,每遇一個定義上的node就產生一個對應節點收集資訊。在流程上,只要是Implementation與Flow方法的就必須進入該方法處理;在動作上,如果呼叫了Action方法或是其他Package的方法則註解為一個activity node而不要進入該方法。不應該遞迴處理到其他Package的內容,因為那會使得流程記錄得太細而失焦,難以看出現在層級應該注意的過程。
某Flow方法在內部呼叫同Component的另一個Flow方法時,該建立一個中間點將兩個Flow分成兩張圖來存放?或是不管呼叫的間隙而將全部的流程串成一張圖呢?這應該選擇後者。一個Component Interface Method的實作是一組獨立流程,部分流程會被抽成另一個Flow方法是因為它們在意義屬於某一特定目的,但仍是原來流程的一部分,因此串成一張完整的圖會比較易讀;況且圖是自動產生的,也不會太大張。
一個Component處理後再接著換另外一個,直到指定範圍內所有的Component都被處理完為止,這樣我們就拿到了所有Component Interface Method的程式流程Data Model。這時要設計一個中間檔的存放機制讓這些程式流程Data Model存成檔案,日後要轉換時再讀入處理而不需要每次都重新處理。
一開始要定義一個迴圈逐一處理每一個Component Interface Method,先進入Implementation方法再依程式流程進行,每遇一個定義上的node就產生一個對應節點收集資訊。在流程上,只要是Implementation與Flow方法的就必須進入該方法處理;在動作上,如果呼叫了Action方法或是其他Package的方法則註解為一個activity node而不要進入該方法。不應該遞迴處理到其他Package的內容,因為那會使得流程記錄得太細而失焦,難以看出現在層級應該注意的過程。
某Flow方法在內部呼叫同Component的另一個Flow方法時,該建立一個中間點將兩個Flow分成兩張圖來存放?或是不管呼叫的間隙而將全部的流程串成一張圖呢?這應該選擇後者。一個Component Interface Method的實作是一組獨立流程,部分流程會被抽成另一個Flow方法是因為它們在意義屬於某一特定目的,但仍是原來流程的一部分,因此串成一張完整的圖會比較易讀;況且圖是自動產生的,也不會太大張。
一個Component處理後再接著換另外一個,直到指定範圍內所有的Component都被處理完為止,這樣我們就拿到了所有Component Interface Method的程式流程Data Model。這時要設計一個中間檔的存放機制讓這些程式流程Data Model存成檔案,日後要轉換時再讀入處理而不需要每次都重新處理。
2009年5月19日 星期二
V14 流程的存取(1)──程式流程Data Model
接下來討論的是程式流程圖的產生。由於繪製流程圖的工具非常地多樣化,所以不應該直接把程式流程輸出為流程圖,而應該先設計程式流程Data Model先將程式碼的流程轉入,然後再根據實際使用的流程圖工具製作匯出程式。
一開始應該先分析流程圖裡面所包含的元件種類以建立對應的物件。我參考的是Activity Diagram內使用的圖形,能夠用最簡單地圖形表達出設計的意義可以降低複雜度。
●start node - Flow方法的進入點
●end node - 遇到return或是走到Flow方法的盡頭
●branch node - 每個判斷條件會對應到一或多個
●merge node - 每個判斷條件block的終點
●activity node - 不在判斷條件裡的動作
Flow方法裡只有變數宣告(activity node)、執行Method(activity node)與判斷條件(branch node、merge node)等三類敍述,判斷條件內除了java的關鍵字外就只有判斷式(branch node、merge node裡的condition),因此Flow方法的敍述在理論上都能夠對應轉換為程式流程Data Model。
每一個程式流程Data Model都還要包含指向下一個node的指標(end node)沒有,branch node得有分歧條件與對應節點的集合才能建立正確的資訊。在非分歧條件下的程式碼毌須解析內容,只要把找到的註解都轉換成一個activity node即可。
一開始應該先分析流程圖裡面所包含的元件種類以建立對應的物件。我參考的是Activity Diagram內使用的圖形,能夠用最簡單地圖形表達出設計的意義可以降低複雜度。
●start node - Flow方法的進入點
●end node - 遇到return或是走到Flow方法的盡頭
●branch node - 每個判斷條件會對應到一或多個
●merge node - 每個判斷條件block的終點
●activity node - 不在判斷條件裡的動作
Flow方法裡只有變數宣告(activity node)、執行Method(activity node)與判斷條件(branch node、merge node)等三類敍述,判斷條件內除了java的關鍵字外就只有判斷式(branch node、merge node裡的condition),因此Flow方法的敍述在理論上都能夠對應轉換為程式流程Data Model。
每一個程式流程Data Model都還要包含指向下一個node的指標(end node)沒有,branch node得有分歧條件與對應節點的集合才能建立正確的資訊。在非分歧條件下的程式碼毌須解析內容,只要把找到的註解都轉換成一個activity node即可。
2009年5月18日 星期一
V13 自動補齊註解(8)──匯入底層元件的註解產出
在workspace裡的程式碼都可以使用工具達到上述的註解產出,但是在使用軟體元件的同時,要是那些Jar File有改變的時候該怎麼辦?要怎麼找出系統被那些影響變動的範圍呢?很抱歉,截至目前為此沒有辦法──除非再設計一個功能。
想像把一組很多層次的Package從中切分為二,上面放在workspace裡而下面是Jar File,差異就在於沒辦法取到下面的註解加以分析並放入集合。那麼取代的方案就是:擁有元件程式碼的人應該先分析註解並產出結果,專案就在工具裡匯入產出結果成為註解集合再繼續處理,這樣就可以解決這個問題。(匯入不能只限一組,要能同時匯入多組資料)
匯出與匯入都應該以上述所有註解分析結果為範圍,感覺就像真的剛處理出來的結果一樣才不會有落差。在優先度來說,專案的改變要比元件的改變容易發生,所以這個功能的需要就沒那麼急迫。
直到這裡,才算完成所有與註解相關的自動化部分。
想像把一組很多層次的Package從中切分為二,上面放在workspace裡而下面是Jar File,差異就在於沒辦法取到下面的註解加以分析並放入集合。那麼取代的方案就是:擁有元件程式碼的人應該先分析註解並產出結果,專案就在工具裡匯入產出結果成為註解集合再繼續處理,這樣就可以解決這個問題。(匯入不能只限一組,要能同時匯入多組資料)
匯出與匯入都應該以上述所有註解分析結果為範圍,感覺就像真的剛處理出來的結果一樣才不會有落差。在優先度來說,專案的改變要比元件的改變容易發生,所以這個功能的需要就沒那麼急迫。
直到這裡,才算完成所有與註解相關的自動化部分。
2009年5月15日 星期五
V12 自動補齊註解(7)──產生Interface Method的使用追溯表
每個Package的使用關聯集合如果都建立起來,除了可以快速地向下找到有關係的Package之外,還能夠搜尋到所有向上的被呼叫關係。如果有耐心作完全部的設計,追溯甚至還可以精確到Interface Method的程度。
公司定義的CMMI文件裡追溯表格只有三種:Use Case-User Case(水平)、Use Case-Class(垂直)、Class-Class(水平),這對於實際的系統設計來說是沒有對應且涵蓋度不足的。在我看來至少要有這些追溯表格:Use Case-Use Case(水平)、Use Case-Package(垂直)、Package-Package(水平)、Package-Class(垂直)、Class-Class(水平)。
仔細分析的話,可以發現追溯的根本是依層級來記錄使用關聯,Package-Class、Class-Class收集的是Component內部的使用關聯;Package-Package則必須收集每一個Component之間的使用關聯加以記錄;Use Case-Use Case、Use Case-Package這兩張表格在意義上也等同於Package-Package的作法(Use Case的入口方法都被收集在特定Package下)。
最完美的使用追溯表應該記錄到Method間的呼叫,但是攤開來看的話可能會大得太離譜。為了因應實際會需要尋找指定某個Method後列出呼叫它以及它所呼叫的所有關聯,勢必需要再設計一個查詢工具,指定一些Method後列出上下的全部使用關聯。唯有這麼作才能精確地圈選出修改後所有的影響範圍。
公司定義的CMMI文件裡追溯表格只有三種:Use Case-User Case(水平)、Use Case-Class(垂直)、Class-Class(水平),這對於實際的系統設計來說是沒有對應且涵蓋度不足的。在我看來至少要有這些追溯表格:Use Case-Use Case(水平)、Use Case-Package(垂直)、Package-Package(水平)、Package-Class(垂直)、Class-Class(水平)。
仔細分析的話,可以發現追溯的根本是依層級來記錄使用關聯,Package-Class、Class-Class收集的是Component內部的使用關聯;Package-Package則必須收集每一個Component之間的使用關聯加以記錄;Use Case-Use Case、Use Case-Package這兩張表格在意義上也等同於Package-Package的作法(Use Case的入口方法都被收集在特定Package下)。
最完美的使用追溯表應該記錄到Method間的呼叫,但是攤開來看的話可能會大得太離譜。為了因應實際會需要尋找指定某個Method後列出呼叫它以及它所呼叫的所有關聯,勢必需要再設計一個查詢工具,指定一些Method後列出上下的全部使用關聯。唯有這麼作才能精確地圈選出修改後所有的影響範圍。
2009年5月14日 星期四
V11 自動補齊註解(6)──依階層收集Method註解
Method是底層的行為單位,再往上的組織階層有Class、Package。既然Package擁有多個Class,而Class又擁有多個Method,那麼在集合的層級上匯總集合元素的資訊也是應該具備的功能。
回顧前面的章節所做的事,在彙總註解內容時首先要作到的是格式檢查與基本資訊的產生,第二是宣告時繼承與實作對象的註解(Class),第三是全部的使用關聯與判斷條件(註明在哪裡用到),最後則是修改的目的與記錄。處理的流程就定義迴圈,然後依序收集全部應該要收集的註解。
收集所有的Method註解後的內容很多,Class的註解可能會變為上百行之多而難以閱讀,Package層級則會面臨到沒有可放置單一註解的地方。因此建議Class的基本資訊、宣告內容與修改歷程放在Class的註解裡,使用關聯與判斷條件則另外產生外部檔存放(這部分也可在需要用到時再產生);Package則收集修改歷程、使用關聯與判斷條件另外存到外部檔案。
Package的資訊只需要收集屬於自己內部的資訊,不需要遞迴向上彙總。每個Package都整理好本身的資訊後,在Component、Module等級的Package就可以遞迴向下收集使用關聯,知道到底使用哪些Package後就清楚重用這個Package時還需要連帶哪些Package。修改記錄的收集用途亦是讓我們可以立即知道該Package下全部的變動。
收集全部Package使用關聯的過程中,還能夠建立使用Package間的垂直與水平追溯表。
回顧前面的章節所做的事,在彙總註解內容時首先要作到的是格式檢查與基本資訊的產生,第二是宣告時繼承與實作對象的註解(Class),第三是全部的使用關聯與判斷條件(註明在哪裡用到),最後則是修改的目的與記錄。處理的流程就定義迴圈,然後依序收集全部應該要收集的註解。
收集所有的Method註解後的內容很多,Class的註解可能會變為上百行之多而難以閱讀,Package層級則會面臨到沒有可放置單一註解的地方。因此建議Class的基本資訊、宣告內容與修改歷程放在Class的註解裡,使用關聯與判斷條件則另外產生外部檔存放(這部分也可在需要用到時再產生);Package則收集修改歷程、使用關聯與判斷條件另外存到外部檔案。
Package的資訊只需要收集屬於自己內部的資訊,不需要遞迴向上彙總。每個Package都整理好本身的資訊後,在Component、Module等級的Package就可以遞迴向下收集使用關聯,知道到底使用哪些Package後就清楚重用這個Package時還需要連帶哪些Package。修改記錄的收集用途亦是讓我們可以立即知道該Package下全部的變動。
收集全部Package使用關聯的過程中,還能夠建立使用Package間的垂直與水平追溯表。
2009年5月13日 星期三
V10 自動補齊註解(5)──修改的程式與修改記錄的列表
註解的處理約略分為三個層次:靜態的Class與Method宣告、Method內動態程式收集、還有現在要討論的修改記錄列表。我們期望所有的修改在依照規定作好註解之後也能夠被這個工具分門別類地收集在註解裡,然後使用修改追溯的功能找出全部應該測試的範圍。
每一次的修改都應註明日期,版本屬性可以使用人工填入,或是在統一處理的時候依照版本時間來區分該次修改屬於哪一個版本。修改可能是Method的宣告或內容修改。對問題單而言,根據此單號修改的部分是解決問題的方法;對Method而言,把屬於自己的修改資訊收集起來就是全部修改歷史;對版本而言,落在指定時間範圍的註解就是這次版本所有的修改。
原先的修改記錄都是手動撰寫在另一份文件或是問題單管理系統,要說明修改的原因同時附上修改問題時動到的程式碼片斷。之前在維護公司系統的時候,修改程式與單元測試如果花費一個單位的時間,那麼比對與commit程式加上填寫修改報告就大約要再花費半個單位的時間,對效率的影響是很大的。
製作自動產生修改報告文件的工具可以增進維護人員的效率,再搭配後面所提之修改處對應的測試範圍更能保證精確地測試到應該測的部分。不過要達成這些功能的同時,需要先嚴謹地定義各式註解代表的意義與擁有的欄位,才能令處理工具正確地處理程式碼的各個區塊。
每一次的修改都應註明日期,版本屬性可以使用人工填入,或是在統一處理的時候依照版本時間來區分該次修改屬於哪一個版本。修改可能是Method的宣告或內容修改。對問題單而言,根據此單號修改的部分是解決問題的方法;對Method而言,把屬於自己的修改資訊收集起來就是全部修改歷史;對版本而言,落在指定時間範圍的註解就是這次版本所有的修改。
原先的修改記錄都是手動撰寫在另一份文件或是問題單管理系統,要說明修改的原因同時附上修改問題時動到的程式碼片斷。之前在維護公司系統的時候,修改程式與單元測試如果花費一個單位的時間,那麼比對與commit程式加上填寫修改報告就大約要再花費半個單位的時間,對效率的影響是很大的。
製作自動產生修改報告文件的工具可以增進維護人員的效率,再搭配後面所提之修改處對應的測試範圍更能保證精確地測試到應該測的部分。不過要達成這些功能的同時,需要先嚴謹地定義各式註解代表的意義與擁有的欄位,才能令處理工具正確地處理程式碼的各個區塊。
2009年5月12日 星期二
V09 自動補齊註解(4)──Method使用關聯與判斷內容
在處理Method流程的同時,我們可以拿到Method裡每一行敍述所操作的方法,收集每一個方法內所呼叫的全部方法(不管是元件內部或是其它的Component Interface Method),就能夠再作進一步的分析使用。
對一個Method而言,解析過裡頭的程式碼同時收集所有呼叫方法意義是:該Method所使用的全部Method有精確的範圍。再進一步地分析,方法有無論如何都會執到、提供條件敍述判斷用、滿足特定條件判斷才會執行到的三種類型,第一種表示的是百分之百都會用到的動作(include)、第二種表示的是造成處理流程分歧的判斷(decision)、第三種表示的是前述判斷條件成立後才會執行到的動作(exclude)。
方法使用關聯的應用意義在於追溯,從Use Case Method往下看是完成所必須具備的全部Method,從指定Method往上看則是找出每一層直接或間接使用它的關係;關聯的層級也可以從Method可以推展到Class。以此為基礎產生出來的就會是各個層級裡所有Class(或Method)的水平追溯與垂直追溯,在Class層級等於Use Case層級時,拿到的是Use Case的水平追溯與垂直追溯。
在條件敍述裡判斷的方法可以被另外區分出來,涵蓋所有條件分歧路線與所有條件值的測試才會是完整的。經過這一層的處理,應該還可以產出所有影響分歧條件的Method清單並同時收集每個條件Method本身全部的可能傳回值,撰寫Test Case時可以快速參考所有可能的變化加以設計測試。
使用與判斷的資訊我認為放在Method的Java Doc比較符合其存在的位置意義,經由處理程式自動產生,並在日後每次執行的時候自動修改這個部分的內容。
對一個Method而言,解析過裡頭的程式碼同時收集所有呼叫方法意義是:該Method所使用的全部Method有精確的範圍。再進一步地分析,方法有無論如何都會執到、提供條件敍述判斷用、滿足特定條件判斷才會執行到的三種類型,第一種表示的是百分之百都會用到的動作(include)、第二種表示的是造成處理流程分歧的判斷(decision)、第三種表示的是前述判斷條件成立後才會執行到的動作(exclude)。
方法使用關聯的應用意義在於追溯,從Use Case Method往下看是完成所必須具備的全部Method,從指定Method往上看則是找出每一層直接或間接使用它的關係;關聯的層級也可以從Method可以推展到Class。以此為基礎產生出來的就會是各個層級裡所有Class(或Method)的水平追溯與垂直追溯,在Class層級等於Use Case層級時,拿到的是Use Case的水平追溯與垂直追溯。
在條件敍述裡判斷的方法可以被另外區分出來,涵蓋所有條件分歧路線與所有條件值的測試才會是完整的。經過這一層的處理,應該還可以產出所有影響分歧條件的Method清單並同時收集每個條件Method本身全部的可能傳回值,撰寫Test Case時可以快速參考所有可能的變化加以設計測試。
使用與判斷的資訊我認為放在Method的Java Doc比較符合其存在的位置意義,經由處理程式自動產生,並在日後每次執行的時候自動修改這個部分的內容。
2009年5月11日 星期一
V08 自動補齊註解(3)──補齊Method內的程式碼註解
元件六個部分裡Properties、Model與Exception的程式碼是簡單到不需要用註解說明的,自動補齊程式碼註解的對象是Implementation、Flow與Action。依照我的設計準則,每一層被上一層呼叫到的入口Method都應該只用程式流程的敍述來呼叫實際動作的方法。
流程相關的方法有以下五種,標示種類為流程者表示內部應只放流程敍述與動作方法呼叫。
●Implementation Method(入口方法)
beforeInvoke()與afterInvoke()內放的是流程,細部的動作只能是Flow Method或是其它的Component Interface。
●Flow Method且被Implementation Method直接呼叫(被入口方法呼叫的流程方法)
●Flow Method但只被Flow Method呼叫(內部流程方法)
以上兩種都屬於流程,細部動作只能是Flow Method、Action Method或是其它的Component Interface。
●Action Method且被Flow Method直接呼叫(被流程方法呼叫的動作方法)
這屬於實作流程,細部動作只能是Action Method或是其它的Component Interface。
●Action Method但只被Action Method呼叫(內部動作方法)
這屬於實作流程,細部動作只能是Action Method或是其它的Component Interface。不過到這層應該大多都是呼叫很底層的API,產生的流程內容已經不易讀懂。
除了最後一種Method之外,其他種類的Method只能放置流程控制的指令。為這幾種指令定義好註解的範本,再從實際執行的方法註解裡取得第一行的功能簡述嵌入到註解範本裡,產成註解結果後放置到程式碼前即可。依序執行每個Class的每個Method裡的每行程式,就可以用同樣的方法產生全部的程式碼註解,並可以隨時依真實的註解同步最新的內容。
流程相關的方法有以下五種,標示種類為流程者表示內部應只放流程敍述與動作方法呼叫。
●Implementation Method(入口方法)
beforeInvoke()與afterInvoke()內放的是流程,細部的動作只能是Flow Method或是其它的Component Interface。
●Flow Method且被Implementation Method直接呼叫(被入口方法呼叫的流程方法)
●Flow Method但只被Flow Method呼叫(內部流程方法)
以上兩種都屬於流程,細部動作只能是Flow Method、Action Method或是其它的Component Interface。
●Action Method且被Flow Method直接呼叫(被流程方法呼叫的動作方法)
這屬於實作流程,細部動作只能是Action Method或是其它的Component Interface。
●Action Method但只被Action Method呼叫(內部動作方法)
這屬於實作流程,細部動作只能是Action Method或是其它的Component Interface。不過到這層應該大多都是呼叫很底層的API,產生的流程內容已經不易讀懂。
除了最後一種Method之外,其他種類的Method只能放置流程控制的指令。為這幾種指令定義好註解的範本,再從實際執行的方法註解裡取得第一行的功能簡述嵌入到註解範本裡,產成註解結果後放置到程式碼前即可。依序執行每個Class的每個Method裡的每行程式,就可以用同樣的方法產生全部的程式碼註解,並可以隨時依真實的註解同步最新的內容。
2009年5月8日 星期五
V07 自動補齊註解(2)──Method的傳入參數與傳回值
版權宣告與Class註解僅是靜態的說明,解析的重點還是在於Method。Java Doc的最基本是說明Method的功能,使用param記錄傳入參數名稱與類型、return記錄傳回類型、throws記錄拋出的例外類型,都與Method的宣告行有關。
設計者在改變方法宣告的同時,不一定會去更正Java Doc的內容,因此仍然需要加上自動補齊的功能令它們同步。註解需要的內容都可以從Method宣告行拿到,列出的資訊與Java Doc轉成的Data Model比較後,刪除多出的屬性、自動補上缺少的欄位並調整順序以符合Method的宣告。自動產生的部分應加上標示(例如[AUTO])以方便事後搜尋出來作人工的調整。
開發團隊都會定義自己所用的Naming Rules,在處理Class與Method的同時也可以依照規則檢查各個屬性的名稱;同時也可以檢查屬性名稱後是否有加上說明。以上應有而未有的註解可以在應加上的地方註明[TODO]表示少了些東西,以便快速定位後補加上去。
到現在為止處理的是Class與Method宣告的部分,在詳細描述的區塊務必在先用第一句簡短地描述其功用,後面再跟著註記詳細的說明;這是因為未來需要Class與Method的註解時會取得第一個句子作為使用內容(避免內容過多)。
註:如果Method是實作Interface或是覆寫父類別的Method,就不要在這層產生宣告註解而應該產生指向宣告的註解內容。
設計者在改變方法宣告的同時,不一定會去更正Java Doc的內容,因此仍然需要加上自動補齊的功能令它們同步。註解需要的內容都可以從Method宣告行拿到,列出的資訊與Java Doc轉成的Data Model比較後,刪除多出的屬性、自動補上缺少的欄位並調整順序以符合Method的宣告。自動產生的部分應加上標示(例如[AUTO])以方便事後搜尋出來作人工的調整。
開發團隊都會定義自己所用的Naming Rules,在處理Class與Method的同時也可以依照規則檢查各個屬性的名稱;同時也可以檢查屬性名稱後是否有加上說明。以上應有而未有的註解可以在應加上的地方註明[TODO]表示少了些東西,以便快速定位後補加上去。
到現在為止處理的是Class與Method宣告的部分,在詳細描述的區塊務必在先用第一句簡短地描述其功用,後面再跟著註記詳細的說明;這是因為未來需要Class與Method的註解時會取得第一個句子作為使用內容(避免內容過多)。
註:如果Method是實作Interface或是覆寫父類別的Method,就不要在這層產生宣告註解而應該產生指向宣告的註解內容。
2009年5月7日 星期四
V06 自動補齊註解(1)──格式正確性與基本資訊
註解是人為按照格式輸入的,編輯器會自動檢查註解是否有造成程式編譯不正確的錯誤,但是註解內容的格式就需要另外用工具來判別。除了檢查格式之外,應該同時從預先建立的基本資訊檔裡取得對應的內容自動地放入註解並儲存。
package宣告之前通常應有版權宣告段落,class註解內通常會有since、author、version;Method註解雖然有param、return、throws但是打算也加上since、author等資訊,這是因為Method可能會因重構移動到其它Class裡而造成資訊的錯失。
雖然Eclipse可以匯入標準的註解格式,但是格式可能因不同的需求而修改存放資訊,在需要變動的時候絕對不會有人一一將成千上萬的Class取出來重新調整;同樣地如果有人忘了匯入而造成缺少註解內容,若那人不動聲色地放入儲存庫也不見得有人發現或是會更正。用自動的功能消弭掉人為的誤差讓所有的產出一致無論在什麼領域都是非常重要的事。
整合以上的需要註記的欄位就是應該放在基本資訊檔裡的資訊,這些資訊區分為公司通用(版權宣告)、版本使用(version)、個人專用(author)與時間相關(since、版權宣告裡的年份),設計時依不同用途放置在不同的資料夾中備取。處理時若有缺少的欄位就從資訊檔取得,存在的欄位再定義檢查的規則看是否有誤。
package宣告之前通常應有版權宣告段落,class註解內通常會有since、author、version;Method註解雖然有param、return、throws但是打算也加上since、author等資訊,這是因為Method可能會因重構移動到其它Class裡而造成資訊的錯失。
雖然Eclipse可以匯入標準的註解格式,但是格式可能因不同的需求而修改存放資訊,在需要變動的時候絕對不會有人一一將成千上萬的Class取出來重新調整;同樣地如果有人忘了匯入而造成缺少註解內容,若那人不動聲色地放入儲存庫也不見得有人發現或是會更正。用自動的功能消弭掉人為的誤差讓所有的產出一致無論在什麼領域都是非常重要的事。
整合以上的需要註記的欄位就是應該放在基本資訊檔裡的資訊,這些資訊區分為公司通用(版權宣告)、版本使用(version)、個人專用(author)與時間相關(since、版權宣告裡的年份),設計時依不同用途放置在不同的資料夾中備取。處理時若有缺少的欄位就從資訊檔取得,存在的欄位再定義檢查的規則看是否有誤。
2009年5月6日 星期三
V05 註解的存取(3)──取得註解的內容
為了確認Java程式碼與註解的關聯,實際在workspace裡測試了Eclipse JDT的功能。JDT裡共有兩個系列可以處理Java程式,分別是CompilationUnit與AST。
AST採用DOM的結構方式解析程式碼,從Class、Field、Method甚至是方法裡的Block、Statement都能找到對應的物件,不管是解析的深度(CompilationUnit只能拿到Class、Field與Method)或是API的便利都比CompilationUnit好用。但是AST從Eclipse 2.1起就因為註解的複雜而取消在Block與Statement上附帶Java Comment的功能,只在Type(等同於Class)層級集合該程式的全部註解;無法建立註解對應程式碼的關聯,這對我後續想做到的事是沒有幫助的。CompilationUnit的解析沒有進入Method內,也沒有提供直接取得Java Doc的方法,但是各物件都提供了getSource()的方法可快速拿到包含註解與宣告的程式碼。
程式碼的註解的確會造成判讀的困擾,像是因修改而註解掉的程式碼就很可能被視為下一行程式的註解。為了讓程式明白地知道該註解是資訊還是修改記錄,必須定義不同用途的註解方式:像是註解的程式碼一律在行首使用 // 、設計的記錄與屬性都用多行的 /* */ 包覆該程式碼前一行、修改的簡要資訊則先用單行的 /* */ 放在程式碼後讓處理程式整合到設計記錄。
用程式來處理程式碼是我想做的作法中最關鍵的技術。尋常的程式設計的自由度會令程式區塊內的意義不夠精確,所以要先定義每一個細部單位的意義;再來是解析後儲存的集合與每一個單位彼此之間關聯的建立。根據後面想要達成的功能,將會陸續明白需要在哪些地方建立什麼樣的關聯,這也必須加以明確的記錄。
至於要用哪一種技術來解析程式碼,現在也還不能決定。目前比較偏好CompilatoinUnit加上自己寫程式分析更細部的source,不過解析方法純粹自己撰寫也是能夠接受的選擇。後面的文章會暫時假設所有程式碼與註解的解析都百分之百正確,以此為基本前提來討論可以自動產出些什麼。
AST採用DOM的結構方式解析程式碼,從Class、Field、Method甚至是方法裡的Block、Statement都能找到對應的物件,不管是解析的深度(CompilationUnit只能拿到Class、Field與Method)或是API的便利都比CompilationUnit好用。但是AST從Eclipse 2.1起就因為註解的複雜而取消在Block與Statement上附帶Java Comment的功能,只在Type(等同於Class)層級集合該程式的全部註解;無法建立註解對應程式碼的關聯,這對我後續想做到的事是沒有幫助的。CompilationUnit的解析沒有進入Method內,也沒有提供直接取得Java Doc的方法,但是各物件都提供了getSource()的方法可快速拿到包含註解與宣告的程式碼。
程式碼的註解的確會造成判讀的困擾,像是因修改而註解掉的程式碼就很可能被視為下一行程式的註解。為了讓程式明白地知道該註解是資訊還是修改記錄,必須定義不同用途的註解方式:像是註解的程式碼一律在行首使用 // 、設計的記錄與屬性都用多行的 /* */ 包覆該程式碼前一行、修改的簡要資訊則先用單行的 /* */ 放在程式碼後讓處理程式整合到設計記錄。
用程式來處理程式碼是我想做的作法中最關鍵的技術。尋常的程式設計的自由度會令程式區塊內的意義不夠精確,所以要先定義每一個細部單位的意義;再來是解析後儲存的集合與每一個單位彼此之間關聯的建立。根據後面想要達成的功能,將會陸續明白需要在哪些地方建立什麼樣的關聯,這也必須加以明確的記錄。
至於要用哪一種技術來解析程式碼,現在也還不能決定。目前比較偏好CompilatoinUnit加上自己寫程式分析更細部的source,不過解析方法純粹自己撰寫也是能夠接受的選擇。後面的文章會暫時假設所有程式碼與註解的解析都百分之百正確,以此為基本前提來討論可以自動產出些什麼。
2009年5月5日 星期二
V04 註解的存取(2)──處理註解的順序
要開始撰寫處理註解內容的工具的準備工作有三個:首先要定義好註解的格式與對應的Data Model,再來是用什麼樣的流程來通過全部有註解的地方,最後則是用什麼樣的技術來取得該地方的註解內容。

現在有定義的程式註解全部都放在Java檔案裡。這裡需要用兩個方向來看待之:在Eclipse的workspace結構裡Java檔案的放置方式,與取得Java檔案後如果解析內部的結構。
要在workspace裡找到Java檔案,結構的層次依序為workspace、java project、source folder
、package四層(雖然package真實的資料夾結構是多層的,但是在Eclipse裡已經壓扁為一層),這意味著每一個層都得準備一層迴圈來重覆處理,同時在每一層的迴圈裡可能需要有自訂處理範圍的功能(初期先全部處理亦可)。經過這四層迴圈就可以取得全部的Java檔案作後續處理。
Java檔案的內部結構是Class(Interface)、Data或Method、Method內部的程式碼,其中Data與Method之間沒有關聯但是在一個Java檔案裡都是零到無數個的。所以處理一個Java檔案時要依序取得Class(Interface)註解、所有Data註解、所有Method註解與所有Method裡所有程式Comment,在取得的同時也要將關聯資訊放入註解Data Model。
在處理程式裡取得的註解Data Model都要依照結構放入對應的cache,目的是希望隨時都可藉由package、class、data與method等等的關鍵字找到對應的註解Data Model,處理完後全部的註解Data Model還必須匯出到現有的Java檔案裡一同儲存才算是完整的處理。
現在有定義的程式註解全部都放在Java檔案裡。這裡需要用兩個方向來看待之:在Eclipse的workspace結構裡Java檔案的放置方式,與取得Java檔案後如果解析內部的結構。
要在workspace裡找到Java檔案,結構的層次依序為workspace、java project、source folder
、package四層(雖然package真實的資料夾結構是多層的,但是在Eclipse裡已經壓扁為一層),這意味著每一個層都得準備一層迴圈來重覆處理,同時在每一層的迴圈裡可能需要有自訂處理範圍的功能(初期先全部處理亦可)。經過這四層迴圈就可以取得全部的Java檔案作後續處理。
Java檔案的內部結構是Class(Interface)、Data或Method、Method內部的程式碼,其中Data與Method之間沒有關聯但是在一個Java檔案裡都是零到無數個的。所以處理一個Java檔案時要依序取得Class(Interface)註解、所有Data註解、所有Method註解與所有Method裡所有程式Comment,在取得的同時也要將關聯資訊放入註解Data Model。
在處理程式裡取得的註解Data Model都要依照結構放入對應的cache,目的是希望隨時都可藉由package、class、data與method等等的關鍵字找到對應的註解Data Model,處理完後全部的註解Data Model還必須匯出到現有的Java檔案裡一同儲存才算是完整的處理。
2009年5月4日 星期一
V03 如何寫好作文
作文的基本結構其實很接近Use Case-Scenario-Activity,可以用top-down的設計方式來鋪陳文章的內容。
先將整篇作文視為SRS(System Requirement Specification),作文的題目就像是Use Case Name,用很少的字數來表達全部文章的功用;SRS的第一個章節是描述Use Case目標的詳細說明,那麼第一段就可以先用較多的字數闡述主題(這適用於論文,記述文不要用)。
再來就要先在腦海裡製作文章的scenario,進入前的準備、起點、詳細流程、流程中各種可能分歧與最後的狀況,這些scenario相關的部分都必須先構築完整才能進行下一階段。如果流程只有一半就開始寫作,很有可能會跟現今的專案一樣寫到一半才發現流程有不足之處而難以收尾,屆時不是改寫出問題的那一段就是草草結束,這些都不會有好結果的。
如果需要其他看法的scenario佐證自己的論點,記得也要一併思考。能夠整合為一個流暢的scenario的話就一起表述,否則就依序分開寫作,但是要小心不要有前後的衝突而自打嘴巴。各個scenario都陳述的最後用一段結尾來說明這個Use Case採用我們上面作法的優點或是延伸的感想。這樣一來作文的全部架構就大致成形。
接著進入細部設計。scenario裡的每個activity是句子的集合,要決定用哪幾句話的句意來達到activity的目標,同時再設計每個句子裡要用什麼樣的字詞組合。心裡的模型如何拆解為對的句子順序關係到流暢度,記憶了多少字詞關係到可以選用的API多寡,這無法投機而要看各人事前所作的修行。組合之後再運用重構的想法調整用字遣詞與前後關係,確認後再落筆撰寫。
慢慢寫出心裡的結構與內容完成作文後,記得再閱讀一次測試來找出不理想的地方修正。通過測試後就可以無怨無悔地交卷了。
註:我的高中聯考作文分數為50.5/70、大學聯考作文得分也超過60%,這個論點應該很具有參考價值!
先將整篇作文視為SRS(System Requirement Specification),作文的題目就像是Use Case Name,用很少的字數來表達全部文章的功用;SRS的第一個章節是描述Use Case目標的詳細說明,那麼第一段就可以先用較多的字數闡述主題(這適用於論文,記述文不要用)。
再來就要先在腦海裡製作文章的scenario,進入前的準備、起點、詳細流程、流程中各種可能分歧與最後的狀況,這些scenario相關的部分都必須先構築完整才能進行下一階段。如果流程只有一半就開始寫作,很有可能會跟現今的專案一樣寫到一半才發現流程有不足之處而難以收尾,屆時不是改寫出問題的那一段就是草草結束,這些都不會有好結果的。
如果需要其他看法的scenario佐證自己的論點,記得也要一併思考。能夠整合為一個流暢的scenario的話就一起表述,否則就依序分開寫作,但是要小心不要有前後的衝突而自打嘴巴。各個scenario都陳述的最後用一段結尾來說明這個Use Case採用我們上面作法的優點或是延伸的感想。這樣一來作文的全部架構就大致成形。
接著進入細部設計。scenario裡的每個activity是句子的集合,要決定用哪幾句話的句意來達到activity的目標,同時再設計每個句子裡要用什麼樣的字詞組合。心裡的模型如何拆解為對的句子順序關係到流暢度,記憶了多少字詞關係到可以選用的API多寡,這無法投機而要看各人事前所作的修行。組合之後再運用重構的想法調整用字遣詞與前後關係,確認後再落筆撰寫。
慢慢寫出心裡的結構與內容完成作文後,記得再閱讀一次測試來找出不理想的地方修正。通過測試後就可以無怨無悔地交卷了。
註:我的高中聯考作文分數為50.5/70、大學聯考作文得分也超過60%,這個論點應該很具有參考價值!
2009年5月2日 星期六
V02 註解本體的內容與註解的放置
註解要怎麼寫才是理想的?在網路上能找到一些不同的說法。比較普遍接受的說法是不要記載程式碼怎麼寫的,而要記錄為了什麼目的而寫這些程式碼;因為註解是為了讓其他人快速地看懂自己為什麼要這樣寫。對於這個看法我沒有異議,方法有自己必須達成的目標,方法內的一連串註解是達成目標的分解動作,一組詳細記錄的註解其作用有如該方法的SOP般讓所有人都能很快地看懂怎麼樣來完成。
註解以精簡為目標,但是在較艱深的場合還是附上簡短的範例說明較為理想。如果把人腦視作一部電腦,撰寫某段程式碼後寫出的註解就像是把當時的想法匯出為文字敍述,驗證註解內容是否恰當的一種方式,就是經過較長一段時間忘卻後讓原撰寫者看自己原來所寫的註解,倘使能夠讓自己完全回憶起當時的情景就是滿足所需的註解。
目前Class、Method與Data的Java Doc註解,以及程式上的Comment都跟著程式碼走。前面的Java Doc只存在於靜態說明的地方,即使屬性加多後行數增多,並不至於影響閱讀;但是Comment一般都要求越簡短越好,用我的方法製作Comment後勢必使得程式碼間的間隔拉大造成不易閱讀的現象,這並不符合普遍的需要。
龐大的Comment或許可以脫離程式另外存在?這是讓程式碼變回較易讀的方法之一,但是Comment與程式分離之後必須有自己的管理機制,同時還要建立Comment與程式碼的關聯。程式碼是非常易變的東西,建立在易變的基礎而且必須另外同步更新Comment勢必浪費非常多的時間。顯而易見地,這是一個蠢解法。
既然目的是在擁有詳細的註解時維持程式碼的可讀性,那麼可以學習Eclipse作法,在Java編輯器上把Comment區塊縮減為一行。開啟一個Class後其實我們可以發現有很多地方可以收合,像是最前面的版權宣告區塊、所有的Java Doc註解與Method的程式本體都是如此,但是對於Comment就沒有這樣的功能。改寫Java編輯器使之對Comment也有收合與展開的功能,就可以達成目的。
2009年5月1日 星期五
V01 註解的存取(1)──定義註解的格式
以下的各種註解範例取自於JDK 5.0裡頭的java.lang.StringTokenizer。
/**
* Class Description....
*
* @author Lee Boynton
* @author Arthur van Hoff
* @version 1.189, 10/21/05
* @see java.lang.Object#toString()
* @see java.lang.StringBuffer
* @see java.lang.StringBuilder
* @see java.nio.charset.Charset
* @since JDK1.0
*/
這是Java Doc對Class的註解範例。很明顯地具有描述的本體與下面用@符號開頭的屬性,屬性可能具有多個值。
/** Field Description.... */
private final char value[];
這是Java Doc對Data的註解範例。只擁有描述本體而沒有任何屬性的結構,很明顯地是Class註解的子集合。
/**
* Method Description....
*
* @param codePoints array that is the source of Unicode code points.
* @param offset the initial offset.
* @param count the length.
* @exception IllegalArgumentException if any invalid Unicode code point
* is found in
* @exception IndexOutOfBoundsException if the
* and
* the bounds of the
* @since 1.5
*/
public String(int[] codePoints, int offset, int count) {
}
這是Java Doc對Method的註解範例。註解的屬性名稱雖與Class註解有所出入,但是基本的結構是一致的。
/* Reset these anyway */
delimsChanged = false;
// The array representing the String is the same
// size as the String, so no point in making a copy.
v = originalValue;
從String與StringTokenizer裡發現兩種不同的註解類型,都是合法的Comment。它們都只具有描述的本體而沒有任何屬性,與Data的註解結構相同。
2000年的時候曾經維護過某大公司應用在銀行的大型產品程式碼,註解裡鉅細靡遺地記錄著對應程式碼的修改歷程,每筆記錄存放了修改日期、修改人員與修改原因的資訊,同時Class上也收集了Class內所有的修改記錄,看起來非常地清楚。因此在註解的設計裡同樣選擇採用這個制度,讓修改歷程放在註解裡跟著程式碼走,額外再使用Java Doc的標籤讓這些記錄可以出現在產出文件裡。(以前的產品只能用文字搜尋)
U22提到了收集所有註解另外處理的功能,經過收集後的註解已經與程式碼脫離,所以需要額外的欄位來定義與其相關的程式部位:Class、Data註解需要記載屬於哪一個Class,Method、Comment註解需要記載屬於哪一個Class的Method,將這些資訊定義在一個關聯用的Attribute(id)裡。
以上是註解Data Model結構(U23)的基本設計依據。
/**
* Class Description....
*
* @author Lee Boynton
* @author Arthur van Hoff
* @version 1.189, 10/21/05
* @see java.lang.Object#toString()
* @see java.lang.StringBuffer
* @see java.lang.StringBuilder
* @see java.nio.charset.Charset
* @since JDK1.0
*/
這是Java Doc對Class的註解範例。很明顯地具有描述的本體與下面用@符號開頭的屬性,屬性可能具有多個值。
/** Field Description.... */
private final char value[];
這是Java Doc對Data的註解範例。只擁有描述本體而沒有任何屬性的結構,很明顯地是Class註解的子集合。
/**
* Method Description....
*
* @param codePoints array that is the source of Unicode code points.
* @param offset the initial offset.
* @param count the length.
* @exception IllegalArgumentException if any invalid Unicode code point
* is found in
codePoints* @exception IndexOutOfBoundsException if the
offset* and
count arguments index characters outside* the bounds of the
codePoints array.* @since 1.5
*/
public String(int[] codePoints, int offset, int count) {
}
這是Java Doc對Method的註解範例。註解的屬性名稱雖與Class註解有所出入,但是基本的結構是一致的。
/* Reset these anyway */
delimsChanged = false;
// The array representing the String is the same
// size as the String, so no point in making a copy.
v = originalValue;
從String與StringTokenizer裡發現兩種不同的註解類型,都是合法的Comment。它們都只具有描述的本體而沒有任何屬性,與Data的註解結構相同。
2000年的時候曾經維護過某大公司應用在銀行的大型產品程式碼,註解裡鉅細靡遺地記錄著對應程式碼的修改歷程,每筆記錄存放了修改日期、修改人員與修改原因的資訊,同時Class上也收集了Class內所有的修改記錄,看起來非常地清楚。因此在註解的設計裡同樣選擇採用這個制度,讓修改歷程放在註解裡跟著程式碼走,額外再使用Java Doc的標籤讓這些記錄可以出現在產出文件裡。(以前的產品只能用文字搜尋)
U22提到了收集所有註解另外處理的功能,經過收集後的註解已經與程式碼脫離,所以需要額外的欄位來定義與其相關的程式部位:Class、Data註解需要記載屬於哪一個Class,Method、Comment註解需要記載屬於哪一個Class的Method,將這些資訊定義在一個關聯用的Attribute(id)裡。
以上是註解Data Model結構(U23)的基本設計依據。
2009年4月29日 星期三
U28 加強服務接受度的幾個特性
最近參加了服務體驗工程方法(SEE)的部分課程,其中一天提到服務接受度的分析,講師是一位認知心理學的助理教授,他從生活中觀察並分析許多事件的使用者行為,歸納出提供客戶服務時的一些原則與重點。
有一個段落的主旨是提高客戶的服務接受度,講師建議從以下幾個方向來加強:
●可理解性。接觸系統後能很快理解內部的運作邏輯。
●可學習性。接觸系統後能很快學會如何完成作業。
●效率。熟悉系統後可以很有效率地完成。
●可記憶性。隔一段時日後再使用系統還能記得如何操作。
●錯誤處理。系統應能避免犯錯,犯錯了也有機會回復
聽課的同時,我很認真地以這幾個特性來檢驗自己的設計想法。現在通常產出的程式碼並無規則可循,每個團隊都使用自己熟知的一套,看別人的程式時根本無從著手(除了極少數的天才),更不用說要理解、學習與熟用。
一方面為了統一分析與設計的基本準則,另一方面為了提升程度略差的人到達一定的水準,固定的方法與固定的產出是最容易讓理解、學習與使用門檻降低的方法。能力較好的人捨棄一些快速完成功能的捷徑,轉而鋪陳讓所有人共同提升水準的作法,才能夠讓開發團隊不致變調為英雄的工具而真的稱得上團隊。
為了往這個方向邁進,主管希望我把部落格的想法濃縮到投影片中,與公司裡資深的同仁們討論其可行性與最佳作法。把想法轉換為可執行的方法,這是我接下來的工作目標。
註:在設計且撰寫程式的同時,是否曾經想過程式碼除了達成功能之外的用途?看別人不同風格的程式碼會抱怨看不懂,自己寫出來的說不定事實上沒人看得懂;如果心裡只看到自己的開發目標,對其他面向的需要視而不見,終究只是無法提升團隊實力的自我格局而已。
有一個段落的主旨是提高客戶的服務接受度,講師建議從以下幾個方向來加強:
●可理解性。接觸系統後能很快理解內部的運作邏輯。
●可學習性。接觸系統後能很快學會如何完成作業。
●效率。熟悉系統後可以很有效率地完成。
●可記憶性。隔一段時日後再使用系統還能記得如何操作。
●錯誤處理。系統應能避免犯錯,犯錯了也有機會回復
聽課的同時,我很認真地以這幾個特性來檢驗自己的設計想法。現在通常產出的程式碼並無規則可循,每個團隊都使用自己熟知的一套,看別人的程式時根本無從著手(除了極少數的天才),更不用說要理解、學習與熟用。
一方面為了統一分析與設計的基本準則,另一方面為了提升程度略差的人到達一定的水準,固定的方法與固定的產出是最容易讓理解、學習與使用門檻降低的方法。能力較好的人捨棄一些快速完成功能的捷徑,轉而鋪陳讓所有人共同提升水準的作法,才能夠讓開發團隊不致變調為英雄的工具而真的稱得上團隊。
為了往這個方向邁進,主管希望我把部落格的想法濃縮到投影片中,與公司裡資深的同仁們討論其可行性與最佳作法。把想法轉換為可執行的方法,這是我接下來的工作目標。
註:在設計且撰寫程式的同時,是否曾經想過程式碼除了達成功能之外的用途?看別人不同風格的程式碼會抱怨看不懂,自己寫出來的說不定事實上沒人看得懂;如果心裡只看到自己的開發目標,對其他面向的需要視而不見,終究只是無法提升團隊實力的自我格局而已。
2009年4月27日 星期一
U27 繞一大圈後再返回原點的收獲
之前看自己寫的或是別人寫的程式碼時,總感覺有一大堆不同意義的程式混雜在一起,但是又無法說清楚那些是什麼。隨著經驗的增長且接觸較多的理論後,才能夠明確地指出程式的佈置應有六種意義,同時在2007/10開始在合作的專案裡嘗試實作。然而又在2009/04發現最重要的Flow與Action實際上是可以放在一起的,只需要運用額外的註解。
為了印證自己的想法,最近特地去查看重構的方法(為了Class、Method的佈置)與敏捷開發的原則(為了快速的開發),並在心裡作了一些比較。
重構部分,我比較在意的是靜態佈置與資料、動作定位的問題。儘可能最大化的可能佈置Class結構可以避免Extract(Interface、Subclass、Superclass);設計方法時依照所處層級的動作意義對應放置可以不用Move、Extract(Method、Field);同時能夠減少Pull Up、Pull Down(Method、Field)有時必須連帶Extract Class的影響。另外貫徹絕對重用的想法就能根絕Duplicated Code與Shortgun Surgery。
至於敏捷開發,同步開發團隊思維與換人接手程式的原則,在定義固定的元件結構下甚至不需要pair programming就能夠直接換另一個成員;註解與文件是為了讓別人更瞭解自己的程式的原則,應用註解來產生全部Flow與Action的流程圖可以滿足;快速地不斷產生成果的原則,在軟體元件化後就能夠快速組裝流程甚至運用SA Tool來作勾選與拖拉式的開發;設計是為了駕馭客戶需求的改變,可以用任意tier、layer的切割、快速的Flow調整與更換不同的軟體元件來滿足。
敏捷開發加上重構,看起來是用敏捷的寫作方式做出可執行的成果,再重構程式碼調整Class、Method與Data的佈置作最佳化。既然如此,為什麼不用敏捷開發直接作出重構後應該有的佈置呢?目前看過的方法論裡文件都與程式脫節必須另外製作,融合各家所長以理想的程式結構為根本,直接使用程式來設計,再應用註解自動化產生絕大部分的設計文件,是不是可以節省製作文件的時間同時又保證其正確性?
目前只是一個連理論都不甚清楚的程式寫作員,但是相較於其他工程領域都有固定的模組化方式來堆砌出客戶想要的成果,軟體工程卻獨缺能夠被大部分人同意的決定性作法。不知道未來的程式設計是否有機會往我現在努力的方向演進?
為了印證自己的想法,最近特地去查看重構的方法(為了Class、Method的佈置)與敏捷開發的原則(為了快速的開發),並在心裡作了一些比較。
重構部分,我比較在意的是靜態佈置與資料、動作定位的問題。儘可能最大化的可能佈置Class結構可以避免Extract(Interface、Subclass、Superclass);設計方法時依照所處層級的動作意義對應放置可以不用Move、Extract(Method、Field);同時能夠減少Pull Up、Pull Down(Method、Field)有時必須連帶Extract Class的影響。另外貫徹絕對重用的想法就能根絕Duplicated Code與Shortgun Surgery。
至於敏捷開發,同步開發團隊思維與換人接手程式的原則,在定義固定的元件結構下甚至不需要pair programming就能夠直接換另一個成員;註解與文件是為了讓別人更瞭解自己的程式的原則,應用註解來產生全部Flow與Action的流程圖可以滿足;快速地不斷產生成果的原則,在軟體元件化後就能夠快速組裝流程甚至運用SA Tool來作勾選與拖拉式的開發;設計是為了駕馭客戶需求的改變,可以用任意tier、layer的切割、快速的Flow調整與更換不同的軟體元件來滿足。
敏捷開發加上重構,看起來是用敏捷的寫作方式做出可執行的成果,再重構程式碼調整Class、Method與Data的佈置作最佳化。既然如此,為什麼不用敏捷開發直接作出重構後應該有的佈置呢?目前看過的方法論裡文件都與程式脫節必須另外製作,融合各家所長以理想的程式結構為根本,直接使用程式來設計,再應用註解自動化產生絕大部分的設計文件,是不是可以節省製作文件的時間同時又保證其正確性?
目前只是一個連理論都不甚清楚的程式寫作員,但是相較於其他工程領域都有固定的模組化方式來堆砌出客戶想要的成果,軟體工程卻獨缺能夠被大部分人同意的決定性作法。不知道未來的程式設計是否有機會往我現在努力的方向演進?
2009年4月25日 星期六
U26 SOA的參考模型(Solution Stack)
近年來參加了幾次SOA的課程,直到最近的一次我才終於聽懂大部分的內容。其中參考模型的結構完全可以用我使用的切割單位來遞迴對應解釋,因而對這個部分立即開竅。(大的切割單位概稱為元件,內含三個小的切割單位:入口、流程與動作)
SOA參考模型的縱向結構是Consumers>Business Process>Services>Service Components>Operation System。從上往下可以切割為三個大的切割單位,內部再各自包含三個小的切割單位;每一層大的切割單位各自以不同的標準放到不同層級的容器裡執行,並加以不同層級的監控與加解密功能。
●功能:Consumers>Business Process>Services
入口:Business Process Interface
流程:Business Process
動作:Business Process與Service Interface
●服務:Services>Service Components
入口:Service Interface
流程:Service內部
動作:Service Interface與Service Component Interface
●元件:Service Components>Operation System
入口:Service Component Interface
流程:Service Component內部
動作:Service Component Interface與Operation System
將階層式重覆發生的事情設計為遞迴呼叫的方法是好的方法,理由是把重限層次可能發生的事簡化為一層。同樣地我相信將階層式重覆存在的結構用遞迴方法說明其精神也是好的比喻,原因是把原本要分開記憶的多個單位簡化成一種。
同樣作用的程式碼重覆存在是重構時要消滅的現象,在雜亂的現象中抽取出唯一的說明邏輯會有較好的學習效果。在任何場所、任何應用上推行極致的“絕對重用”會是增進學習與使用效率的良好方法,但是要注意維持唯一存在時必然會耗費額外的努力。
SOA參考模型的縱向結構是Consumers>Business Process>Services>Service Components>Operation System。從上往下可以切割為三個大的切割單位,內部再各自包含三個小的切割單位;每一層大的切割單位各自以不同的標準放到不同層級的容器裡執行,並加以不同層級的監控與加解密功能。
●功能:Consumers>Business Process>Services
入口:Business Process Interface
流程:Business Process
動作:Business Process與Service Interface
●服務:Services>Service Components
入口:Service Interface
流程:Service內部
動作:Service Interface與Service Component Interface
●元件:Service Components>Operation System
入口:Service Component Interface
流程:Service Component內部
動作:Service Component Interface與Operation System
將階層式重覆發生的事情設計為遞迴呼叫的方法是好的方法,理由是把重限層次可能發生的事簡化為一層。同樣地我相信將階層式重覆存在的結構用遞迴方法說明其精神也是好的比喻,原因是把原本要分開記憶的多個單位簡化成一種。
同樣作用的程式碼重覆存在是重構時要消滅的現象,在雜亂的現象中抽取出唯一的說明邏輯會有較好的學習效果。在任何場所、任何應用上推行極致的“絕對重用”會是增進學習與使用效率的良好方法,但是要注意維持唯一存在時必然會耗費額外的努力。
2009年4月24日 星期五
U25 再看簡單型的Component
以往的Method註解用途只用來存放說明、參數、傳回值與例外,在這個情況下方法意義的區分(指給處理程式用的)只能靠Class的佈置來達成,但是現在的註解已經可以盛裝更大量的資訊,我們就可以將原先分為六大部分其中的流程控制類(Flow與Action)再回歸為一個Class──只要能夠在Method註解裡區分其意義即可。

在元件裡流程控制相關的方法類型有以下五種(第一種放在Implementation),在註解裡定義一個方法類型欄位就能在處理程式裡取得對應值。
●Implementation Method(入口方法)
●Flow Method且被Implementation Method直接呼叫(被入口方法呼叫的流程方法)
●Flow Method但只被Flow Method呼叫(內部流程方法)
●Action Method且被Flow Method直接呼叫(被流程方法呼叫的動作方法)
●Action Method但只被Action Method呼叫(內部動作方法)
元件設計回歸到這樣的簡單結構在設計上已經很接近現在的主流作法,製作流程方法時毌須浪費時間在與結構佈置有關的行為,唯一需要作的是依註解規定撰寫應該有的註解內容──然而這本來就是應該做的事。至此,我們能夠在不多花費設計時間的前提下完成滿足以軟體工廠為前提的元件設計。
我會為了容易編輯註解的目的製作一個編輯器,除了可以把註解內容(多行文字)直覺地以UI欄位再編修之外,還可以詳細定義註解所要編輯的屬性並檢查值是否合法,設計人員只需要依畫面提示輸入註解內容而不用去注意註解的格式,便能得到符合規定的註解內容。另外還需要改寫Java編輯器,增加註解可收合或展開的功能,不然混雜著一大堆的程式碼雖然容易看懂卻也很難看清楚。
註:有些元件的Flow會因客戶的需要而有很大的不同,這種元件一定要用結構型的方式設計。因為唯有明確地知道Action、Model與Properties的全部範圍才有可能作最佳的設計,同時避免掉繼承後override多次後的混亂。另一種類型像基本Data Model讀寫器那樣Action有不同的實作,這也應該將Flow與Action分開放置。
在元件裡流程控制相關的方法類型有以下五種(第一種放在Implementation),在註解裡定義一個方法類型欄位就能在處理程式裡取得對應值。
●Implementation Method(入口方法)
●Flow Method且被Implementation Method直接呼叫(被入口方法呼叫的流程方法)
●Flow Method但只被Flow Method呼叫(內部流程方法)
●Action Method且被Flow Method直接呼叫(被流程方法呼叫的動作方法)
●Action Method但只被Action Method呼叫(內部動作方法)
元件設計回歸到這樣的簡單結構在設計上已經很接近現在的主流作法,製作流程方法時毌須浪費時間在與結構佈置有關的行為,唯一需要作的是依註解規定撰寫應該有的註解內容──然而這本來就是應該做的事。至此,我們能夠在不多花費設計時間的前提下完成滿足以軟體工廠為前提的元件設計。
我會為了容易編輯註解的目的製作一個編輯器,除了可以把註解內容(多行文字)直覺地以UI欄位再編修之外,還可以詳細定義註解所要編輯的屬性並檢查值是否合法,設計人員只需要依畫面提示輸入註解內容而不用去注意註解的格式,便能得到符合規定的註解內容。另外還需要改寫Java編輯器,增加註解可收合或展開的功能,不然混雜著一大堆的程式碼雖然容易看懂卻也很難看清楚。
註:有些元件的Flow會因客戶的需要而有很大的不同,這種元件一定要用結構型的方式設計。因為唯有明確地知道Action、Model與Properties的全部範圍才有可能作最佳的設計,同時避免掉繼承後override多次後的混亂。另一種類型像基本Data Model讀寫器那樣Action有不同的實作,這也應該將Flow與Action分開放置。
2009年4月22日 星期三
U24 根本的建立(9)──註解Data Model
截至目前需要定義的註解類型有以下幾種:
●資料檔案裡的註解。這裡討論的是應用在基本Data Model編輯器所用的定義註解。
●Java Doc註解。應用在程式碼的Class、Attribute與Method的說明。
●Java Comment。Java的標準註解,用以說明Method內部的程式區塊。
●每個知識庫資訊的說明附帶的描述內容。
目前Java程式可以使用的註解有Java Doc(Class與Method)、annotation(Method)與Comment(Method內部)三種,我選用作為註解Data Model使用的是Java Doc與Comment。
這裡應該依註解全部的應用可能來決定註解Date Model通用的方法,並依得到的結果於基本Data Model中再定義CommentDateModelInterface來對應。所有註解若源自同一根本的CommentDataModelAbstract,就表示可藉由對應的parser在各種實際註解中作任意格式的轉換。
檢視現在的基本Data Model,其具有的元素與註解的對應如下:(注意:程式的Java Doc與程式本身在轉換工具裡是分離的)
●name:沒有使用。
●value:描述內容,格式為字串。
●comment:沒有使用。
●attributes:存放與註解關聯的實際物件鍵值,以key-value的方式存在。匯出時會放置到與property同層級的地方。
●children(properties):註解專用的欄位,以key-collection的方式存在。因為註解欄位的內容有數種意義,所以應該定義為CommentFieldDataModelInterface放在集合裡。
應該可以發現BeanDataModel是CommentDataModel的子集合, workspace在此加入CommentDataModel並修改BeanDataModel的繼承關係(BeanDataModel提供基本的properties操作而CommentDataModel改寫之);另外要準備CommentFieldDataModelInterface作為CommentDataModel的屬性方法參數(屬性的字串值要在內部轉換為CommentFieldDataModelInterface物件)。

在這裡定義的是可應用於各種註解的通用資料物件,未來為了符合四種註解型態必須要再延伸定義四種註解Data Model與四種註解Data Model讀寫器配合實際的應用。
●資料檔案裡的註解。這裡討論的是應用在基本Data Model編輯器所用的定義註解。
●Java Doc註解。應用在程式碼的Class、Attribute與Method的說明。
●Java Comment。Java的標準註解,用以說明Method內部的程式區塊。
●每個知識庫資訊的說明附帶的描述內容。
目前Java程式可以使用的註解有Java Doc(Class與Method)、annotation(Method)與Comment(Method內部)三種,我選用作為註解Data Model使用的是Java Doc與Comment。
這裡應該依註解全部的應用可能來決定註解Date Model通用的方法,並依得到的結果於基本Data Model中再定義CommentDateModelInterface來對應。所有註解若源自同一根本的CommentDataModelAbstract,就表示可藉由對應的parser在各種實際註解中作任意格式的轉換。
檢視現在的基本Data Model,其具有的元素與註解的對應如下:(注意:程式的Java Doc與程式本身在轉換工具裡是分離的)
●name:沒有使用。
●value:描述內容,格式為字串。
●comment:沒有使用。
●attributes:存放與註解關聯的實際物件鍵值,以key-value的方式存在。匯出時會放置到與property同層級的地方。
●children(properties):註解專用的欄位,以key-collection的方式存在。因為註解欄位的內容有數種意義,所以應該定義為CommentFieldDataModelInterface放在集合裡。
應該可以發現BeanDataModel是CommentDataModel的子集合, workspace在此加入CommentDataModel並修改BeanDataModel的繼承關係(BeanDataModel提供基本的properties操作而CommentDataModel改寫之);另外要準備CommentFieldDataModelInterface作為CommentDataModel的屬性方法參數(屬性的字串值要在內部轉換為CommentFieldDataModelInterface物件)。
在這裡定義的是可應用於各種註解的通用資料物件,未來為了符合四種註解型態必須要再延伸定義四種註解Data Model與四種註解Data Model讀寫器配合實際的應用。
2009年4月20日 星期一
U23 將程式碼視為Model,產出文件視為View
“這個功能的流程大概是什麼樣子?”“功能實作時呼叫了哪些元件的方法?”……,之前詢問快速完成功能的同事時,都會得到很經典的一句:“你要的東西全部都在程式碼裡,100%正確而且100%可以正常執行!”。所有人都同意東西全在程式碼裡,但是其他人要花多少時間才能取得自己想要的資訊?
一個功能使用UML來描述時至少需要四張圖(Use Case、Activity、Class、Sequence),畫這些圖的時間遠大於程式寫作的時間,更何況未來還需要另外製作各種使用的水平與垂直追溯表!額外花費心力完成一堆文件後,日後遇到程式碼的修改還得同時修改一大堆文件,這樣的工作內容有誰可以接受?要我也不想這麼做。
既然程式碼裡有完整且正確的所有資訊,又同時需要數份描述那些資訊的文件產出,那麼應用MVC Design Pattern設計一個轉換工具(Controller)把程式碼的內容(Model)轉出為各式各樣的對應文件(View)不是很理想嗎?文件可以制訂出固定不變的格式,規定程式碼的寫作格式有助於固定住轉換來源,兩者是達成功能的必要條件。
即使固定了設計的結構,但是不同程式語言的解析方法不一樣,每一個人對於同一種語言的寫作方式也不同,要寫出包含各種不同寫法的轉換工具近乎於不可能;我所能想到的就是在依設計準則安排Class與Method的佈置,同時再定義出固定不變的註解格式來提供轉換工具讀取(讓人快速看懂也是目的)。
Class與Method的佈置提供的是轉換工具處理的流程,註解內容則是轉換工具處理的動作,這兩類規格的定義讓程式碼與文件得以作有關聯的轉換(甚至可以做到註解的雙向轉換)。實作的重點在於註解Data Model的統一定義,這正是接下來要進行的主題。

一個功能使用UML來描述時至少需要四張圖(Use Case、Activity、Class、Sequence),畫這些圖的時間遠大於程式寫作的時間,更何況未來還需要另外製作各種使用的水平與垂直追溯表!額外花費心力完成一堆文件後,日後遇到程式碼的修改還得同時修改一大堆文件,這樣的工作內容有誰可以接受?要我也不想這麼做。
既然程式碼裡有完整且正確的所有資訊,又同時需要數份描述那些資訊的文件產出,那麼應用MVC Design Pattern設計一個轉換工具(Controller)把程式碼的內容(Model)轉出為各式各樣的對應文件(View)不是很理想嗎?文件可以制訂出固定不變的格式,規定程式碼的寫作格式有助於固定住轉換來源,兩者是達成功能的必要條件。
即使固定了設計的結構,但是不同程式語言的解析方法不一樣,每一個人對於同一種語言的寫作方式也不同,要寫出包含各種不同寫法的轉換工具近乎於不可能;我所能想到的就是在依設計準則安排Class與Method的佈置,同時再定義出固定不變的註解格式來提供轉換工具讀取(讓人快速看懂也是目的)。
Class與Method的佈置提供的是轉換工具處理的流程,註解內容則是轉換工具處理的動作,這兩類規格的定義讓程式碼與文件得以作有關聯的轉換(甚至可以做到註解的雙向轉換)。實作的重點在於註解Data Model的統一定義,這正是接下來要進行的主題。
2009年4月17日 星期五
U22 根本的建立(8)──知識庫的維護功能
使用,是根據現有物件的放置方式加以運用,但是有用的物件要存放到指定的位置需要將原本散落在各種文件裡的有用內容收集到指定的存放位置。在有用物件與儲存庫之間的關聯,就產生了各種維護功能的需求。
“從各種文件裡取得有用的資訊放入知識庫”是第一個維護需求。這個需求要成立的前提是必須能夠定義總共有哪些文件與每份文件的格式,CMMI或ISO導入的可以有效地在分析開發流程的同時固定所有產出文件的數量與格式。我們可以想像若是文件的數量與格式不停地變動,這個需求根本不可能完成。另外收集的資訊應註明作者與出處以便未來可以追溯來源,因此在收集資訊的同時也要額外收集這些欄位。
“資訊放入知識庫前需要被review”是第二個維護需求。如同程式碼在放入儲存庫前有同步比較差異的功能,收集的資訊也應該有類似的機制加以比較篩選來避免重覆或是無用資訊的問題;這也表示我們需要一個資訊暫存區與比較的設計。現在網路上有些討論區或留言版由於無法過濾內容且採不記名方式,因而存在了非常多的垃圾留言,這種現象一定要避免。
“每個版本的產生要追溯出有哪些變動”是第三個維護需求。就像標準的文件異動時要額外列出內容變動列表、系統更新版本時列出程式異動清單那樣,知識庫的維護也應該要有類似的記錄。維護記錄也必須具備不同的查詢方式以滿足針對版本、時間、作者、來源……等等不同面向的查詢。
“每個單位將有用資訊集合為中間檔提交review”是第四個維護需求。公司進行的專案可能四散在不同場所(全球化的公司也會如此),在資訊的同步必然會有衝突或是連線上的問題。讓每一個開發團隊都能事先抽取要進入知識庫的內容交給特定單位同步與review,會有集中處理的好處;而且具備中間檔的好處是在未來可以任意變動資料的來源卻只有很小的影響。
一切聽起來都很理想,不過從文件抽取內容很簡單,但是該如何從程式碼裡抽取有用資訊呢?或者說,因為程式碼的變動性過大,我們應該從程式碼裡抽取資訊嗎?
“從各種文件裡取得有用的資訊放入知識庫”是第一個維護需求。這個需求要成立的前提是必須能夠定義總共有哪些文件與每份文件的格式,CMMI或ISO導入的可以有效地在分析開發流程的同時固定所有產出文件的數量與格式。我們可以想像若是文件的數量與格式不停地變動,這個需求根本不可能完成。另外收集的資訊應註明作者與出處以便未來可以追溯來源,因此在收集資訊的同時也要額外收集這些欄位。
“資訊放入知識庫前需要被review”是第二個維護需求。如同程式碼在放入儲存庫前有同步比較差異的功能,收集的資訊也應該有類似的機制加以比較篩選來避免重覆或是無用資訊的問題;這也表示我們需要一個資訊暫存區與比較的設計。現在網路上有些討論區或留言版由於無法過濾內容且採不記名方式,因而存在了非常多的垃圾留言,這種現象一定要避免。
“每個版本的產生要追溯出有哪些變動”是第三個維護需求。就像標準的文件異動時要額外列出內容變動列表、系統更新版本時列出程式異動清單那樣,知識庫的維護也應該要有類似的記錄。維護記錄也必須具備不同的查詢方式以滿足針對版本、時間、作者、來源……等等不同面向的查詢。
“每個單位將有用資訊集合為中間檔提交review”是第四個維護需求。公司進行的專案可能四散在不同場所(全球化的公司也會如此),在資訊的同步必然會有衝突或是連線上的問題。讓每一個開發團隊都能事先抽取要進入知識庫的內容交給特定單位同步與review,會有集中處理的好處;而且具備中間檔的好處是在未來可以任意變動資料的來源卻只有很小的影響。
一切聽起來都很理想,不過從文件抽取內容很簡單,但是該如何從程式碼裡抽取有用資訊呢?或者說,因為程式碼的變動性過大,我們應該從程式碼裡抽取資訊嗎?
2009年4月16日 星期四
U21 根本的建立(7)──知識庫的使用功能
反應快的人主要是因為接觸到的知識被“記憶”、被“分類”、且有“適當的關聯”,但是這對於公司而言這只有少數人能具有,況且每個人的記憶都分散而難以同步、使用。對一個開發團隊來說,知識庫就像是將大家腦中的知識聯集起來作組織化的存放,同時又要讓每一位成員快速地找到自己想要的資訊。由此可知知識庫若應用到極致將會是多麼有生產力。
“將所有的資訊作組織化的存放”是第一個功能需求。談需求時我們總希望客戶直接提供百分之百的詳細規格,但設計知識庫卻不可能有這種東西。依建立的日期時間依序存放是比較理想的方式,而且所有的資訊只放在一個表格裡;雖然建立一些分類分開存放也是不錯的點子但是那都可以藉由關聯作出分類,同時“唯一存在”的儲存位置也較易於管理。有存放就會有CRUD連帶需要的子功能。
“儲存的資訊有最適切的關聯”是第二個功能需求,這也沒法列出詳細規格。如同關聯式資料庫的表格定義,每一種關聯都應該為之建立一個專屬的欄位,在分類搜尋時才能找出符合條件的集合。知識庫要具有哪些特性、各要怎麼定義才會使所有資訊之間有最適切的關聯?這是相當值得研究的課題。
“能迅速找出符合條件的所有資訊”是第三個功能需求。存放與關聯都作過良好定義的話,這個需求看來只需要在UI的使用便利性下功夫就會有良好的成效。“全文檢索”是另一個好用的功能,但考量到技術層面倒也不是非做到不可。
“每一則資訊的變更歷史”是第四個功能需求。可追溯的變更是重要的潛在需求,在查到資訊的同時應能另外顯示該則資訊歷來的編修記錄;感覺起來很像是程式碼的儲存庫功能。這對使用者來說並非必要,但是對於維護功能卻需要藉此追溯記錄。
註:同事說部落格裡的內容實在太多,應該安排更容易上手的分類。若把部落格視為知識庫,每篇文章依照日期時間逐一放入到這唯一的儲存區;目前欠缺的就是依照學習需求分類的關聯索引,這也表示所以文章的標籤必須加以重新編排。
“將所有的資訊作組織化的存放”是第一個功能需求。談需求時我們總希望客戶直接提供百分之百的詳細規格,但設計知識庫卻不可能有這種東西。依建立的日期時間依序存放是比較理想的方式,而且所有的資訊只放在一個表格裡;雖然建立一些分類分開存放也是不錯的點子但是那都可以藉由關聯作出分類,同時“唯一存在”的儲存位置也較易於管理。有存放就會有CRUD連帶需要的子功能。
“儲存的資訊有最適切的關聯”是第二個功能需求,這也沒法列出詳細規格。如同關聯式資料庫的表格定義,每一種關聯都應該為之建立一個專屬的欄位,在分類搜尋時才能找出符合條件的集合。知識庫要具有哪些特性、各要怎麼定義才會使所有資訊之間有最適切的關聯?這是相當值得研究的課題。
“能迅速找出符合條件的所有資訊”是第三個功能需求。存放與關聯都作過良好定義的話,這個需求看來只需要在UI的使用便利性下功夫就會有良好的成效。“全文檢索”是另一個好用的功能,但考量到技術層面倒也不是非做到不可。
“每一則資訊的變更歷史”是第四個功能需求。可追溯的變更是重要的潛在需求,在查到資訊的同時應能另外顯示該則資訊歷來的編修記錄;感覺起來很像是程式碼的儲存庫功能。這對使用者來說並非必要,但是對於維護功能卻需要藉此追溯記錄。
註:同事說部落格裡的內容實在太多,應該安排更容易上手的分類。若把部落格視為知識庫,每篇文章依照日期時間逐一放入到這唯一的儲存區;目前欠缺的就是依照學習需求分類的關聯索引,這也表示所以文章的標籤必須加以重新編排。
2009年4月15日 星期三
U20 開發團隊必要的絕對重用──知識庫
在公司裡與設計有關的討論裡,我一直堅持著“絕對重用”的原則。除了程式裡變數與方法使用的唯一化之外,避免想法散落在各人腦中在需要時卻無法取得最新狀態的問題而必須建立的知識庫,也是我希望建立的制度。當然,程式碼與知識庫之間同樣應該有自動化同步內容的機制才不至於造成同仁額外花費時間去做,能夠架構在二者之間的橋樑就只有程式的註解。
開發時會存在的絕對重用有:依設計準則所規定的統一元件結構、提供編輯器的一致註解、收集全部有用資訊的知識庫。現在元件結構已經確定,接下來需要的是繼承自基本Data Model的註解Data Model(有程式註解與檔案註解兩種,後者是提供通用編輯器使用的),還有放置從程式註解Data Model取得資訊的知識庫。
曾在iThome網站看到這麼一篇文章(重新思考知識管理,http://www.ithome.com.tw/itadm/article.php?c=52119),這與我心中的理想藍圖不謀而合。對一般使用的知識庫而言,規定資料文件的編排格式再從固定的位置抽取有用的資訊同步進來是較為容易的;但是對於程式碼而言,要能用通用程式抽取有用的資訊的話,勢必要規定所有程式碼一致的編排方式與寫法才能辦到。千變萬化的程式設計與實作寫法是達成這個功能的最大難處,也唯有嚴格規定產出結構與註解格式才有辦法符合知識庫的基本要求。
根據這樣的理想,產生了以下的工作項目等待實現:
●註解內容與基本Data Model的相互轉換
●知識庫的建立與查詢與建立版本功能
●註解內容與知識庫內容比較與匯入
●基本Data Model的註解轉換為基本Data Model
●使用基本Data Model編輯器建立程式註解格式編輯工具
開發時會存在的絕對重用有:依設計準則所規定的統一元件結構、提供編輯器的一致註解、收集全部有用資訊的知識庫。現在元件結構已經確定,接下來需要的是繼承自基本Data Model的註解Data Model(有程式註解與檔案註解兩種,後者是提供通用編輯器使用的),還有放置從程式註解Data Model取得資訊的知識庫。
曾在iThome網站看到這麼一篇文章(重新思考知識管理,http://www.ithome.com.tw/itadm/article.php?c=52119),這與我心中的理想藍圖不謀而合。對一般使用的知識庫而言,規定資料文件的編排格式再從固定的位置抽取有用的資訊同步進來是較為容易的;但是對於程式碼而言,要能用通用程式抽取有用的資訊的話,勢必要規定所有程式碼一致的編排方式與寫法才能辦到。千變萬化的程式設計與實作寫法是達成這個功能的最大難處,也唯有嚴格規定產出結構與註解格式才有辦法符合知識庫的基本要求。
根據這樣的理想,產生了以下的工作項目等待實現:
●註解內容與基本Data Model的相互轉換
●知識庫的建立與查詢與建立版本功能
●註解內容與知識庫內容比較與匯入
●基本Data Model的註解轉換為基本Data Model
●使用基本Data Model編輯器建立程式註解格式編輯工具
2009年4月13日 星期一
U19 第三個元件(3)──基本Data Model編輯器的存取
畫面呈現的作法確定之後,就只剩下建立Data Model與編輯器的對應關係。在使用上的設計有幾個簡單的方向:整個Data Model對應一個頁面或多個頁面的存取、對於欄位內容值的存取與屬性變更等。
public boolean setDataModelValue(ModelParserModelInterface model);
public boolean getDataModelValue(ModelParserModelInterface model);
public Object getValue(String fieldId) throws IDNotFoundException;
public boolean setValue(String fieldId, Object Value) throws IDNotFoundException;
public Object getProperty(String fieldId, String propName) throws IDNotFoundException;
public boolean setProperty(String fieldId, String propName, Object Value) throws IDNotFoundException;
public Object getValue(String pageId, String fieldId) throws IDNotFoundException;
public boolean setValue(String pageId, String fieldId, Object Value) throws IDNotFoundException;
public Object getProperty(String pageId, String fieldId, String propName) throws IDNotFoundException;
public boolean setProperty(String pageId, String fieldId, String propName, Object Value) throws IDNotFoundException;
以上是大致需要的介面方法定義。UI的佈置會以一個Data Model對應一個頁面為主,在多個bean file的場合下會有JTree的對應佈置,在頁面的存取規則定義pageId來指定取得實際使用的那個;資料放入UI時會以bean id來命名,方法內傳入fieldId即可定位實際存取的欄位。
說真的,基本Data Model編輯器若是不做也沒什麼影響,因為對IT人員來說直接開啟檔案編輯內容是又快又簡單的事,但是對一般使用者來說卻相對地很困難,尤其在尋找想要修改的內容或是輸入XML的標籤有錯誤時根本無法達成。要能快速地清楚所有可以修改的設定與其代表的意義,同時限定與檢核輸入值的正確性,這些好處就只有基本Data Model編輯器可以快速提供。
註:這裡的內容並未實作在workspace裡,但是在之前的專案裡已驗證過可行。
public boolean setDataModelValue(ModelParserModelInterface model);
public boolean getDataModelValue(ModelParserModelInterface model);
public Object getValue(String fieldId) throws IDNotFoundException;
public boolean setValue(String fieldId, Object Value) throws IDNotFoundException;
public Object getProperty(String fieldId, String propName) throws IDNotFoundException;
public boolean setProperty(String fieldId, String propName, Object Value) throws IDNotFoundException;
public Object getValue(String pageId, String fieldId) throws IDNotFoundException;
public boolean setValue(String pageId, String fieldId, Object Value) throws IDNotFoundException;
public Object getProperty(String pageId, String fieldId, String propName) throws IDNotFoundException;
public boolean setProperty(String pageId, String fieldId, String propName, Object Value) throws IDNotFoundException;
以上是大致需要的介面方法定義。UI的佈置會以一個Data Model對應一個頁面為主,在多個bean file的場合下會有JTree的對應佈置,在頁面的存取規則定義pageId來指定取得實際使用的那個;資料放入UI時會以bean id來命名,方法內傳入fieldId即可定位實際存取的欄位。
說真的,基本Data Model編輯器若是不做也沒什麼影響,因為對IT人員來說直接開啟檔案編輯內容是又快又簡單的事,但是對一般使用者來說卻相對地很困難,尤其在尋找想要修改的內容或是輸入XML的標籤有錯誤時根本無法達成。要能快速地清楚所有可以修改的設定與其代表的意義,同時限定與檢核輸入值的正確性,這些好處就只有基本Data Model編輯器可以快速提供。
註:這裡的內容並未實作在workspace裡,但是在之前的專案裡已驗證過可行。
2009年4月10日 星期五
U18 第三個元件(2)──基本Data Model編輯器的層次
如果一個編輯器只能處理一個bean是非常浪費資源的,更何況一個bean file裡可以有多個bean,一個設定資料夾裡可以有多個bean file。folder-bean file-bean-property的完整排列需要三維陣列,整個系統定義使用的設定檔都放置到同一個編輯器是這個元件的最終需求。
bean-property的對應如同上一篇提到的會由JPanel-Jcomponent來實作;folder-bean file-bean會選用JTree作兩層式的管理,bean file列示在第一層節點,bean則依附在對應的bean file之下。這樣的設計即使在面臨只開一個bean file的場合或是系統同時有多個設定資料夾,也只需要對應縮減或增加JTree的結構層級就可以符合需求。
回到屬性的編輯內容來看,讀取設定檔的內容與註解只能列出現在有定義的屬性,總計若有20個屬性而設定檔內只有10個有儲存值的話(有些不能放值以便有其他作用),目前的編輯器沒有辦法列出那10個不存在的屬性。解決這個問題必須另外定義一個檔案放置所有的屬性與UI定義,編輯器根據該頁面定義檔建立其專用的編輯畫面。這才是編輯器的完成型態。
提供便利的編輯器給使用者快速地改變所有設定檔的內容,設定檔可編輯的屬性同時能夠方便地更動,這兩種功能的組合就是SA Tool所需要的基本編輯界面。藉由檔案、頁面與屬性內容的擴充,SA Tool才能夠具有彈性地擴充需要的屬性來對應開發系統所需要的參數定義,之後再經由統一的元件結構與用法處理讀入的Properties調整元件的實際作用。
SA Tool需要的編輯器在UI上還需要另外定義其他與顯示無關的設定,像是判斷值開關其他屬性是否可以編輯、便利編輯的屬性群組化、外掛檢查輸入值的檢查類別……等等,這些都可以因應編輯的必要性予以加強。但是基本Data Model編輯器本身已經不容易實作了,往上堆疊設計的SA Tool自然更為複雜,而且還要搭配對應的開發方法論才能定義出適切範圍的正確屬性。
註:這裡的內容並未實作在workspace裡,但是在之前的專案裡已驗證過可行。
bean-property的對應如同上一篇提到的會由JPanel-Jcomponent來實作;folder-bean file-bean會選用JTree作兩層式的管理,bean file列示在第一層節點,bean則依附在對應的bean file之下。這樣的設計即使在面臨只開一個bean file的場合或是系統同時有多個設定資料夾,也只需要對應縮減或增加JTree的結構層級就可以符合需求。
回到屬性的編輯內容來看,讀取設定檔的內容與註解只能列出現在有定義的屬性,總計若有20個屬性而設定檔內只有10個有儲存值的話(有些不能放值以便有其他作用),目前的編輯器沒有辦法列出那10個不存在的屬性。解決這個問題必須另外定義一個檔案放置所有的屬性與UI定義,編輯器根據該頁面定義檔建立其專用的編輯畫面。這才是編輯器的完成型態。
提供便利的編輯器給使用者快速地改變所有設定檔的內容,設定檔可編輯的屬性同時能夠方便地更動,這兩種功能的組合就是SA Tool所需要的基本編輯界面。藉由檔案、頁面與屬性內容的擴充,SA Tool才能夠具有彈性地擴充需要的屬性來對應開發系統所需要的參數定義,之後再經由統一的元件結構與用法處理讀入的Properties調整元件的實際作用。
SA Tool需要的編輯器在UI上還需要另外定義其他與顯示無關的設定,像是判斷值開關其他屬性是否可以編輯、便利編輯的屬性群組化、外掛檢查輸入值的檢查類別……等等,這些都可以因應編輯的必要性予以加強。但是基本Data Model編輯器本身已經不容易實作了,往上堆疊設計的SA Tool自然更為複雜,而且還要搭配對應的開發方法論才能定義出適切範圍的正確屬性。
註:這裡的內容並未實作在workspace裡,但是在之前的專案裡已驗證過可行。
2009年4月8日 星期三
U17 第三個元件(1)──基本Data Model編輯器的頁面
當只存在一種Data Model時,就有機會為之定義通用編輯器提供給使用者快速編輯內容。編輯的方式有兩大類:一種是根據資料屬性的範圍修改各自的值,另一種是除了修改屬性值之外還允許增減不同名稱的屬性。前者以PropertiesDataModel的設定特性而後者是以BeanDataModel的屬性特性作為設計基礎;PropertiesDataModel可以視為不能變動屬性的BeanDataModel,定義設定檔時一定要使用bean file的方式才能兼顧未來的擴充性。
最底層的設計是將一個可定義的屬性對應到一個UI Bean,利用comment來標示這個UI Bean的實際類別與描述屬性;UI類別名稱會依序生成,同時呼叫描述屬性的對應方法(有些屬性需要加工處理,像是Jcombo的選單內容字串)。基本的定義屬性有:提示文字、生成類別、enable、visible與選單內容字串。提示文字與編輯欄位的tooltip都會顯示屬性原本的名稱。
欄位向上的集合是頁面,對應的節點是bean;允許定義的屬性是提示文字、生成類別與欄位寬度。頁面的寬度減去欄位寬度就是提示文字的寬度。再向上就是根節點beans,允許定義的屬性是提示文字、background、foreground、font、width與height。加上單頁式的編輯註解後,設定檔案的內容會像是下面的樣子,附圖是執行時的範例。
<!-- frame's name.
class=javax.swing.JFrame,background=0x0000ff,foreground=0xffff00,
font=monospaced-plain-16,width=400,height=300 -->
<beans>
<!—Page 0.
class=javax.swing.JPanel,fieldwidth=200-->
<bean id="FieldModel">
<!-- This is field1 prompt.
class=javax.swing.JTextField,enable=true,visible=true -->
<property name="field1" value="default1" />
<!-- This is field2 prompt.
class=javax.swing.JCheckBox,enable=true,visible=true -->
<property name="field2" value="true" />
<!-- This is field3 prompt.
class=javax.swing.JComboBox,enable=true,visible=true,items=|1|2|3 -->
<property name="field3" value="" />
<!-- .
class=javax.swing.JComboBox,enable=false,visible=true,items=|1|2|3 -->
<property name="field4" value="2" />
</bean>
</beans>

編輯欄位除了字串的設定外,還應該為list、map與listmap準備另外用對話盒放置的集合編輯器才算擁有完整的編輯功能。
註:這裡的內容並未實作在workspace裡,但是在之前的專案裡已驗證過可行。
最底層的設計是將一個可定義的屬性對應到一個UI Bean,利用comment來標示這個UI Bean的實際類別與描述屬性;UI類別名稱會依序生成,同時呼叫描述屬性的對應方法(有些屬性需要加工處理,像是Jcombo的選單內容字串)。基本的定義屬性有:提示文字、生成類別、enable、visible與選單內容字串。提示文字與編輯欄位的tooltip都會顯示屬性原本的名稱。
欄位向上的集合是頁面,對應的節點是bean;允許定義的屬性是提示文字、生成類別與欄位寬度。頁面的寬度減去欄位寬度就是提示文字的寬度。再向上就是根節點beans,允許定義的屬性是提示文字、background、foreground、font、width與height。加上單頁式的編輯註解後,設定檔案的內容會像是下面的樣子,附圖是執行時的範例。
<!-- frame's name.
class=javax.swing.JFrame,background=0x0000ff,foreground=0xffff00,
font=monospaced-plain-16,width=400,height=300 -->
<beans>
<!—Page 0.
class=javax.swing.JPanel,fieldwidth=200-->
<bean id="FieldModel">
<!-- This is field1 prompt.
class=javax.swing.JTextField,enable=true,visible=true -->
<property name="field1" value="default1" />
<!-- This is field2 prompt.
class=javax.swing.JCheckBox,enable=true,visible=true -->
<property name="field2" value="true" />
<!-- This is field3 prompt.
class=javax.swing.JComboBox,enable=true,visible=true,items=|1|2|3 -->
<property name="field3" value="" />
<!-- .
class=javax.swing.JComboBox,enable=false,visible=true,items=|1|2|3 -->
<property name="field4" value="2" />
</bean>
</beans>
編輯欄位除了字串的設定外,還應該為list、map與listmap準備另外用對話盒放置的集合編輯器才算擁有完整的編輯功能。
註:這裡的內容並未實作在workspace裡,但是在之前的專案裡已驗證過可行。
2009年4月6日 星期一
U16 元件各自的Package與Properties設定
使用結構設計的元件最好是一個Package內只放一個Component,主要的原因當然是由於每個完整Component裡至少會有20個檔案,混雜了兩個以上元件的Package根本會令人不知道裡面的程式到底誰是誰的。而更重要的是多個元件對應到一個資料夾是多對一的關係,倘使元件的放置需要加以切割又會面臨到重組的問題。
有一個觀念必須釐清:並不是所有的功能單位都要設計為Component,有些實作適合以Class的形式存在(像是LogUtil與UI Bean),而包含較多邏輯性內容的功能偏向於包裝為Component(像是ApplLog)。Component會需要傳入參數來因應不同狀況下的處理方式,參數的來源有兩大類:呼叫方法時傳入(執行動作的參考狀態)與定義在元件用的參數檔(一般情況下的通用狀態)。
建議使用Bean File的形式來存放多個Component的參數設定,一個bean對應到一個Component設定並將ComponentID放到id的屬性裡。BeanFileDataModelInterface增加一個方法,在系統初始化時取出元件的Properties後放到所屬的Component以完成元件的初始化。
public void getBeanProperties(String beanId, BasePropertiesInterface properties) throws BeanNotFoundException;
ApplLog元件使用程式初始化時需要有這些程式碼:
ApplLogProperties properties = new ApplLogProperties();
((Properties) properties).setProperty(BasePropertiesInterface.CLASS_FLOW, "tw.idv.joying.component.appllog.ApplLogFlow");
((Properties) properties).setProperty(BasePropertiesInterface.CLASS_ACTION, "tw.idv.joying.component.appllog.ApplLogAction");
properties.setLogLevel(LogUtil.INFO);
ApplLog.getInstance().setApplLogProperties(properties);
將參數改存放到XML檔案會是這樣的形式:
<beans>
<bean id="tw.idv.joying.component.appllog.ApplLog">
<property name="classFlow" value="tw.idv.joying.component.appllog.ApplLogFlow" />
<property name="classAction" value="tw.idv.joying.component.appllog.ApplLogAction" />
<property name="logLevel" value="4" />
</bean>
</beans>
針對ApplLog的初始化可以改寫成這樣:(ModelParser針對不同的檔案讀取設定可以包裝成一個通用API,只要傳入檔名與處理類型就能拿到資料物件)
ApplLogProperties properties = new ApplLogProperties();
beanFile.getBeanProperties(ApplLogInterface.COMPONENTID, properties);
ApplLog.getInstance().setApplLogProperties(properties);
最後可以改寫初始化的程式碼,不再需要每個元件都準備自己的設定檔,只要使用固定的初始化方式就能夠集中管理所有元件的設定。處理原則在初始化元件時取得beanId,由於命名方式一致可以捨棄new的寫法而改用Class.forName()取得元件的Properties物件,並傳入到元件裡作初始化。如此一來也統一了元件的初始化設定功能。
註:這裡的內容並未實作在workspace裡,但是在之前的專案裡已驗證過可行。
有一個觀念必須釐清:並不是所有的功能單位都要設計為Component,有些實作適合以Class的形式存在(像是LogUtil與UI Bean),而包含較多邏輯性內容的功能偏向於包裝為Component(像是ApplLog)。Component會需要傳入參數來因應不同狀況下的處理方式,參數的來源有兩大類:呼叫方法時傳入(執行動作的參考狀態)與定義在元件用的參數檔(一般情況下的通用狀態)。
建議使用Bean File的形式來存放多個Component的參數設定,一個bean對應到一個Component設定並將ComponentID放到id的屬性裡。BeanFileDataModelInterface增加一個方法,在系統初始化時取出元件的Properties後放到所屬的Component以完成元件的初始化。
public void getBeanProperties(String beanId, BasePropertiesInterface properties) throws BeanNotFoundException;
ApplLog元件使用程式初始化時需要有這些程式碼:
ApplLogProperties properties = new ApplLogProperties();
((Properties) properties).setProperty(BasePropertiesInterface.CLASS_FLOW, "tw.idv.joying.component.appllog.ApplLogFlow");
((Properties) properties).setProperty(BasePropertiesInterface.CLASS_ACTION, "tw.idv.joying.component.appllog.ApplLogAction");
properties.setLogLevel(LogUtil.INFO);
ApplLog.getInstance().setApplLogProperties(properties);
將參數改存放到XML檔案會是這樣的形式:
<beans>
<bean id="tw.idv.joying.component.appllog.ApplLog">
<property name="classFlow" value="tw.idv.joying.component.appllog.ApplLogFlow" />
<property name="classAction" value="tw.idv.joying.component.appllog.ApplLogAction" />
<property name="logLevel" value="4" />
</bean>
</beans>
針對ApplLog的初始化可以改寫成這樣:(ModelParser針對不同的檔案讀取設定可以包裝成一個通用API,只要傳入檔名與處理類型就能拿到資料物件)
ApplLogProperties properties = new ApplLogProperties();
beanFile.getBeanProperties(ApplLogInterface.COMPONENTID, properties);
ApplLog.getInstance().setApplLogProperties(properties);
最後可以改寫初始化的程式碼,不再需要每個元件都準備自己的設定檔,只要使用固定的初始化方式就能夠集中管理所有元件的設定。處理原則在初始化元件時取得beanId,由於命名方式一致可以捨棄new的寫法而改用Class.forName()取得元件的Properties物件,並傳入到元件裡作初始化。如此一來也統一了元件的初始化設定功能。
註:這裡的內容並未實作在workspace裡,但是在之前的專案裡已驗證過可行。
2009年4月3日 星期五
U15 第二個元件(5)──讀寫Data Model的單元測試
由於workspace裡只實作了XML、Text與Properties三種資料類型,單元測試也只做好這三種測試。測試的檔案放在junit/settings/datafile資料夾下,測試的結果如下圖:(save方法的測試是寫檔後再讀回為data model測試內容,並沒有實際測試)

此時再回頭看基本Data Model相關的package下的所有檔案,雖然裡面有39個檔案,但是現在來看應該每一支程式的功用是什麼都一目瞭然。(配合U10的Class Diagram可以更快進入狀況)

元件庫現在的結構圖:

此時再回頭看基本Data Model相關的package下的所有檔案,雖然裡面有39個檔案,但是現在來看應該每一支程式的功用是什麼都一目瞭然。(配合U10的Class Diagram可以更快進入狀況)
元件庫現在的結構圖:
2009年4月2日 星期四
U14 第二個元件(4)──讀寫Bean與Object檔案
<beans>
<bean id="bean1" class="BeanClass1">
<property name="prop1" value="value1"/>
<property name="prop2">
<list>
<value>value2-1</value>
</list>
</property>
<property name="prop3">
<map>
<entry>
<key>
<value>key1</value>
</key>
<value>value1</value>
</entry>
<entry>
<key>
<value>key2</value>
</key>
<value>value2</value>
</entry>
</map>
</property>
</bean>
<bean class="BeanClass2" id="bean2">
<property name="prop" value="value"/>
</bean>
</beans>
在這個通用的XML結構裡,隱含了beans與bean各自對應的BeanFileDataModelInterface與BeanDataModelInterface。前者負責的是對所有bean的管理功能,後者提供的是每一個bean內部的property存取與管理,以及id、class的存取方法。同時對於bean裡的tag也必須全部定義對應的常數。
final static String NODE_NAME = "bean";
final static String NODE_ATTRID = "id";
final static String NODE_ATTRCLASS = "class";
final static String PROPERTY_NAME = "property";
final static String PROPERTY_ATTRNAME = "name";
final static String PROPERTY_ATTRVALUE = "value";
final static String VALUE_NAME = "value";
final static String LIST_NAME = "list";
final static String MAP_NAME = "map";
final static String MAP_ENTRY = "entry";
final static String MAP_KEY = "key";
final static String LISTMAP_NAME = "listmap";

BeanDataModelAbstract繼承自XMLDataModelAbstract,由於bean的child都會以property的形式存在,因此全部property相關的方法事實上都是對child操作。另外在property的物件定義上除了原本的list、map基本類型之外,再加上自己特有的listmap以符合不同的需求。BeanParserActionAbstract可以繼承XMLParserActionAbstract再改寫對property存取的部分。
BeanFileDataModel與BeanDataModel可以衍伸出一種極重要的變型:ObjectDataModel,它會依照bean裡class屬性定義的類別名稱創造出該類別的物件實體。實作時物件應繼承基本Data Model以擁有底層所規定的一切特性,同時在自有的介面上具有符合上層想要操作的所有動作內容。這個作法實現了所有資料物件的根源都來自同一個底層Data Model的理想。
註:這裡的內容並未實作在workspace裡,但是在之前的專案裡已驗證過可行。
<bean id="bean1" class="BeanClass1">
<property name="prop1" value="value1"/>
<property name="prop2">
<list>
<value>value2-1</value>
</list>
</property>
<property name="prop3">
<map>
<entry>
<key>
<value>key1</value>
</key>
<value>value1</value>
</entry>
<entry>
<key>
<value>key2</value>
</key>
<value>value2</value>
</entry>
</map>
</property>
</bean>
<bean class="BeanClass2" id="bean2">
<property name="prop" value="value"/>
</bean>
</beans>
在這個通用的XML結構裡,隱含了beans與bean各自對應的BeanFileDataModelInterface與BeanDataModelInterface。前者負責的是對所有bean的管理功能,後者提供的是每一個bean內部的property存取與管理,以及id、class的存取方法。同時對於bean裡的tag也必須全部定義對應的常數。
final static String NODE_NAME = "bean";
final static String NODE_ATTRID = "id";
final static String NODE_ATTRCLASS = "class";
final static String PROPERTY_NAME = "property";
final static String PROPERTY_ATTRNAME = "name";
final static String PROPERTY_ATTRVALUE = "value";
final static String VALUE_NAME = "value";
final static String LIST_NAME = "list";
final static String MAP_NAME = "map";
final static String MAP_ENTRY = "entry";
final static String MAP_KEY = "key";
final static String LISTMAP_NAME = "listmap";
BeanDataModelAbstract繼承自XMLDataModelAbstract,由於bean的child都會以property的形式存在,因此全部property相關的方法事實上都是對child操作。另外在property的物件定義上除了原本的list、map基本類型之外,再加上自己特有的listmap以符合不同的需求。BeanParserActionAbstract可以繼承XMLParserActionAbstract再改寫對property存取的部分。
BeanFileDataModel與BeanDataModel可以衍伸出一種極重要的變型:ObjectDataModel,它會依照bean裡class屬性定義的類別名稱創造出該類別的物件實體。實作時物件應繼承基本Data Model以擁有底層所規定的一切特性,同時在自有的介面上具有符合上層想要操作的所有動作內容。這個作法實現了所有資料物件的根源都來自同一個底層Data Model的理想。
註:這裡的內容並未實作在workspace裡,但是在之前的專案裡已驗證過可行。
2009年4月1日 星期三
U13 第二個元件(3)──讀寫CSV與Excel檔案
TableDataModel顧名思義就是要處理表格型的資料。應用到實際存放搜尋的資料庫內容時,比起ResultSet會佔住資料庫的資源,或是取得ResultSet後再放到String[][]在取用資料時不確定在哪裡,TableDataModel提供了方便的存取介面且易於改寫內部;物件轉換為字串後再壓縮也可以節省網路傳輸的頻寬。
第一個子節點只存放欄位的名稱與欄位的型態而不存放資料(我常用的設定是將所有欄位型態都定義為字串),名稱用逗號分隔放在放在一個attribute;往下依序每個子節點都是一筆記錄,記錄裡的每個欄位值都使用欄位名稱放在attribute裡。實際的對應範例如下圖所示。

TableDataModelInterface定義了一些存取欄位名稱與值的方法,實作就根據資料在基本Data Model裡的放置而設計。再往上應該準備CSVParserAction與ExcelParserAction兩個存取檔案的類別,前者依逗號分隔規則切割資料,後者使用JXL函式庫來存取Excel檔案內的資料;在資料庫的select應用場合可以解析sql command內的欄位名稱,直接new TableDataModel後放入欄位名稱與搜尋的結果。
public int getFieldCount();
public String[] listFieldNames();
public boolean setFieldNames(String[] fieldNames);
public int getRecordCount();
public String[] getRecord(int index);
public boolean appendRecord(int index, String[] data);
public boolean removeRecord(int index);
public String[] listFieldValue(String fieldName);
public String[] listFieldValue(int fieldIndex);
public String[][] listTableValue();
如果對於這種寫法的速度覺得不滿意,當然可以改寫為更有效率的作法而不影響這個元件的設計。
註:這裡的內容並未實作在workspace裡,但是在之前的專案裡已驗證過可行。
第一個子節點只存放欄位的名稱與欄位的型態而不存放資料(我常用的設定是將所有欄位型態都定義為字串),名稱用逗號分隔放在放在一個attribute;往下依序每個子節點都是一筆記錄,記錄裡的每個欄位值都使用欄位名稱放在attribute裡。實際的對應範例如下圖所示。

TableDataModelInterface定義了一些存取欄位名稱與值的方法,實作就根據資料在基本Data Model裡的放置而設計。再往上應該準備CSVParserAction與ExcelParserAction兩個存取檔案的類別,前者依逗號分隔規則切割資料,後者使用JXL函式庫來存取Excel檔案內的資料;在資料庫的select應用場合可以解析sql command內的欄位名稱,直接new TableDataModel後放入欄位名稱與搜尋的結果。
public int getFieldCount();
public String[] listFieldNames();
public boolean setFieldNames(String[] fieldNames);
public int getRecordCount();
public String[] getRecord(int index);
public boolean appendRecord(int index, String[] data);
public boolean removeRecord(int index);
public String[] listFieldValue(String fieldName);
public String[] listFieldValue(int fieldIndex);
public String[][] listTableValue();
如果對於這種寫法的速度覺得不滿意,當然可以改寫為更有效率的作法而不影響這個元件的設計。
註:這裡的內容並未實作在workspace裡,但是在之前的專案裡已驗證過可行。
2009年3月30日 星期一
U12 Review與Refactoring
基本Data Model讀寫器是結構複雜的元件,雖然Class的架構佈置與Method的設計準則都已經具有規範,但是實際的產出是否符合就需要review進而refactor以符合規範。進行的時機點在元件設計與實作完成,進行單元測試的前後都可以。
此時的調適原則有以下幾個方向:
調整常數與方法的定義層級。檢查元件中定義的常數與方法是否放在正確的對應層級,需要逐一檢查常數與方法並思索其意義應在哪裡表示。有時會遇到難以界定的情況,可以討論或是詢問其他有經驗的人來判別,而且所有的常數與方法都要在此時定義妥當。
調整Flow與Action內應該抽出為獨立方法的程式。在Flow與Action細部設計所定義的分解動作,是否應要求將各個動作獨立為方法。有相當設計經驗的人時常直接把一個動作所需的程式寫在應該抽取方法的地方,造成一個範圍大小混合的程式區塊,在這裡要避免產生這樣的結果。
使用最好的寫法實作方法。如果以可以達成功能作為結果,方法內的實作可能不是最佳的作法。在設計時可以指定寫法,如果原本的不適用在review的同時也可以重新選擇寫法。例如排序,雖然都可以排序集合內的物件,但是速度的快慢與寫法的難易有所不同。
各部分確認正確後補完註解。當元件內所有的內容都回歸應存在的地方並通過測試,就可以著手補上註解;Interface、Class、Data、Method與逐段的程式都要補齊。註解並不是有寫就好,其格式也會有一致的規定。(這裡先不寫上註解,後續會有定義註解與應用的說明)
調整後的元件於通過單元測試後,暫時可以視為完成並進行設計另一個元件。
此時的調適原則有以下幾個方向:
調整常數與方法的定義層級。檢查元件中定義的常數與方法是否放在正確的對應層級,需要逐一檢查常數與方法並思索其意義應在哪裡表示。有時會遇到難以界定的情況,可以討論或是詢問其他有經驗的人來判別,而且所有的常數與方法都要在此時定義妥當。
調整Flow與Action內應該抽出為獨立方法的程式。在Flow與Action細部設計所定義的分解動作,是否應要求將各個動作獨立為方法。有相當設計經驗的人時常直接把一個動作所需的程式寫在應該抽取方法的地方,造成一個範圍大小混合的程式區塊,在這裡要避免產生這樣的結果。
使用最好的寫法實作方法。如果以可以達成功能作為結果,方法內的實作可能不是最佳的作法。在設計時可以指定寫法,如果原本的不適用在review的同時也可以重新選擇寫法。例如排序,雖然都可以排序集合內的物件,但是速度的快慢與寫法的難易有所不同。
各部分確認正確後補完註解。當元件內所有的內容都回歸應存在的地方並通過測試,就可以著手補上註解;Interface、Class、Data、Method與逐段的程式都要補齊。註解並不是有寫就好,其格式也會有一致的規定。(這裡先不寫上註解,後續會有定義註解與應用的說明)
調整後的元件於通過單元測試後,暫時可以視為完成並進行設計另一個元件。
2009年3月28日 星期六
U11 第二個元件(2)──讀寫XML、Text、與Properties檔案
XMLParserActionAbstract是負責讀寫XML檔案內容到XML Model的程式。大致作法是從輸入的InputStream裡拿到DOM物件,再依序將name、value、comment與attrubutes、children放入資料物件的對應屬性;另一方面再由反方面匯出為字串並將之寫回指定的檔案。XMLDataModelInterface定義了ATTR_ID的常數並在addChild()時取值傳入,另外提供兩個可用xpath字串取得指定節點的方法可以快速拿到想要的節點。
對TextParserActionAbstract的設計是逐行讀入文字檔的內容,放到一個新建child的value。在TextDataModel裡每一個子節點代表了一行資料,另外定義getLineCount()與getTexts()兩個方法提供操作。目前沒有修改內容的需求,即使有也打算把資料對應到JtextArea物件在上面修改後再將內容更新回來。
PropertiesDataModelInterface是讀取properties檔案後的產出,其功能與JDK裡的Properties功能相同,整合到基本Data Model是為了資料讀寫的一致性以便適用在通用編輯器上。PropertiesParserActionAbstract針對這種類型的檔案,讀寫內容與資料物件同步。
這三種類型的檔案內容可謂基本型,因為儲存的格式與Data Model的格式全都有著一對一的對應。將不同格式的資料收集到同一種資料物件裡,意謂著繼承基本Data Model的所有資料物件都能夠用同樣的程式來處理。這種作法讓Data Model在根本上只存在一種唯一的類型,未來繼承出去的所有資料物件全部具有同樣的特性。
對TextParserActionAbstract的設計是逐行讀入文字檔的內容,放到一個新建child的value。在TextDataModel裡每一個子節點代表了一行資料,另外定義getLineCount()與getTexts()兩個方法提供操作。目前沒有修改內容的需求,即使有也打算把資料對應到JtextArea物件在上面修改後再將內容更新回來。
PropertiesDataModelInterface是讀取properties檔案後的產出,其功能與JDK裡的Properties功能相同,整合到基本Data Model是為了資料讀寫的一致性以便適用在通用編輯器上。PropertiesParserActionAbstract針對這種類型的檔案,讀寫內容與資料物件同步。
這三種類型的檔案內容可謂基本型,因為儲存的格式與Data Model的格式全都有著一對一的對應。將不同格式的資料收集到同一種資料物件裡,意謂著繼承基本Data Model的所有資料物件都能夠用同樣的程式來處理。這種作法讓Data Model在根本上只存在一種唯一的類型,未來繼承出去的所有資料物件全部具有同樣的特性。
2009年3月26日 星期四
U10 第二個元件(1)──基本Data Model讀寫器
既然稱為基本Data Model,就是希望所有的資料都能夠存放在其中;基本Data Model已經提供存取的方法,接著要為幾種不同的資料類型定義不同的Data Model來對應。常用的基本種類有Text、Table(CSV & JXL)、Properties、XML,XML類型之下另再衍伸Bean、Obejct兩種類型,其繼承關係如下:

在XML Data Model系列裡,首先要支援xpath較重要的定義以便進行節點的搜尋;Bean Data Model的資料格式採用Hibernate通用的XML的定義方法,提供attributes與properties的屬性;Object Data Model則是依據Bean Data Model的class屬性,直接生成設定類別名稱的物件後可以直接轉換成該物件作處理(該物件須繼承自Bean Data Model)。
為了將檔案或字串的內容對應存取Data Model,需要設計對應不同類型的資料處理程式來達成,下圖是我預計支援的各種檔案類型、讀寫類別與Data Model之間的對應。在跨越swimming lane的關聯上都發生一對多或多對一的關係,因此在讀寫時傳入的參數必須各自傳入對應的參數作為識別。

在ModelInterface的功能需求上,目前要能夠從檔案存取、從字串存取與從URL存取,因此定義了對應的方法;另外根據不同的parser要能提供預設的Data Model也定義了對應的方法。(Exception的定義可能有所缺漏,這要到細部設計時才會收集到完整的集合)
public ModelInterface load(String filename, int type, ModelInterface model);
public ModelInterface load(URL url, int type, ModelInterface model);
public boolean save(String filename, int type, ModelInterface model) throws ModelParserExceptionDefault;
public ModelInterface loadString(String data, int type, ModelInterface model) throws ModelParserExceptionDefault;
public String saveString(ModelInterface model, int type) throws ModelParserExceptionDefault;
public ModelInterface getDefaultModel(int type);
在設計時需要根據傳入的parser type轉呼叫對應的程式方法,切換點放置在Implemention、Flow或Action都可以達成功能,然而依據設計原則決定將放在Flow並將Action繼承出各種不同的實作類型。
在XML Data Model系列裡,首先要支援xpath較重要的定義以便進行節點的搜尋;Bean Data Model的資料格式採用Hibernate通用的XML的定義方法,提供attributes與properties的屬性;Object Data Model則是依據Bean Data Model的class屬性,直接生成設定類別名稱的物件後可以直接轉換成該物件作處理(該物件須繼承自Bean Data Model)。
為了將檔案或字串的內容對應存取Data Model,需要設計對應不同類型的資料處理程式來達成,下圖是我預計支援的各種檔案類型、讀寫類別與Data Model之間的對應。在跨越swimming lane的關聯上都發生一對多或多對一的關係,因此在讀寫時傳入的參數必須各自傳入對應的參數作為識別。
在ModelInterface的功能需求上,目前要能夠從檔案存取、從字串存取與從URL存取,因此定義了對應的方法;另外根據不同的parser要能提供預設的Data Model也定義了對應的方法。(Exception的定義可能有所缺漏,這要到細部設計時才會收集到完整的集合)
public ModelInterface load(String filename, int type, ModelInterface model);
public ModelInterface load(URL url, int type, ModelInterface model);
public boolean save(String filename, int type, ModelInterface model) throws ModelParserExceptionDefault;
public ModelInterface loadString(String data, int type, ModelInterface model) throws ModelParserExceptionDefault;
public String saveString(ModelInterface model, int type) throws ModelParserExceptionDefault;
public ModelInterface getDefaultModel(int type);
在設計時需要根據傳入的parser type轉呼叫對應的程式方法,切換點放置在Implemention、Flow或Action都可以達成功能,然而依據設計原則決定將放在Flow並將Action繼承出各種不同的實作類型。
2009年3月24日 星期二
U09 基本Data Model的單元測試
針對ModelInterface裡列出的所有方法,都必須要作unit test。由於在ModelAbstract這層還不需要實作類別,所以另外準備了一個ModelAbstractTest類別作為測試用途。
同樣地在產生測試類別的同時,創建所有需要測試的方法並一一加以實作,測試的內容越多越詳細未來出問題的機率就越小。在測試setAttributes()時發現ListMap需要一個clone的方法,用來避免傳入的集合被ModelAbstract直接引用的問題。
以下是通過全部測試的結果圖。

同樣地在產生測試類別的同時,創建所有需要測試的方法並一一加以實作,測試的內容越多越詳細未來出問題的機率就越小。在測試setAttributes()時發現ListMap需要一個clone的方法,用來避免傳入的集合被ModelAbstract直接引用的問題。
以下是通過全部測試的結果圖。
2009年3月23日 星期一
U08 根本的建立(6)──基本Data Model
依據經驗,各種資料物件的最大集合是XML類型。它擁有name、value、comment、attributes、children等屬性,因此先以protected宣告這些屬性。其中attributes具有key-value的特性,在輸出時又得依序輸出,需要另外設計ListMap物件;children是放置其他data node的集合,為了保持順序而定義為List。
ListMap的實作其實就是同時將List與Map兩種集合包裝在一個物件裡,新增與刪除時都同時維護兩個集合。參考List與Map提供的方法定義好ListMap介面並加以實作完成;ListMap這個集合物件可以在很多時機使用的。(建構時允許指定物件的類別會更有彈性)
完成ListMap與ListMapImpl後,就可以進一步設計ModelInterface;由於這是最基本的Data Model,因此在這裡定義了所有可能的操作方法以應付所有可能的操作。不過沒法子根據需求來定義需要的方法而必須自己思考出全部的應用,會是設計底層物件較困難的地方。所有會變動內部資料的方法都要加上boolean的回傳值,提供呼叫者驗證結果是否成功,這要特別留意一下。
name、value、comment三者都僅是單一的物件,因此只需要提供最基本的getter、setter操作。attributes、chileren都是ListMap集合,對於集合就必須多考慮單一與整體的操作,至少需要以下的操作方法才能算是完整:
getWhole()
setWhole()
clearWhole()
getPartCount()
getPart()
addPart()
removePart()
參考以上方法定義好attributes與children的操作方法後,在ModelAbstract裡實作這些方法並在其中串連到ListMap的方法。
ListMap的實作其實就是同時將List與Map兩種集合包裝在一個物件裡,新增與刪除時都同時維護兩個集合。參考List與Map提供的方法定義好ListMap介面並加以實作完成;ListMap這個集合物件可以在很多時機使用的。(建構時允許指定物件的類別會更有彈性)
完成ListMap與ListMapImpl後,就可以進一步設計ModelInterface;由於這是最基本的Data Model,因此在這裡定義了所有可能的操作方法以應付所有可能的操作。不過沒法子根據需求來定義需要的方法而必須自己思考出全部的應用,會是設計底層物件較困難的地方。所有會變動內部資料的方法都要加上boolean的回傳值,提供呼叫者驗證結果是否成功,這要特別留意一下。
name、value、comment三者都僅是單一的物件,因此只需要提供最基本的getter、setter操作。attributes、chileren都是ListMap集合,對於集合就必須多考慮單一與整體的操作,至少需要以下的操作方法才能算是完整:
getWhole()
setWhole()
clearWhole()
getPartCount()
getPart()
addPart()
removePart()
參考以上方法定義好attributes與children的操作方法後,在ModelAbstract裡實作這些方法並在其中串連到ListMap的方法。
2009年3月20日 星期五
U07 元件結構調整與基本Properties名稱
目前元件結構有以下所列的三個調整:
元件用的常數拉出為獨立介面。雖然大家時常把常數與方法定義在同一個Interface裡,但是ApplLog只想使用LogUtil裡定義的常數時連方法也必須實作,因此將常數與方法切割為兩個Interface。實作時介面直接繼承後即可使用。不過這樣的繼承法雖然方便,卻也表示ApplLog與LogUtil已經緊密綁在一起,從意義上來看應該在ApplLog的常數Interface定義自己的記錄等級常數才對。(為了記錄等級的一致化,甚至要定義一個管理LogLevel的Class專門提供一致的記錄等級常數;這被定義為LogConstantInterface)
Flow與Action分工的界限。在ApplLog第一次設計時,Implementation、Flow與Action都定義同樣的一群方法直接從最外層呼叫進去,在Action裡才一次checkLogLevel()並呼叫LogUtil記錄,這種寫法可以達成目標,但完全不符合判斷流程要放在Flow的準則。在Flow與Action之間的流程與分解動作定義是設計時需要注重的部分。
Null Object的建立。由於ApplLog的Flow與Action並不是預設的名稱,最底層的基本Component在生成與使用時會發生NullPointException。加上一大堆判斷物件是否為null的程式看起來很沒效率,因而在無法生成物件時一律生成該物件名稱的Null Object。Null Object需要實作該介面的所有方法,但完全沒有任何處理而直接回傳正確的結果;如此一來會使程式碼簡潔許多。
在Root Component這層共有四個可定義的參數:
public final static String CLASS_MODEL = "classModel";
public final static String CLASS_FLOW = "classFlow";
public final static String CLASS_ACTION = "classAction";
public final static String LOG_LEVEL = "logLevel";
元件用的常數拉出為獨立介面。雖然大家時常把常數與方法定義在同一個Interface裡,但是ApplLog只想使用LogUtil裡定義的常數時連方法也必須實作,因此將常數與方法切割為兩個Interface。實作時介面直接繼承後即可使用。不過這樣的繼承法雖然方便,卻也表示ApplLog與LogUtil已經緊密綁在一起,從意義上來看應該在ApplLog的常數Interface定義自己的記錄等級常數才對。(為了記錄等級的一致化,甚至要定義一個管理LogLevel的Class專門提供一致的記錄等級常數;這被定義為LogConstantInterface)
Flow與Action分工的界限。在ApplLog第一次設計時,Implementation、Flow與Action都定義同樣的一群方法直接從最外層呼叫進去,在Action裡才一次checkLogLevel()並呼叫LogUtil記錄,這種寫法可以達成目標,但完全不符合判斷流程要放在Flow的準則。在Flow與Action之間的流程與分解動作定義是設計時需要注重的部分。
Null Object的建立。由於ApplLog的Flow與Action並不是預設的名稱,最底層的基本Component在生成與使用時會發生NullPointException。加上一大堆判斷物件是否為null的程式看起來很沒效率,因而在無法生成物件時一律生成該物件名稱的Null Object。Null Object需要實作該介面的所有方法,但完全沒有任何處理而直接回傳正確的結果;如此一來會使程式碼簡潔許多。
在Root Component這層共有四個可定義的參數:
public final static String CLASS_MODEL = "classModel";
public final static String CLASS_FLOW = "classFlow";
public final static String CLASS_ACTION = "classAction";
public final static String LOG_LEVEL = "logLevel";
2009年3月15日 星期日
U06 第一個元件(3)──Log記錄器的單元測試
Log記錄器的單元測試著重在這幾個項目:LogUtil所有層級的記錄功能、ApplLog所有層級的記錄功能、ApplLog設定不同的層級時是否能過濾掉不應有記錄的層級。Log提供的方法沒法驗證是否正確,因此在測試之後就只能在console與記錄檔案裡確認結果。
先寫好兩個使用ApplLog方式記錄trace、debug、info、warn、error、fatal六個層級的方法,一個只傳入message而另一個可傳入message與trhowable;測試時先記錄一行現在的等級,於設定ApplLog之後再呼叫記錄所有層級的方法,最後檢視螢幕的輸出與檔案的輸出入容是否正確。

元件庫現在的結構圖:

先寫好兩個使用ApplLog方式記錄trace、debug、info、warn、error、fatal六個層級的方法,一個只傳入message而另一個可傳入message與trhowable;測試時先記錄一行現在的等級,於設定ApplLog之後再呼叫記錄所有層級的方法,最後檢視螢幕的輸出與檔案的輸出入容是否正確。
元件庫現在的結構圖:
2009年3月13日 星期五
U05 第一個元件(2)──Log記錄器
ApplLog是處理所有元件Log記錄的底層元件,執行ComponentUtilUI以下圖的數據建立ApplLog。

ApplLog不需要Model與Exception兩個部分,所以刪除相關檔案。在ApplLogInterface定義所有提供給外部操作的log方法,在ApplLogConstantInterface定義各種等級的常數;常數與方法會分開成兩個Interface的原因在於繼承時會有只使用常數與使用常數加方法的不同需要。
ApplLogImplAbstract裡實作Interface的所有方法都轉呼叫Flow內同樣的方法,並且要在呼叫前後包裝beforeInvoke()、afterInvoke()。
public void trace(ComponentImplInterface impl, Object message) {
beforeInvoke();
getApplLogFlow().trace(impl, message);
afterInvoke();
}
ApplLogFlowAbstract要做的是判斷要記錄的等級是否小於等於規定的等級,然後呼叫ApplLogActionAbstract的動作。在這兩層裡的設計結果有許多不同的組合,最後使用最趨近設計準則的結果:Action提供整合的的記錄方法在內部轉呼叫LogUtil的各個方法,Flow呼叫檢查等級方法於需要記錄時傳入現有等級到Action的整合方法。
最後將實作Class名稱中的Default拿掉使之容易記憶使用,需要記錄log時呼叫ApplLog.getInstance()取得元件物件後即可呼叫所有等級的方法。

ApplLog不需要Model與Exception兩個部分,所以刪除相關檔案。在ApplLogInterface定義所有提供給外部操作的log方法,在ApplLogConstantInterface定義各種等級的常數;常數與方法會分開成兩個Interface的原因在於繼承時會有只使用常數與使用常數加方法的不同需要。
ApplLogImplAbstract裡實作Interface的所有方法都轉呼叫Flow內同樣的方法,並且要在呼叫前後包裝beforeInvoke()、afterInvoke()。
public void trace(ComponentImplInterface impl, Object message) {
beforeInvoke();
getApplLogFlow().trace(impl, message);
afterInvoke();
}
ApplLogFlowAbstract要做的是判斷要記錄的等級是否小於等於規定的等級,然後呼叫ApplLogActionAbstract的動作。在這兩層裡的設計結果有許多不同的組合,最後使用最趨近設計準則的結果:Action提供整合的的記錄方法在內部轉呼叫LogUtil的各個方法,Flow呼叫檢查等級方法於需要記錄時傳入現有等級到Action的整合方法。
最後將實作Class名稱中的Default拿掉使之容易記憶使用,需要記錄log時呼叫ApplLog.getInstance()取得元件物件後即可呼叫所有等級的方法。
2009年3月12日 星期四
U04 第一個元件(1)──Log記錄器
第一個需要製作的元件就是提供診斷系統參考使用的Log記錄器。在一般的作法裡Log大多只是一個定義許多static method的Class,在需要留下記錄字串的時候呼叫對應的方法。這樣的作法很方便使用,同時記錄的等級可以在設定檔裡修改。
但是系統開發到某個程度後需要減少Log記錄,這個時候由於只能更換整個系統的等級,就形成要一個一個檢查哪些記錄該刪或該留,當發生問題要多記錄或是穩定後減少記錄需要再調整特定部分記錄等級時又要再全部檢查一遍。如此花費很多時間卻又得不到精確的結果,並不是時程緊迫的專案所能接受的作法。設計Log記錄器元件,一方面提供一般程式現行的直接記錄作法,另一方面提供每一個元件都能夠定義各自的記錄等級。
首先要製作最底層的LogUtil物件,內部包裝真正執行記錄的外部物件,而且定義了LogUtilInterface準備供給Log元件依記錄等級呼叫。Interface裡有直接對應到底層實作log方法(沒任何加工,只是直接轉呼叫),這是提供非元件類別呼叫使用的。依記錄等級定義了trace()、debug()、info()、warn()、debug()與fatal()六種方法。
在記錄元件的功能規畫裡,記錄等級不是依賴log自有的設定檔,而是從Properties裡取得預設的log層級;另外元件各自的Properties裡可以定義該元件的Log Level,其設定會優先於LogUtil裡的預設值而影響記錄內容。log level相關的屬性及存取方法都定義在Root Component層級,讓所有的Component的記錄都具有隨時從設定檔切換不同等級的功能。

但是系統開發到某個程度後需要減少Log記錄,這個時候由於只能更換整個系統的等級,就形成要一個一個檢查哪些記錄該刪或該留,當發生問題要多記錄或是穩定後減少記錄需要再調整特定部分記錄等級時又要再全部檢查一遍。如此花費很多時間卻又得不到精確的結果,並不是時程緊迫的專案所能接受的作法。設計Log記錄器元件,一方面提供一般程式現行的直接記錄作法,另一方面提供每一個元件都能夠定義各自的記錄等級。
首先要製作最底層的LogUtil物件,內部包裝真正執行記錄的外部物件,而且定義了LogUtilInterface準備供給Log元件依記錄等級呼叫。Interface裡有直接對應到底層實作log方法(沒任何加工,只是直接轉呼叫),這是提供非元件類別呼叫使用的。依記錄等級定義了trace()、debug()、info()、warn()、debug()與fatal()六種方法。
在記錄元件的功能規畫裡,記錄等級不是依賴log自有的設定檔,而是從Properties裡取得預設的log層級;另外元件各自的Properties裡可以定義該元件的Log Level,其設定會優先於LogUtil裡的預設值而影響記錄內容。log level相關的屬性及存取方法都定義在Root Component層級,讓所有的Component的記錄都具有隨時從設定檔切換不同等級的功能。
2009年3月9日 星期一
U03 根本的建立(5)──建立Component使用的Class
在根本Package之下放置了Model、Propeties與Exception三種Class供Component相同意義的部分使用,為什麼不使用JDK的物件而要自己定義一組,這是來自避震器的觀念。將自己額外的需要寫在建構在中間的物件,同時可以集中吸收未來底層物件的改變。
Object
如果要確切地分割,應該要建立自己的Object Class。不過還沒有非得這麼做不可的理由,所以沒有建立。
Model
基本的Data Model會採用類似XML Node的定義,會有name、value、comment、attributes、children等等的屬性,每個屬性都提供getter與setter方法。(後面會說明作法)
Properties
繼承JDK的Properties物件,使用原有的功能。(在Model實作完成後會更換為Model物件,之後會說明)
Exception
繼承JDK的Exception物件,使用原有的功能。
Log與結構無關的獨立功能,目的是要產出記錄提供除錯、查看或分析用途。會是一個獨立的Component。(後面會說明作法)
Object
如果要確切地分割,應該要建立自己的Object Class。不過還沒有非得這麼做不可的理由,所以沒有建立。
Model
基本的Data Model會採用類似XML Node的定義,會有name、value、comment、attributes、children等等的屬性,每個屬性都提供getter與setter方法。(後面會說明作法)
Properties
繼承JDK的Properties物件,使用原有的功能。(在Model實作完成後會更換為Model物件,之後會說明)
Exception
繼承JDK的Exception物件,使用原有的功能。
Log與結構無關的獨立功能,目的是要產出記錄提供除錯、查看或分析用途。會是一個獨立的Component。(後面會說明作法)
2009年3月6日 星期五
U02 Project的佈置問題
經手維護的產品是Client-Server架構的,在初期的規劃裡只在垂直層面切割Project,Client與Server的程式則放置在同一層的Project裡。在專案裡的Client程式是由Server派送的,客戶總會抱怨為什麼改Client程式為什麼連Server的東西也要下傳?這就是因為對應的意義不同而取用到不需要的東西。
後來將程式碼分割為Client與Server兩個Project,終於解決了客戶在意的流量問題,但是在這樣的佈置下發現Client與Server間共用的程式碼在兩邊都各有一份,久而久之又爆發了程式碼不一致的狀況。最終再把共用程式碼抽取到另一個Client+Server Project後終於解決了這些問題。
公司另外有一個週邊管理程式,程式碼與建立安裝的環境放置在device這一個Project裡,初期能夠應付所有的需要而沒發現有什麼不對。後來在其他專案需求裡的週邊需要調整程式碼的架構寫法,那是與之前設計有不相容之處的,結果只好複製成兩個Project各自維護。在這個案例中可以發現,環境設定應該另外放置在一個Project裡。
Project的佈置也必須根據其存在的意義(使用意義、使用場所)加以設計,以免因為意義的混淆而多出了許多額外的東西造成負擔。同時也要建立Project的使用關聯作為追溯之用。
後來將程式碼分割為Client與Server兩個Project,終於解決了客戶在意的流量問題,但是在這樣的佈置下發現Client與Server間共用的程式碼在兩邊都各有一份,久而久之又爆發了程式碼不一致的狀況。最終再把共用程式碼抽取到另一個Client+Server Project後終於解決了這些問題。
公司另外有一個週邊管理程式,程式碼與建立安裝的環境放置在device這一個Project裡,初期能夠應付所有的需要而沒發現有什麼不對。後來在其他專案需求裡的週邊需要調整程式碼的架構寫法,那是與之前設計有不相容之處的,結果只好複製成兩個Project各自維護。在這個案例中可以發現,環境設定應該另外放置在一個Project裡。
Project的佈置也必須根據其存在的意義(使用意義、使用場所)加以設計,以免因為意義的混淆而多出了許多額外的東西造成負擔。同時也要建立Project的使用關聯作為追溯之用。
訂閱:
文章 (Atom)



{kind=link}